Mybatisplus3.5.1+shardingsphere-jdbc5.1.1分表
Posted 隔壁老郭的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatisplus3.5.1+shardingsphere-jdbc5.1.1分表相关的知识,希望对你有一定的参考价值。
注意使用雪花ID的话,查询ID时候必须使用long类型的ID,不要使用MP自带的默认的Serializable类型。否则会提示分片主键id数据类型和分片算法不匹配Inline sharding algorithms expression
xxxand sharding columnxxnot match错误。。。
导入依赖
<!--sharding-jdbc 分库分表-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!--Mybatis-plus 代码生成器-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>$mybatisplus.verison</version>
</dependency>
建立10张表
CREATE TABLE `sharding_jdbc_0` (
`shading_table_id` bigint(22) NOT NULL COMMENT \'ID\',
`name` varchar(50) DEFAULT NULL COMMENT \'名称\',
`state` int(2) DEFAULT \'1\' COMMENT \'状态:1有效0无效\',
`create_time` datetime DEFAULT NULL COMMENT \'创建时间\',
`user_id` bigint(22) DEFAULT NULL COMMENT \'用户ID\',
PRIMARY KEY (`shading_table_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_jdbc_1` (
`shading_table_id` bigint(22) NOT NULL COMMENT \'ID\',
`name` varchar(50) DEFAULT NULL COMMENT \'名称\',
`state` int(2) DEFAULT \'1\' COMMENT \'状态:1有效0无效\',
`create_time` datetime DEFAULT NULL COMMENT \'创建时间\',
`user_id` bigint(22) DEFAULT NULL COMMENT \'用户ID\',
PRIMARY KEY (`shading_table_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
.........省略其他表。。。。。。。。
mybatisplus的配置
mybatis-plus:
type-aliases-package: com.gton.user.entity
mapper-locations: classpath*:com/gton/user/mapper/xml/*Mapper.xml
configuration:
map-underscore-to-camel-case: true #开启驼峰命名
cache-enabled: false #开启二级缓存
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 控制台日志
check-config-location: true # 检查xml是否存在
type-enums-package: com.gton.enumPackage #通用枚举开启
global-config:
db-config:
logic-not-delete-value: 1
logic-delete-field: isDel
logic-delete-value: 0
ShardingJDBC的配置
注意yml的配置格式严格要求,错一个空格都不行
spring:
shardingsphere:
datasource:
names: masterdb,ds02
masterdb:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
# 正常的连接数据库
url: jdbc:mysql://127.0.0.1:3306/study?zeroDateTimeBehavior=convertToNull&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
ds02:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
# 正常的连接数据库
url: jdbc:mysql://127.0.0.1:3306/study?zeroDateTimeBehavior=convertToNull&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
props:
# 日志显示SQL
sql.show: true
rules:
sharding:
# 表的分片策略
tables:
# 逻辑表的名称
sharding_jdbc:
# 数据节点配置,采用Groovy表达式
actual-data-nodes: masterdb.sharding_jdbc_$->0..9
# 配置策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
sharding-column: shading_table_id
# 分片算法名字
sharding-algorithm-name: use-inline
key-generate-strategy: # 主键生成策略
column: shading_table_id # 主键列
key-generator-name: snowflake # 策略算法名称(推荐使用雪花算法)
key-generators:
snowflake:
type: SNOWFLAKE
sharding-algorithms:
use-inline:
type: INLINE
props:
# 分片算法行表达式,需符合groovy语法 \'& Integer.MAX_VALUE\' 位运算使hash值为正数, 取模运算
# algorithm-expression: sharding_jdbc_$->(id.hashCode() & Integer.MAX_VALUE) % 9
# 获取id取模范围为0-10, 包含0, 不包含10
algorithm-expression: sharding_jdbc_$->shading_table_id % 10
mode:
type: memory
实体类
/**
* (ShardingJdbc1)表实体类
*
* @author 郭童
* @since 2023-05-20 14:58:06
*/
@Data
@Accessors(chain = true)
@ApiModel(value = "ShardingJdbc1", description = "EasyCode")
public class ShardingJdbc implements Serializable
private static final long serialVersionUID = 1L;
@TableId(type = IdType.ASSIGN_ID)
@ApiModelProperty("ID")
private Long shadingTableId;
@TableField(value = "name")
@ApiModelProperty("名称")
private String name;
@TableField(value = "state")
@ApiModelProperty("状态:1有效0无效")
private Integer state;
@TableField(value = "create_time", fill = FieldFill.INSERT)
@ApiModelProperty("创建时间")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
@TableField(value = "user_id")
@ApiModelProperty("用户ID")
private Long userId;
Mapper的接口
/**
* (ShardingJdbc1)表数据库访问层
*
* @author 郭童
* @since 2023-05-20 14:58:06
*/
@Mapper
public interface ShardingJdbcMapper extends EasyBaseMapper<ShardingJdbc>
/**
* @description: EasyBaseMapper<T> extends BaseMapper<T>
* @author: GuoTong
* @createTime: 2022-12-06 16:29
* @since JDK 1.8 OR 11
**/
public interface EasyBaseMapper<T> extends BaseMapper<T>
/**
* 批量插入 仅适用于mysql
*
* @param entityList 实体列表
* @return 影响行数
*/
Integer insertBatchSomeColumn(Collection<T> entityList);
其余的三层就不一一赘述了!!!!各种MP的代码生成器!!执行解决!!推荐EasyCode全自动代码生成器,配好就很好使。。。我的其他文章介绍使用。。。
Controller的新增和查询
/**
* 通过主键查询单条数据
*
* @param id 主键
* @return 单条数据
*/
@GetMapping("/queryOne/id")
public Resp<ShardingJdbc> selectOne(@PathVariable("id") Long id)
QueryWrapper<ShardingJdbc> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("shading_table_id", id);
return Resp.Ok(this.shardingJdbcService.getOne(queryWrapper));
/**
* 新增数据
*
* @param shardingJdbc 实体对象
* @return 新增结果
*/
@PostMapping("/save")
public Resp<String> insert(@RequestBody ShardingJdbc shardingJdbc)
boolean save = false;
String executeMsg = null;
try
save = this.shardingJdbcService.save(shardingJdbc);
executeMsg = "新增成功,id 是:" + shardingJdbc.getShadingTableId();
catch (Exception e)
executeMsg = e.getMessage();
return save ? Resp.Ok(executeMsg) : Resp.error(executeMsg);
测试效果!!
新增
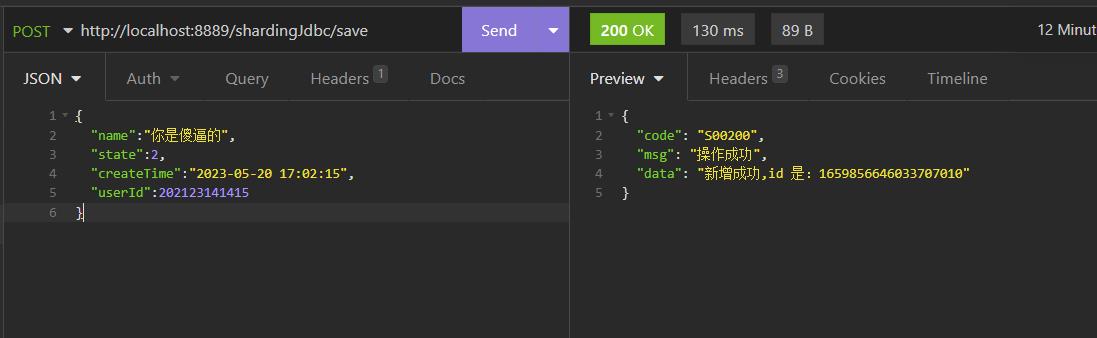
查询

捯饬结束!!!!!整合成功!!!
----------隔壁老郭还有大号:隔壁老郭---------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!
SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表实践
一、序言
在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量。当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术。
本文将基于SpringBoot+MybatisPlus+Sharding-JDBC+Mysql实现企业级分库分表。
1、组件及版本选择
 |
 |
 |
 |
|---|---|---|---|
| SpringBoot 2.6.x | MybatisPlus 3.5.0 | Sharding-JDBC 4.1.1 | Mysql 5.7.35 |
2、预期目标
- 使用上述组件实现分库分表,简化起见只讨论分表技术
- 完成分表后的逻辑表与物理表间的增删查改
- 引入逻辑删除和使用MybatisPlus内置分页技术
完整项目源码访问地址。
二、代码实现
为了简化分表复杂性,专注于分表整体实现,简化分表逻辑:按照UserId的奇偶属性分别进行分表。以订单表这一典型场景为例,一般来说有关订单表,通常具有如下共性行为:
- 创建订单记录
- 查询XX用户的订单列表
- 查询XX用户的订单列表(分页)
- 查询XX订单详情
- 修改订单状态
- 删除订单(逻辑删除)
接下来通过代码实现上述目标。
(一)素材准备
1、实体类
@Data
@TableName("bu_order")
public class Order
@TableId
private Long orderId;
private Integer orderType;
private Long userId;
private Double amount;
private Integer orderStatus;
@TableLogic
@JsonIgnore
private Boolean deleted;
2、Mapper类
@Mapper
public interface OrderMapper extends BaseMapper<Order>
3、全局配置文件
spring:
config:
use-legacy-processing: true
shardingsphere:
datasource:
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/sharding-jdbc2?serverTimezone=UTC
username: root
password: 123456
names: ds1
props:
sql:
show: true
sharding:
tables:
bu_order:
actual-data-nodes: ds1.bu_order_$->0..1
key-generator:
column: order_id
type: SNOWFLAKE
table-strategy:
inline:
algorithm-expression: bu_order_$user_id%2
sharding-column: user_id(二)增删查改
1、保存数据
由于依据主键的奇偶属性对原表分表,分表后每张表的数据量是分表前的二分之一。根据需要也可以自定义分表数量(比如10张),新分表后的数据量是不分表前的十分之一。
@Test
public void addOrders()
for (long i = 1; i <= 10; i++)
Order order = new Order();
order.setOrderId(i);
order.setOrderType(RandomUtil.randomEle(Arrays.asList(1, 2)));
order.setUserId(RandomUtil.randomEle(Arrays.asList(101L, 102L, 103L)));
order.setAmount(1000.0 * i);
orderMapper.insert(order);
2、查询列表数据
查询指定用户的订单列表。
@GetMapping("/list")
public AjaxResult list(Order order)
LambdaQueryWrapper<Order> wrapper = Wrappers.lambdaQuery(order);
return AjaxResult.success(orderMapper.selectList(wrapper));
3、分页查询数据
分页查询指定用户的订单列表
@GetMapping("/page")
public AjaxResult page(Page<Order> page, Order order)
return AjaxResult.success(orderMapper.selectPage(page, Wrappers.lambdaQuery(order)));
4、查询详情
通过订单ID查询订单详情。
@GetMapping("/detail/orderId")
public AjaxResult detail(@PathVariable Long orderId)
return AjaxResult.success(orderMapper.selectById(orderId));
5、删除数据
通过订单ID删除订单(逻辑删除)
@DeleteMapping("/delete/orderId")
public AjaxResult delete(@PathVariable Long orderId)
return AjaxResult.success(orderMapper.deleteById(orderId));
6、修改数据
修改数据一般涉及部分列,比如修改订单表的订单状态等。
@PutMapping("/edit")
public AjaxResult edit(@RequestBody Order order)
return AjaxResult.success(orderMapper.updateById(order));
三、理论分析
1、选择分片列
选择分片列是经过精心对比后确定的,对于订单类场景,需要频繁以用户ID为查询条件筛选数据,因此将同一个用户的订单数据存放在一起有利于提高查询效率。
2、扩容
当分表后的表数据快速增长,可以预见即将达到瓶颈时,需要对分表进行扩容,扩容以2倍的速率进行,扩容期间需要迁移数据,工作量相对可控。
以上是关于Mybatisplus3.5.1+shardingsphere-jdbc5.1.1分表的主要内容,如果未能解决你的问题,请参考以下文章
视点sharding is coming,到底什么是sharding?
免费直播 | Sharding-Jdbc姊妹篇之Sharding-Proxy
Elasticsearch 基于磁盘的shard分配机制浅析