基于VictoriaMetrics的大规模监控实战
Posted 明天OoO你好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于VictoriaMetrics的大规模监控实战相关的知识,希望对你有一定的参考价值。
https://zahui.fan/posts/0cebb8ae/
victoriametrics原生支持水平扩展,并且大部分兼容Prometheus语法,官方文档地址:https://docs.victoriametrics.com/
这个是victoriametrics官方的集群架构
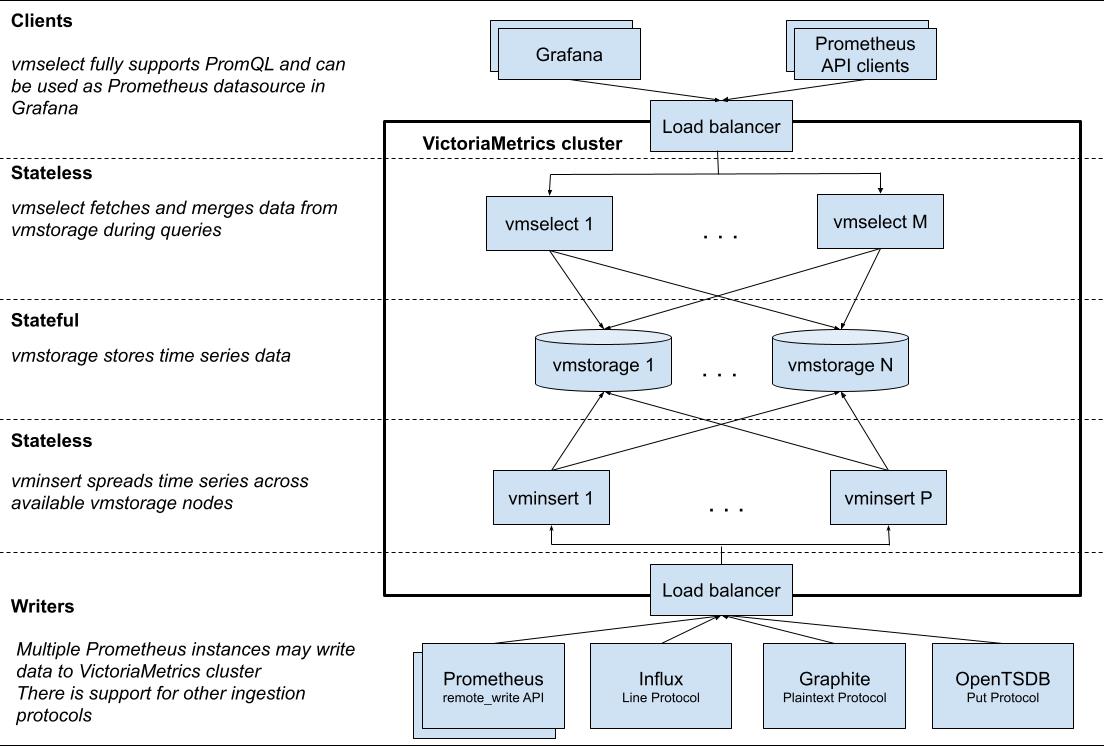
我公司用到的集群架构
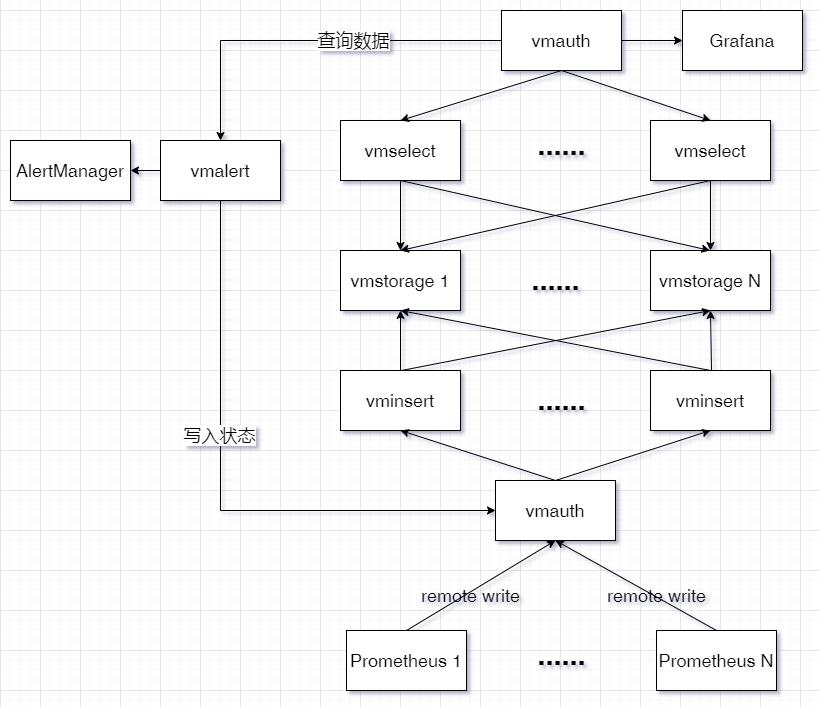
目前用到3台机器
| IP | 部署的服务 |
|---|---|
| 10.200.4.74 | vmauth、vmselect、vminsert、vmstorage、vmalert |
| 10.200.4.75 | vmselect、vminsert、vmstorage |
| 10.200.4.76 | vmselect、vminsert、vmstorage |
vmstorage
首先需要把存储部署上,多个存储之间数据是不同步的,也就是说所有的storege组件之间是感知不到彼此的。通过vmselect和vminsert采用一致性hash算法来确定读取/写入哪台节点。
vmstorage启动命令
1
|
./vmstorage-prod -httpListenAddr "0.0.0.0:8482" \\ # vmstorage监听端口
|
vminsert
1
|
./vminsert-prod -httpListenAddr "0.0.0.0:8480" \\
|
vmselect
vmselect启动命令
1
|
./vmselect-prod -httpListenAddr "0.0.0.0:8481" \\
|
vmalert
1
|
./vmalert-prod -rule=./rules/* \\ # 告警规则目录
|
负载均衡配置
vmauth负载均衡配置
1
|
./vmauth-prod -auth.config=./vmauth.yml
|
其中vmauth.yml的配置
1
|
users:
|
nginx负载均衡配置
如果你不想用vmauth,nginx功能可以完全覆盖vmauth
nginx配置示例:
1
|
upstream vmselect
|
.htpasswd文件格式:
1
|
admin:$1$QYnl4A1Q$I8Q712.eKtG9m7sAb9oeM1
|
admin是用户名, :后面的是密码, 密码可以使用
openssl passwd -1 123456来生成(假设原始密码是123456)
常用的配置
Prometheus通过remote_write写入vm集群
官方文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
1
|
remote_write:
|
参数说明:
-
capacity
定义:每个内存队列(shard:分片)的容量。
一旦WAL被阻塞,就无法将样本附加到任何分片,并且所有吞吐量都将停止。所以在大多数情况下,单个队列容量应足够打以避免阻塞其他分片,但是太大的容量可能会导致过多的内存消耗,并导致重新分片期间清除队列的时间更长。
容量建议:将容量设置为3-10倍
max_samples_per_send -
max_shards
顾名思义,最大的分片数(即队列数),也可以理解为远程写的并行度。peometheus远程写的时候会使用所有的分片,只有在写队列落后于远程写的速度,使用的队列数会达到max_shards,目的在于提高远程写的吞吐量。
PS:在操作过程中,Prometheus将根据传入的采样率,未发送的未处理样本数以及发送每个样本所花费的时间,连续计算要使用的最佳分片数。(实际的分片数是动态调整的)
-
min_shards
最小分片配置Prometheus使用的最小分片数量,并且是远程写入开始时使用的分片数量。如果远程写入落后,Prometheus将自动扩大分片的数量,因此大多数用户不必调整此参数。但是,增加最小分片数将使Prometheus在计算所需分片数时避免在一开始就落后。
-
max_samples_per_send
定义:每次远程写发送的最大指标数量,即批处理;
这个值依赖于远程存储系统,对于一些系统而言,在没有显著增加延迟的情况下发送更多指标数据而运行良好,然而,对于另外一些系统而言,每次请求中发送大量指标数据可能导致其出现故障,使用的默认值是适用于绝大多数系统的。
-
batch_send_deadline
定义:单一分片批量发送指标数据的最大等待时间;
即使排队的分片尚未达到max_samples_per_send,也会发送请求。 对于对延迟不敏感的小批量系统,可以增加批量发送的截止时间,以提高请求效率。
-
min_backoff
定义:远程写失败的最小等待时间;
min_backoff是第一次的重试等待时间,第二次等待时间是其2倍,以此类推,直到max_backoff的值;
-
max_backoff
定义:远程写失败的最大等待时间;
Grafana直接查询VM集群
Grafana配置地址:
| 说明 | 地址 |
|---|---|
| 负载均衡地址 | http://10.200.4.74:8000 |
| vmselect地址 | http://10.200.4.74:8481/select/0/prometheus |
其他API地址
目录:http://10.200.4.74:8481/select/0/
vmui:http://10.200.4.74:8481/select/0/vmui/
每个组件都有/metrics,可以接入监控
使用 VictoriaMetrics 监控 K8s 集群
以上是关于基于VictoriaMetrics的大规模监控实战的主要内容,如果未能解决你的问题,请参考以下文章