Python:爬虫助你回家,12306余票监测!
Posted 520lmx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python:爬虫助你回家,12306余票监测!相关的知识,希望对你有一定的参考价值。

写在前面
一年一度的春运即将来临,各位看官回家的票有没有买好呢?反正小编已经按捺不住激动的心情,开始蠢蠢欲动了。但是作为技术控,就应该有技术控的抢票姿态,鉴于12306逆天的验证码,小编放弃了控制12306自动抢票的骚操作,开始走向自动余票提醒:有余票=>微信推送余票信息的道路。
正文

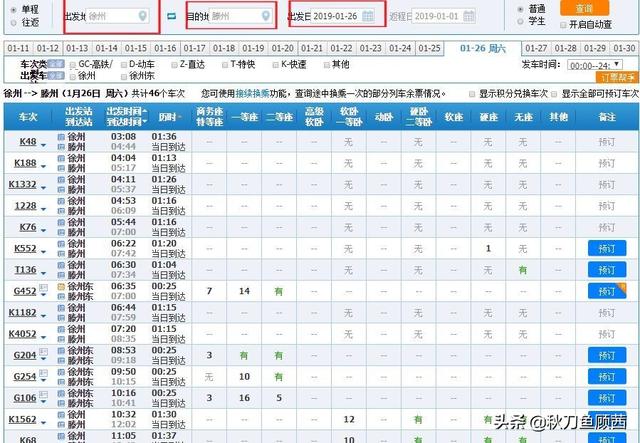
以徐州到滕州为例,我们想爬取1月26号的余票信息,登录12306官网查询余票页面(https://kyfw.12306.cn/otn/leftTicket/init),在下图所示的红框内输入出发地、目的地以及出发日期。
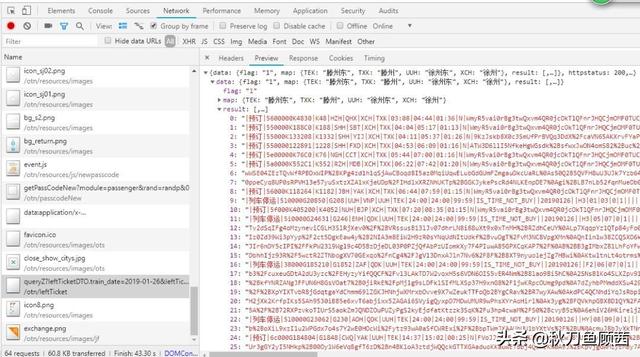
由于余票信息是异步加载的,我们需要通过谷歌浏览器开发者工具找到中间请求的URL,可以发现我们需要的信息就在
https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-14&leftTicketDTO.from_station=XCH&leftTicketDTO.to_station=TXK&purpose_codes=ADULT 下的result里面。
下面我们运用selenium库驱动PhantomJS来获取网页源码信息,其中selenium是一个自动化测试工具,大家可以通过pip install下载安装。利用它可以驱动浏览器执行特定动作,同时还可以获取浏览器当前呈现的源码,做到“可见可爬”,回避了各种反爬措施。最近小编在学习这个库,所以暂且用它牛刀小试一下。由于selenium不自带浏览器,所以我们这里选择小巧的无界面浏览器PhantomJS
首先介绍一下,所需要加载的模块。
Selenium库:模拟浏览器运行的库。
Pandas库:Python科学计算库。
Json库:解析JSON后将其转为Python字典或者列表。
Wxpy库:可用来实现各种个人微信号的自动化操作,我们这里用来实现微信自动发送余票信息。
time模块: Python标准库中的模块,用来实现时间间隔控制,循环获得余票信息。
加载程序如下:
fromselenium importwebdriver
importpandas aspd
importjson
importnumpy asnp
fromwxpy import*
importtime
下面开始进入正题,第一步爬取余票信息,还是以徐州到滕州为例。首先获取网页源码,程序如下:
driver = webdriver.PhantomJS( ‘D:webdriverphantomjs-2.1.1-windowsbinphantomjs.exe‘)
#phantomjs所在位置
url= ‘https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=‘+ ‘2019-01-14‘+ ‘&leftTicketDTO.from_station=‘+ ‘XCH‘+ ‘&leftTicketDTO.to_station=‘+ ‘TXK‘+ ‘&purpose_codes=ADULT‘
driver.get(url)html=driver.page_sourcedriver.quit() #关闭phantomjs
最终获取的文本信息如下:
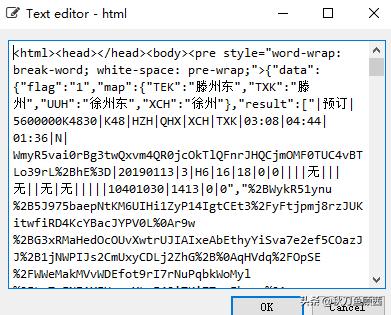
可以发现,我们需要的信息以json数据的形式存在,把网页的标签删除,就可以直接将json数据转换成字典的形式。程序如下:
html = html.replace( ‘‘‘<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">‘‘‘, ‘‘) .replace( ‘</pre></body></html>‘, ‘‘) #删除网页标签信息
html=json.loads(html) #剩下的网页源码是json数据,json.loads将json格式数据转换为字典
这样就把网页的信息,存储到了名为html的字典中,而余票信息(即上面原网页的表格内容)就被已列表的形式,存在了result中。
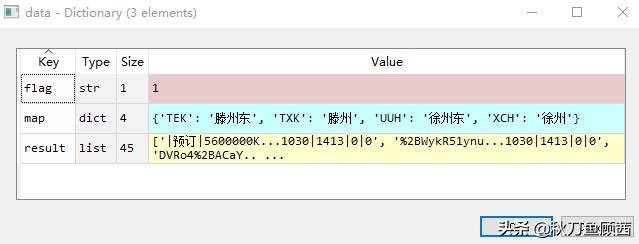
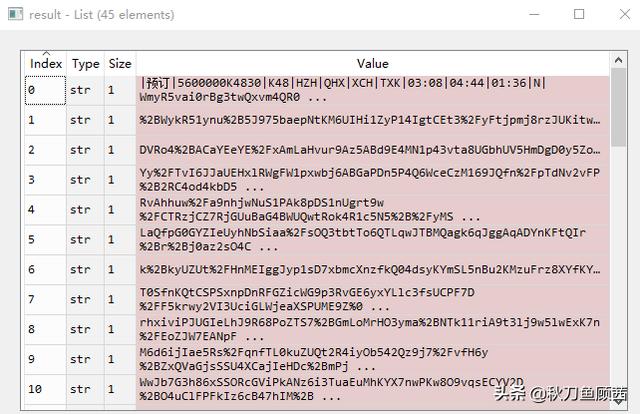
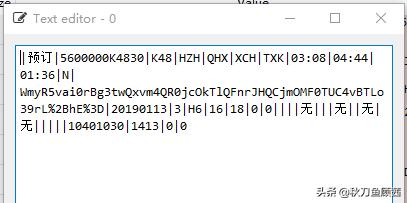
自然,我们接下来需要做的就是将余票信息从result中提取出来。通过观察上图能发现,车次信息清晰地用“|”分隔开,这里就可以通过split函数将字符串分割,再根据信息位置,提取我们需要的信息。
程序如下:
data={
‘车次‘: ‘‘,
‘始发站‘: ‘‘,
‘终点站‘: ‘‘,
‘出发时间‘: ‘‘,
‘到达时间‘: ‘‘,
‘全程时间‘: ‘‘,
‘商务座‘: ‘‘,
‘一等座‘: ‘‘,
‘二等座‘: ‘‘,
‘高级软卧‘: ‘‘,
‘软卧‘: ‘‘,
‘动卧‘: ‘‘,
‘硬卧‘: ‘‘,
‘软座‘: ‘‘,
‘硬座‘: ‘‘,
‘无座‘: ‘‘} #生成一个空的字典,将我们需要的数据信息定义为键名
result=pd.DataFrame(data,index=[ 0]) #将字典转成一个dataframe,方便数据处理
fori inhtml[ ‘data‘][ ‘result‘]: #我们需要的数据在html字典键名为result中
?item = i.split( ‘|‘) #用"|"进行分割data[ ‘车次‘] = item[ 3] #车次在3号位置data[ ‘始发站‘] = item[ 6] #始发站信息在6号位置data[ ‘终点站‘] = item[ 7] #终点站信息在7号位置data[ ‘出发时间‘] = item[ 8] #出发时间信息在8号位置data[ ‘到达时间‘] = item[ 9] #抵达时间在9号位置data[ ‘全程时间‘] = item[ 10] #经历时间在10号位置data[ ‘商务座‘] = item[ 32] oritem[ 25] # 特别注意:商务座在32或25位置data[ ‘一等座‘] = item[ 31] #一等座信息在31号位置data[ ‘二等座‘] = item[ 30] #二等座信息在30号位置data[ ‘高级软卧‘] = item[ 21] #高级软卧信息在31号位置data[ ‘软卧‘] = item[ 23] #软卧信息在23号位置data[ ‘动卧‘] = item[ 27] #动卧信息在27号位置data[ ‘硬卧‘] = item[ 28] #硬卧信息在28号位置data[ ‘软座‘] = item[ 24] #软座信息在24号位置data[ ‘硬座‘] = item[ 29] #硬座信息在29号位置data[ ‘无座‘] = item[ 26] #无座信息在26号位置df1=pd.DataFrame(data,index=[ 0]) #将赋值后的字典转换成datafram,命名为df1frames=[result,df1] #result,df1构成一个列表,再使用concatresult = pd.concat(frames,axis= 0, ignore_index= True) #将两个列表按行合并,然后冲着索引
columns=[ ‘车次‘, ‘始发站‘, ‘终点站‘, ‘出发时间‘, ‘到达时间‘, ‘商务座‘, ‘一等座‘, ‘二等座‘, ‘高级软卧‘, ‘软卧‘, ‘动卧‘, ‘硬卧‘, ‘软座‘, ‘硬座‘, ‘无座‘]result=result.reindex(columns=columns) #将result的列名按columns排列,我们想先看到车次和时间嘛.
通过数据清洗,原网页表格信息就规整的放到了名为result的dataframe中。如下图所示:
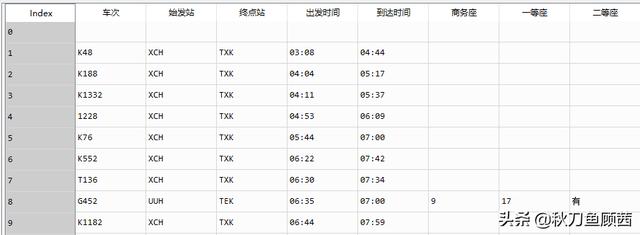
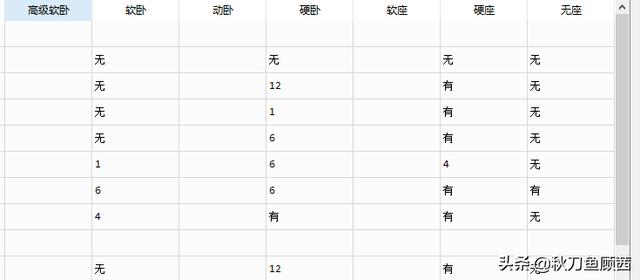
这样就完成了1月26号滕州到徐州的余票信息的爬取,但是大家需要查询的出发地、目的地各不相同,所以为了方便使用和程序移植,我们可以把上述过程,封装到一个函数中。
我们重新看上面的URL。如下图表示的那样,URL中trian_data=后接出发时间,from_station=后接出发城市城市代码(XCH是徐州的城市代码),to_station=后接目的城市代码(TXK是滕州的城市代码)。我们只要把这三个信息改成函数参数,就可以方便地查询不同出发地、目的地以及出发时间的余票信息了。

关于城市和代码的对照表,将其存储在了一个名为地名代码对照表.txt中,并将其上传到云中,可以将其读取到python,转换成字典形式,程序如下:
f = open( ‘地名代码对照表.txt‘, ‘r‘) #打开txt
dict1 = eval(f.read()) #将txt载入成字典形式
f.close() #关闭txt
最终字典dict1中的文件形式如下,键名为城市名,键值为城市代码。
这样,我们就可以直接通过输入城市的名字,来提取对应的代码信息,比如要提取滕州的城市代码,直接输入:
dict1[‘滕州‘]
就能提取相应的城市代码:
以上就解决了封装函数的所有障碍,直接将出发城市、目的城市、出发日期设成参数即可。我们将函数名命名为get_news(start,end,day)。Start,end,day对应上述参数,返回值为一各包含所有列车余票信息的dataframe 。
程序如下:
defget_news(start,end,day):driver = webdriver.PhantomJS( ‘D:webdriverphantomjs-2.1.1-windowsbinphantomjs.exe‘) url= ‘https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=‘+day.title() + ‘&leftTicketDTO.from_station=‘+dict1[start.title()] + ‘&leftTicketDTO.to_station=‘+dict1[end.title()] + ‘&purpose_codes=ADULT‘driver.get(url) html=driver.page_source html = html.replace( ‘‘‘<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">‘‘‘, ‘‘).replace( ‘</pre></body></html>‘, ‘‘) html=json.loads(html) data={
‘车次‘: ‘‘,
‘始发站‘: ‘‘,
‘终点站‘: ‘‘,
‘出发时间‘: ‘‘,
‘到达时间‘: ‘‘,
‘全程时间‘: ‘‘,
‘商务座‘: ‘‘,
‘一等座‘: ‘‘,
‘二等座‘: ‘‘,
‘高级软卧‘: ‘‘,
‘软卧‘: ‘‘,
‘动卧‘: ‘‘,
‘硬卧‘: ‘‘,
‘软座‘: ‘‘,
‘硬座‘: ‘‘,
‘无座‘: ‘‘} ?result=pd.DataFrame(data,index=[ 0])
??fori inhtml[ ‘data‘][ ‘result‘]: item = i.split( ‘|‘) #用"|"进行分割data[ ‘车次‘] = item[ 3] #车次在3号位置data[ ‘始发站‘] = item[ 6] #始发站信息在6号位置data[ ‘终点站‘] = item[ 7] #终点站信息在7号位置data[ ‘出发时间‘] = item[ 8] #出发时间信息在8号位置data[ ‘到达时间‘] = item[ 9] #抵达时间在9号位置data[ ‘全程时间‘] = item[ 10] #经历时间在10号位置data[ ‘商务座‘] = item[ 32] oritem[ 25] # 特别注意:商务座在32或25位置data[ ‘一等座‘] = item[ 31] #一等座信息在31号位置data[ ‘二等座‘] = item[ 30] #二等座信息在30号位置data[ ‘高级软卧‘] = item[ 21] #高级软卧信息在31号位置data[ ‘软卧‘] = item[ 23] #软卧信息在23号位置data[ ‘动卧‘] = item[ 27] #动卧信息在27号位置data[ ‘硬卧‘] = item[ 28] #硬卧信息在28号位置data[ ‘软座‘] = item[ 24] #软座信息在24号位置data[ ‘硬座‘] = item[ 29] #硬座信息在29号位置data[ ‘无座‘] = item[ 26] #无座信息在26号位置df1=pd.DataFrame(data,index=[ 0]) frames=[result,df1] result = pd.concat(frames,axis= 0, ignore_index= True) columns=[ ‘车次‘, ‘始发站‘, ‘终点站‘, ‘出发时间‘, ‘到达时间‘, ‘商务座‘, ‘一等座‘, ‘二等座‘, ‘高级软卧‘, ‘软卧‘, ‘动卧‘, ‘硬卧‘, ‘软座‘, ‘硬座‘, ‘无座‘] result=result.reindex(columns=columns)
returnresult driver.quit()
下面,调用函数查询武汉到滕州的1月26号火车票的情况:
a=get_news( ‘武汉‘, ‘滕州‘, ‘2019-01-26‘) #将函数返回结果赋给a
最终输出结果如下,1月26日从武汉到滕州有一班高铁和一班火车,并已全部告罄。想哭~~~

写在最后
小伙伴你是否抢到票了呢?需要余票检测提醒么?
以上是关于Python:爬虫助你回家,12306余票监测!的主要内容,如果未能解决你的问题,请参考以下文章