软件工程快速入门(下)
Posted pythontesting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件工程快速入门(下)相关的知识,希望对你有一定的参考价值。
9年薪70万的全栈需要什么技能?
什么是全栈开发人员?
全栈Web开发人员是一名技术专家,可以在任何应用程序的前端和后端工作。这个人应该熟悉3层模型的每一层。 3层由
- 表示层(处理用户界面的主前端部分),
- 业务逻辑层(任何处理数据验证的应用程序的后端部分)
- 数据库层
全栈开发人员不一定掌握所有技术。但是,专业人员应该在客户端和服务器端工作,并了解开发应用程序时的情况。他或她应该对所有软件技术都有真正的兴趣。
Stackoverflow调查开发者档案
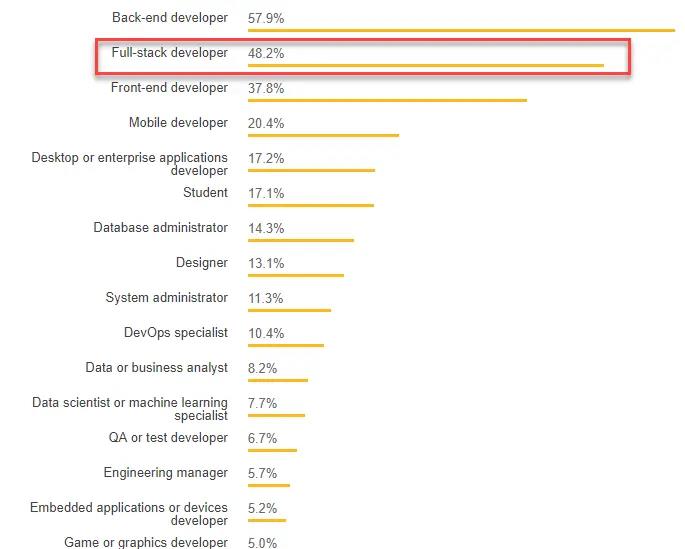
为什么需要全栈开发人员?
以下是您应聘请全栈开发专业人员的一些重要原因:
- 全栈开发人员可以帮助您保持系统的每个部分顺利运行
- 全栈开发人员可以为团队中的每个人提供帮助,并大大减少团队沟通的时间和技术成本
- 如果一个人扮演不同的角色,它可以节省公司的人员,基础设施和运营成本
成为Full Stack Developer所需的技能组合
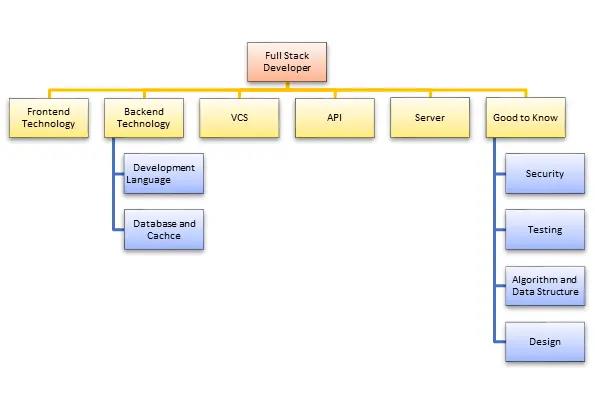
1)前端技术
全栈开发人员应该掌握HTML5,CSS3,JavaScript等基本前端技术。了解第三方库,如jQuery,LESS,Angular和React Js是可取的
2)开发语言
完整堆栈引擎应该知道至少一种服务器端编程语言,如Python、Java等
3)数据库和缓存
了解各种DBMS技术是全栈开发人员的另一个重要需求。 MySQL,MongoDB,Oracle,SQLServer被广泛用于此目的。了解缓存机制,如varnish,Memcached,Redis。
4)基本设计能力
为了成为一个成功的全栈开发人员,还建议了设计知识。此外,该人应该了解基本原型设计和UI / UX设计的原则。
5)服务器
希望接触处理Apache或nginx服务器。 Linux的良好背景有助于管理服务器。
6)版本控制系统(VCS)
版本控制系统允许完整堆栈开发人员跟踪代码库中所做的所有更改。 Git的知识帮助全栈开发人员了解如何获取最新代码,更新代码部分,在不破坏其他开发人员代码的情况下对其进行更改。
7)使用API(REST和SOAP):
了解Web服务或API对于完整堆栈开发人员也很重要。需要了解REST和SOAP服务的创建和使用。
8)其他:
- 能够编写高质量的单元测试
- 了解构建测试,记录和大规模部署的自动化流程
- 安全问题的意识很重要,因为每个层都有自己的漏洞
- 对算法和数据结构的了解也是专业全栈开发人员的基本需求
- AI与大数据知识(Python、C/C++、Java)
- 物联网与硬件知识
- 985统招工科背景轻松助推年薪过百万
什么是软件栈?
软件堆栈是程序的集合,它们一起用于产生特定结果。它包括操作系统及其应用程序。例如,智能手机软件堆栈包括OS以及电话应用程序,Web浏览器和默认应用程序。
上面的完整堆栈工程师的技能组合列表可能令人生畏。您需要根据您的职业目标,项目和公司要求掌握软件堆栈。以下是常用软件堆栈的列表。
无论您选择哪种堆栈,您都会发现架构和设计模式在不同堆栈中的相似之处
LAMP栈
LAMP是一种广泛使用的Web服务栈模型。它的名字“LAMP”是四个开源组件的首字母缩写。
L = Linux:一个开源操作系统
A = Apache:广泛使用的Web服务器软件,现在Nginx更流行。
M = MySQL:流行的开源数据库
P = Python/PHP等:服务器端开源脚本语言,以Python为主流。
这些上面讨论的组件相互支持。许多流行的网站和Web应用程序在LAMP堆栈上运行,例如:Facebook。
MERN堆栈
MERN是基于JavaScript的技术的集合:
M = MongoDB:流行的NoSQL数据库
E = Express:轻便且可移植的Web程序框架
R = React:用于构建用户界面的javascript库
N = Node.js:服务器端javascript。
Full Stack Developer的职责
作为完整堆栈开发人员,您可能参与以下活动:
- 将用户需求转换为新系统的整体架构和实现
- 管理项目并与客户协调
- 用Python / Java等语言编写后端代码
- 编写优化的前端代码HTML和JavaScript
- 理解,创建和调试与数据库相关的查询
- 创建测试代码以根据客户要求验证应用程序。
- 监控Web应用程序和基础架构的性能
- 以快速对Web应用程序进行故障诊断
全栈开发人员薪酬
作为一个完整的堆栈开发者,您每年可能赚到112000美元。约年薪70万人民币
在这个英国,薪水范围是40,000英镑--70,000英镑
全栈的神话
神话:全栈开发人员自己编写所有类型的代码。
事实:他或她可能知道不同的技术,但不会编写每个代码。
神话:写下前端和后端代码。
一些完整的堆栈开发人员可能会编码整个网站,如果他们是一名自由职业者。但这并不是他们强制性地编写前端和后端代码。
作为一个完整的堆栈工程师,您可以360度查看不同的组件,从而使软件产品成功。由于这种意识,与后端或前端工程师相比,Full Stack Developer可以快速创建原型。他们对产品设计和架构的看法非常有针对性和有用。
误区:如果您在外包公司工作,您将无法成为全栈开发人员
这是一种心态,而不是一种立场。为了成为全栈开发人员,您需要正确的技术知识组合。
小结
- 全栈Web开发人员是一名技术专家,可以在任何应用程序的前端和后端工作
- 全栈开发人员可以帮助您保持系统的每个部分顺利运行
- 成为全栈开发人员所需的技能集包括前端技术,开发语言,数据库,基本设计能力,服务器,使用API和版本控制系统
- 软件堆栈是程序的集合,它们一起用于产生特定结果
- LAMP代表Linux,Apache,MYSQL和Python/PHP
- MERN是MongoDB,Express,React,Node.js的完整形式
- MEAN代表MongoDB,Express,Angular.js和Node.js
- 全栈开发人员将用户需求转换为新系统的整体架构和实现
- FULL STACK DEVELOPER每年可赚取高达112,000美元
- 关于Full stack开发人员的最大神话是他们自己编写所有类型的代码,这是不正确的
10函数式编程
什么是函数编程?
函数式编程(也称为FP Functional Programming)是一种通过创建纯函数来思考软件构造的方法。它避免了在面向对象编程中观察到的共享状态,可变数据的概念。
功能语言依赖于表达式和声明而不是执行语句。因此,与依赖于本地或全局状态的其他过程不同,FP中的值输出仅取决于传递给函数的参数。
函数式编程的特点
- 函数式编程方法侧重于结果,而不是过程
- 重点是要计算的内容
- 数据是不可变的
- 函数式编程将问题分解为\'函数
- 它建立在数学函数的概念之上,它使用条件表达式和递归来执行计算
- 它不支持迭代,如循环语句和条件语句,如If-Else
函数式编程的历史
- 功能编程的基础是Lambda Calculus。它是在20世纪30年代开发的,用于功能应用,定义和递归
- LISP是第一个函数式编程语言。麦卡锡于1960年设计了它
- 在70年代后期,爱丁堡大学的研究人员定义了ML(元语言)
- 在80年代早期,Hope语言为递归和等式推理添加了代数数据类型
- 在2004年的功能语言创新\'Scala\'。
函数式编程语言
任何FP语言的目标都是模仿数学函数。但是,函数编程的基本计算过程是不同的。
这里是一些最着名的函数式编程语言:
- Haskell
- Python
- SML
- Clojure
- Scala
- Erlang
- Clean
- F#
- ML/OCaml Lisp / Scheme
- XSLT
- SQL
- Mathematica
基本函数编程术语和概念
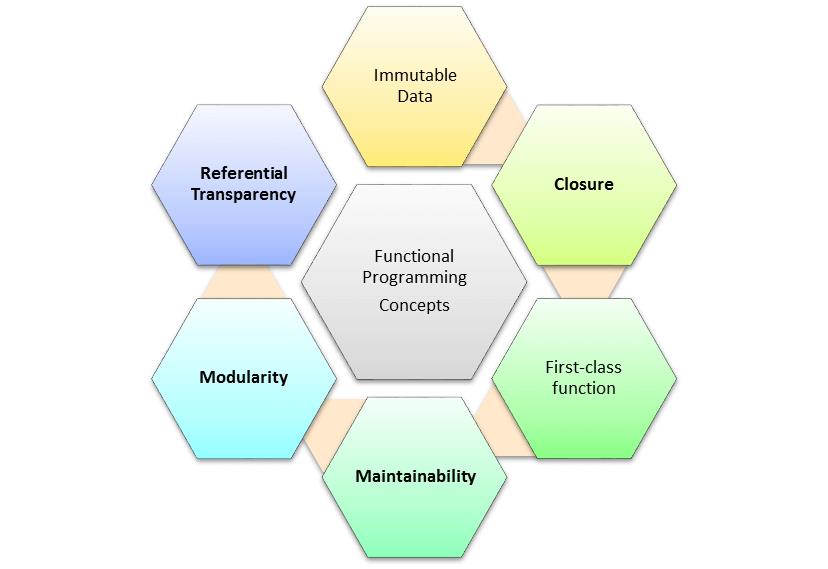
-
不可变数据
不可变数据意味着您应该能够轻松地创建数据结构,而不是修改已存在的数据结构。 -
参考透明度
功能程序应该像第一次那样执行操作。因此,您将了解在程序执行期间可能发生或可能不发生的事情及其副作用。在FP术语中,它被称为参照透明度。 -
模块化
模块化设计提高了生产力。小模块可以快速编码并且具有更大的重复使用机会,这肯定会导致程序的更快开发。除此之外,模块可以单独测试,这有助于您减少单元测试和调试所花费的时间。 -
可维护性
可维护性是一个简单的术语,这意味着FP编程更容易维护,因为您不必担心意外更改给定函数之外的任何内容。
First-class是一种定义,归因于对其使用没有限制的编程语言实体。因此,
First-class可以出现在程序的任何地方。
-
闭包
闭包是一个内部函数,即使在父函数执行后也可以访问父函数的变量。 -
高阶函数
高阶函数要么将其他函数作为参数,要么将它们作为结果返回。
高阶函数允许部分应用或currying。此技术一次将一个函数应用于其参数,因为每个应用程序返回一个接受下一个参数的新函数。
- 纯函数
“纯函数”是一个函数,其输入被声明为输入,并且不应隐藏它们。
Function Pure(a,b)
return a+b;
- 非纯函数
纯函数作用于它们的参数。如果不返回任何东西,它效率不高。而且,它为给定的参数提供相同的输出
int z;
function notPure()
z = z+10;
函数组合
函数组合结合了两个或更多功能来制作新功能。
- 共享共享状态
共享状态是OOP编程中的重要概念。它正在向对象添加属性。例如,如果HardDisk是对象,则可以将存储容量和磁盘大小添加为属性。
副作用是在被调用函数之外发生的任何状态变化。任何FP编程语言的最大目标是通过将其与其他软件代码分离来最小化副作用。在FP编程中,从其他部分中消除副作用至关重要.
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
函数式编程的好处
- 允许您避免混淆代码中的问题和错误
- 更容易测试和执行单元测试和调试FP代码。
- 并行处理和并发
- 热代码部署和容错
- 使用更短的代码提供更好的模块化
- 提高开发人员的生产力
- 支持嵌套函数
- 函数构造,如懒惰地图和列表等。
- 允许有效使用Lambda Calculus
函数编程的局限性
- 函数式编程范式并不容易,因此初学者很难理解
- 在编码期间很难维护尽可能多的对象
- 需要大量的嘲弄和广泛的环境设置
- 重用非常复杂,需要不断重构
- 对象可能无法正确表示问题
函数编程与面向对象编程
- FP使用不可变数据。OOP使用Mutable数据。
- FP遵循基于声明式编程的模型。OOP遵循命令式编程模型。
- FP重点是:“你在做什么。在计划中。” OOP的重点是“你如何进行编程”。
- FP支持并行编程。OOP不支持并行编程。
- FP的函数没有副作用。OOP方法会产生很多副作用。
- FP使用带递归的函数调用和函数调用执行流控制。OOP流控制过程使用循环和条件语句进行。
- FP陈述的执行顺序不是很重要。OOP陈述的执行顺序很重要。
- FP支持“数据抽象”和“行为抽象”。OOP支持“数据抽象”。
结论
- 函数编程或FP是基于一些基本定义原则思考软件构建的一种方式
- 功能编程概念侧重于结果,而不是过程
- 任何FP语言的目标都是模仿数学函数
- 一些最着名的函数式编程语言:1)Haskell 2)SM 3)Clojure 4)Scala 5)Erlang 6)Clean
- “纯函数”是一个函数,其输入被声明为输入,并且不应隐藏它们。产出也被宣布为产出。
- 不可变数据意味着您应该能够轻松地创建数据结构,而不是修改已存在的数据结构
- 允许您避免混淆代码中的问题和错误
- 还书代码并不容易,因此初学者很难理解
- FP使用不可变数据,而OOP使用Mutable数据
11MVC
什么是MVC?
MVC是一种架构模式,它将应用程序分为三个主要逻辑组件
- 模型 Model
- 视图 View
- 控制器 Controller
MVC将业务逻辑层和表示层相互分离。它传统上用于桌面图形用户界面(GUI)。如今,MVC架构已经成为设计Web应用程序和移动应用程序的流行。
MVC的历史
- MVC架构于1979年由Trygve Reenskaug首次讨论
- MVC模型于1987年首次在Smalltalk编程语言中引入。
- 在1988年的一篇文章中,MVC首次被接受为一般概念
- 最近,MVC模式被广泛用于现代Web应用程序中
MVC的特点
- 高度可测试,可扩展和可插拔的框架
- 提供对HTML和URL的完全控制
- 利用Django、flask、ASP.NET,JSP,等提供的现有功能。
- 清晰的逻辑分离:模型,视图,控制器。分离任务即:业务逻辑,UI逻辑和输入逻辑
- SEO友好L的URL路由。强大的URL映射,用于可理解和可搜索的URL
- 支持测试驱动开发(TDD)
MVC架构
MVC架构图
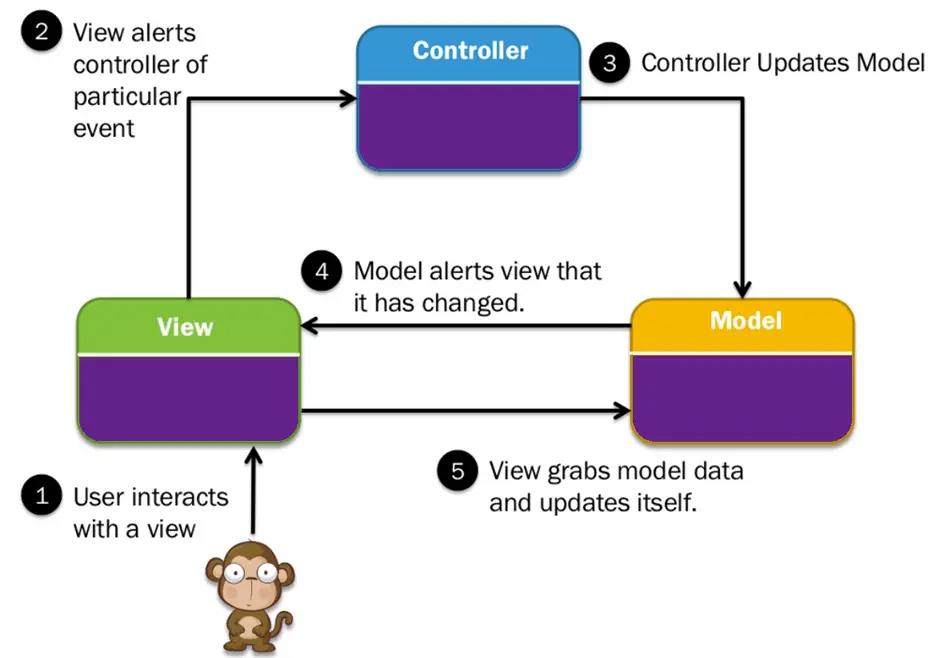
三个重要的MVC组件是:
-
模型:它包括所有数据及其相关逻辑
-
视图:向用户显示数据或处理用户交互
-
Controller:Model和View组件之间的接口
让我们详细看看这个组件: -
视图
View是表示数据表示的应用程序的一部分。
视图由从模型数据收集的数据创建。视图请求模型提供信息。
该视图还表示聊天,图表和表格中的数据。例如,任何客户视图都将包含所有UI组件,如文本框,下拉列表等。
- Controller
Controller是处理用户交互的应用程序的一部分。控制器解释来自用户的鼠标和键盘输入,通知模型和视图以适当地改变。
Controller向模型发送命令以更新其状态(例如,保存特定文档)。控制器还将命令发送到其关联视图以更改视图的显示(例如,滚动特定文档)。
- 模型
模型组件存储数据及其相关逻辑,表示在控制器组件或任何其他相关业务逻辑之间传输的数据。例如,Controller对象将从数据库中检索客户信息。它操纵数据并发送回数据库或使用它来呈现相同的数据。
它响应来自视图的请求,并响应来自控制器的指令以更新自身。它也是负责维护数据的模式的最低级别。
MVC示例
让我们看看日常生活中的模型视图控制器:
例1:点餐
- 假设你去一家餐馆。你不会去厨房准备你可以在家里做的食物。相反,你只是去那里等待服务员来。
- 现在服务员来找你,你只需要点食物。服务员不知道你是谁,你想要什么,他只是写下你的食物订单的细节。
- 服务员到厨房。但她不准备你的食物。
- 厨师准备你的食物。服务员会将您的订单连同您的餐桌号码一起交给他。
- 厨师然后为你准备食物。他用成分来烹饪食物。我们假设您的订单是蔬菜三明治。然后,他需要从冰箱中取出的面包,西红柿,土豆,辣椒,洋葱,小块,奶酪等
- 厨师最后把食物交给服务员。现在服务员的工作就是把这些食物搬到厨房外面。
- 现在,服务员知道您订购的食品以及如何送达。
在这种情况下,
试图=你
服务员=控制器
库克=模型
冰箱=数据
例2:汽车驱动
汽车驱动机制是MVC模型的另一个例子。
每辆车都包含三个主要部分。
View =用户界面:(变速杆,面板,方向盘,制动器等)
控制器 - 机制(引擎)
模型 - 储存(汽油)
汽车从发动机运行从存储中获取燃料,但它仅使用提到的用户界面设备运行。
流行的MVC Web框架
这里是一些流行的MVC框架的列表。
- Django
- Flask
- tornada
- Ruby on Rails
- CakePHP
- Yii
- CherryPy
- Spring MVC
- Catalyst
- Zend Framework
- CodeIgniter
- Laravel
- Fuel PHP
- Symphony
MVC的优势:主要优势
这里是使用MVC架构的主要好处。
- 易于代码维护,易于扩展和扩展
- MVC模型组件可以与用户分开测试
- 更容易支持新型客户
- 可以并行地执行各种组件的开发。
- 它通过将应用程序划分为三个单元来帮助您避免复杂性。型号,视图和控制器
- 它仅使用Front Controller模式,通过单个控制器处理Web应用程序请求。
- 为测试驱动开发提供最佳支持
- 它适用于由大型Web设计人员和开发人员团队支持的Web应用程序。
- 提供干净的关注点分离(SoC eparation of concerns)。
- 搜索引擎优化(SEO Search Engine Optimization)友好。
- 所有分类和对象彼此独立,以便您可以单独测试它们。
- MVC允许将控制器上的相关动作逻辑分组在一起。
使用MVC的缺点
- 难以阅读,更改,单元测试和重用此模型
- 框架导航可能有时间复杂,因为它引入了新的抽象层,这要求用户适应MVC的分解标准。
- 没有正式的验证支持
- 增加了数据的复杂性和低效率
-与现代用户界面结合有难度
-需要多个程序员进行并行编程。
-需要了解多种技术。
-在Controller中维护大量代码
参数 |3层体系结构 |MVC体系结构
通信|这种类型的体系结构模式永远不会直接与数据层通信。|所有层使用三角形拓扑直接通信。
用法 |3层:广泛用于Web应用程序,其中客户端,数据层和中间件a在物理上独立的平台上运行。 |通常用于在单个图形工作站上运行的应用程序。
小结
- MVC是一种架构模式,将应用程序分为1)模型,2)视图和3)控制器
- 模型:它包括所有数据及其相关逻辑
- 视图:向用户显示数据或处理用户交互
- Controller:Model和View组件之间的接口
- MVC架构于1979年由Trygve Reenskaug首次讨论
- MVC是一个高度可测试,可扩展和可插入的框架
一些流行的MVC框架是Django、flask、tornada、Rails,Zend Framework,CodeIgniter,Laravel,Fuel PHP等。
Git快速入门
前篇文章玩转Git入门篇我们已经对Git有了一个大概的了解,接下来我们学习下Git的如何管理项目的。
远程仓库
Repository(仓库)包含的内容 - Git的目标是管理一个工程,或者说是一些文件的集合,以跟踪它们的变化。Git使用Repository来存储这些信息。一个仓库主要包含以下内容(也包括其他内容):
- 许多commit objects
- 到commit objects的指针,叫做heads
- Git的仓库和工程存储在同一个目录下,在一个叫做.git的子目录中。
创建Repository(仓库)
在使用Repository(仓库)之前,我们首先需要创建仓库,创建仓库有很多种,这里常见的有如下几种:
- 自己搭建个 Git 服务器,安装如 GitLab 的Git版本管理系统
- 使用第三方托管平台,如国内的 http://git.oschina.net 和国外的 http://github.com/
这里使用第三方托管平台作为讲解,以 http://git.oschina.net 为例,注册过程就省略。
- 创建仓库

点击红色箭头指向的”+“号,以创建一个仓库,如下所示 –
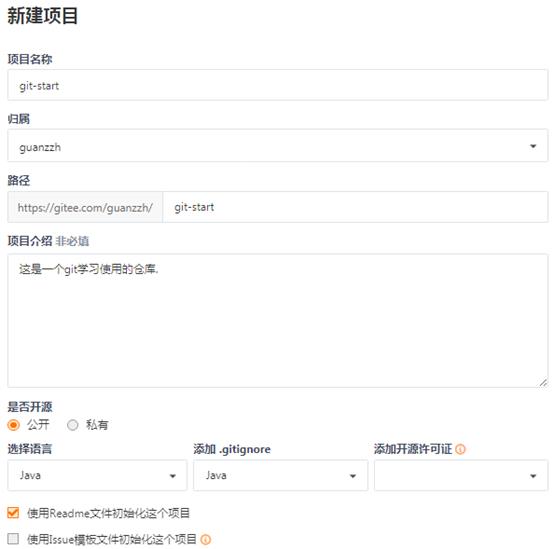
这样,一个公开的仓库就创建完成了。要记住上面图片创建的路径:
https://gitee.com/guanzzh/git-start.git
获取 Git 仓库
方法一:从一个服务器克隆一个现有的 Git 仓库。
方法二:在现有项目或目录下导入所有文件到 Git 中;
克隆现有的仓库
如果你想获得一份已经存在了的 Git 仓库的拷贝,比如说,想为某个开源项目贡献自己的一份力,这时就要用到 git clone 命令。当你执行 git clone 命令的时候,默认配置下远程 Git 仓库中的每一个文件的每一个版本都将被拉取下来。
在安装了Git 的 Windows系统上,在一个目录(本示例是:D:\\Git_Repository)中,单击右键,在弹出的菜单中选择“Git Bash”。
克隆仓库的命令格式是 git clone [url] 。 比如,要克隆 Git 的上面创建的仓库 git-start.git,可以用下面的命令:
$ git clone https://gitee.com/guanzzh/git-start.git

这会在当前目录下创建一个名为 “git-start.git” 的目录,并在这个目录下初始化一个 .git 文件夹,从远程仓库拉取下所有数据放入 .git 文件夹,然后从中读取最新版本的文件的拷贝。
如果想在克隆远程仓库的时候,自定义本地仓库的名字,可以使用如下命令:
$ git clone https://gitee.com/guanzzh/git-start.git mygit-start
Git 支持多种数据传输协议。 上面的例子使用的是 https:// 协议,不过也可以使用 git:// 协议或者使用 SSH 传输协议,比如 user@server_ip-or-host:path/to/repo.git 。在服务器上搭建 Git 将会介绍所有这些协议在服务器端如何配置使用,以及各种方式之间的利弊。
在现有目录中初始化仓库
如果不克隆现有的仓库,而是打算使用 Git 来对现有的项目进行管理。假设有一个项目的目录是:D:\\Git_Repository\\demo-sample,进入该目录并输入:
$ git init
git init命令创建一个空的Git仓库或重新初始化一个现有仓库。
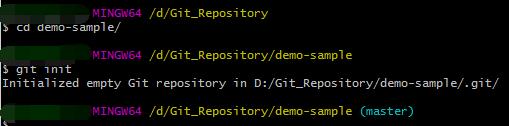
该命令将创建一个名为 .git 的子目录,这个子目录含有初始化的 Git 仓库中所有的必须文件,仅仅是做了一个初始化的操作,项目里的文件还没有被跟踪。此时可通过 git add 命令来实现对指定文件的跟踪,然后执行 git commit 提交。
假设在目录 D:\\Git_Repository\\demo-sample中有一些代码需要跟踪(版本控制),可通过 git add 命令来实现对HelloWorld.java文件的跟踪 –
$ git addHelloWorld.java
$ git commit -m \'initial project version\'
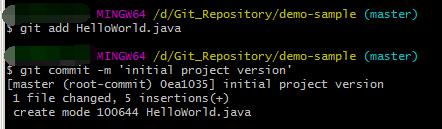
更新提交到仓库
记录每次更新到仓库
工作目录下的每一个文件都不外乎这两种状态:已跟踪或未跟踪。 已跟踪的文件是指那些被纳入了版本控制的文件,在上一次快照中有它们的记录,在工作一段时间后,它们的状态可能处于未修改,已修改或已放入暂存区。工作目录中除已跟踪文件以外的所有其它文件都属于未跟踪文件,它们既不存在于上次快照的记录中,也没有放入暂存区。 初次克隆某个仓库的时候,工作目录中的所有文件都属于已跟踪文件,并处于未修改状态。
编辑过某些文件之后,由于自上次提交后你对它们做了修改,Git 将它们标记为已修改文件。 我们逐步将这些修改过的文件放入暂存区,然后提交所有暂存了的修改,如此反复。所以使用 Git 时文件的生命周期如下:
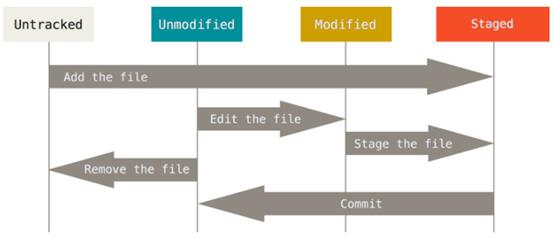
检查当前文件状态
要查看哪些文件处于什么状态,可以用 git status 命令。
$ git status
在项目中新建不存在文件mytext.txt,使用 git status 命令,将看到一个新的未跟踪文件:
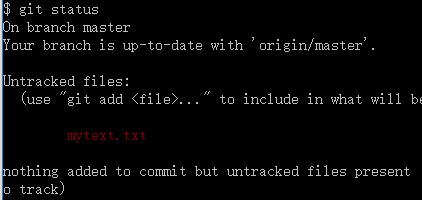
若使用 git status -s 命令或 git status --short 命令,将得到一种更为紧凑的格式输出。

??标识未跟踪,新增A,修改M,同时出现MM,右M标识文件被修改未放入暂存区,左M标识该文件被修改并放入暂存区。
查看已暂存和未暂存的修改
git diff 将通过文件补丁的格式显示具体哪些行发生了改变。
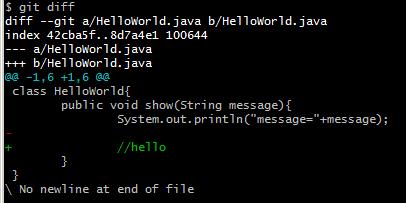
请注意,git diff 本身只显示尚未暂存的改动,而不是自上次提交以来所做的所有改动。 所以有时候你一下子暂存了所有更新过的文件后,运行 git diff 后却什么也没有,就是这个原因。
然后用 git diff --cached 查看已经暂存起来的变化:(--staged 和 --cached 是同义词)

git difftool 命令来用 Araxis ,emerge 或 vimdiff 等软件输出 diff 分析结果。

:qa!退出窗口
跟踪新文件
使用命令 git add 开始跟踪一个文件。 (添加内容到下一次提交中)
$ git add mytext.txt
此时再运行 git status 命令,会看到 mytext.txt 文件已被跟踪,并处于暂存状态:
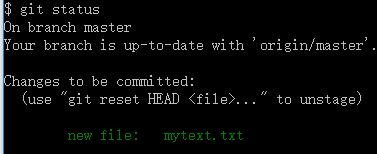
只要在 Changes to be committed 这行下面的,就说明是已暂存状态。 如果此时提交,那么该文件此时此刻的版本将被留存在历史记录中。git add 命令使用文件或目录的路径作为参数;如果参数是目录的路径,该命令将递归地跟踪该目录下的所有文件。
暂存已修改文件
修改一个已被跟踪的文件。然后运行 git status 命令,会看到下面内容:

出现在 Changes not staged for commit 这行下面,说明已跟踪文件的内容发生了变化,但还没有放到暂存区。要暂存这次更新,需要运行 git add 命令。 这是个多功能命令:可以用它开始跟踪新文件,或者把已跟踪的文件放到暂存区,还能用于合并时把有冲突的文件标记为已解决状态等。
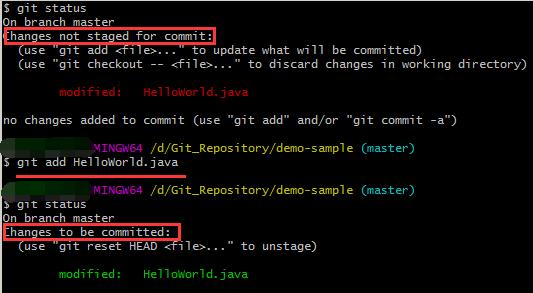
先修改README.md文件,git add之后,现在两个文件都已暂存,下次提交时就会一并记录到仓库。 假设此时,修改README.md,再运行 git status :
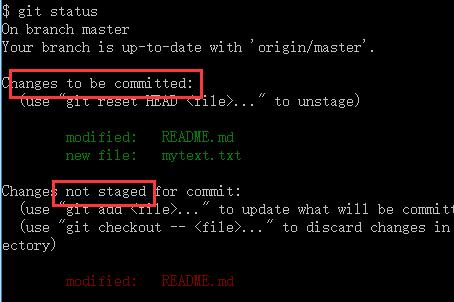
README.md 文件同时出现在暂存区和非暂存区。实际上 Git 只不过暂存了运行 git add 命令时的版本, 如果现在提交,README.md 的版本是最后一次运行 git add 命令时的那个版本,而不是运行 git commit 时,在工作目录中的当前版本。运行了 git add 之后又作了修订的文件,需要重新运行 git add 把最新版本重新暂存起来:
忽略文件
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。在这种情况下,我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。
$ cat .gitignore
*.[oa]
*~
忽略所有以 .o 或 .a 结尾的文件。
忽略所有以波浪符(~)结尾的文件,
.gitignore 的格式规范如下:
- 所有空行或者以 # 开头的行都会被 Git 忽略。
- 可以使用标准的 glob 模式匹配。
- 匹配模式可以以(/)开头防止递归。
- 匹配模式可以以(/)结尾指定目录。
- 要忽略指定模式以外的文件或目录,可以在模式前加上惊叹号(!)取反。
提示:GitHub 有一个十分详细的针对数十种项目及编程语言的 .gitignore 文件列表,你可以在 http://github.com/github/gitignore 找到它。
提交更新
每次准备提交前,先用 git status 看下,是不是都已暂存起来了,如果没有暂存起来则要先使用命令:git add .将所有文件暂存起来, 然后再运行提交命令 git commit:
$ git status
$ git add .
$ git commit
提交后它会告诉你,当前是在哪个分支(master)提交的,本次提交的完整 SHA-1 校验和是什么(463dc4f)
请记住,提交时记录的是放在暂存区域的快照。任何还未暂存的仍然保持已修改状态,可以在下次提交时纳入版本管理。 每一次运行提交操作,都是对你项目作一次快照,以后可以回到这个状态,或者进行比较。
跳过使用暂存区域
git commit 加上 -a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤:
$ git commit -a -m \'added new benchmarks\'
Git隐藏(stash)操作
在Git中,隐藏操作将使您能够修改跟踪文件,阶段更改,并将其保存在一系列未完成的更改中,并可以随时重新应用。要将一个新的存根推到堆栈上,运行git stash命令。
$ git stash
Saved working directory and index state WIP on master: ef07ab5 synchronized with the remote repository
HEAD is now at ef07ab5 synchronized with the remote repository
通过使用git stash list命令来查看已存在更改的列表。
$ git stash list
stash@{0}: WIP on master: ef07ab5 synchronized with the remote repository
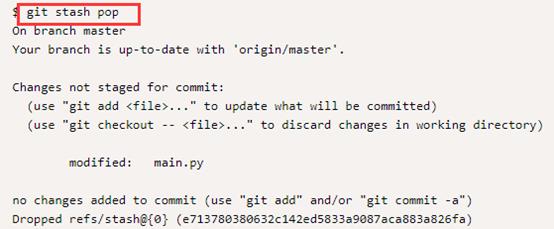
想要重新开始新的功能的代码编写,查找上次没有写完成的代码,只需执行git stash pop命令即可从堆栈中删除更改并将其放置在当前工作目录中。
移除文件
要从 Git 中移除某个文件,就必须要从已跟踪文件清单中移除(确切地说,是从暂存区域移除),然后提交。 可以用 git rm 命令完成此项工作。
$ rm mytext.txt
已经存放到暂存区,则必须要用强制删除选项 -f(注:即 force 的首字母)。
git rm 命令后面可以列出文件或者目录的名字,也可以使用 glob 模式。 比方说:
$ git rm log/\\*.log
移动文件
Git 并不显式跟踪文件移动操作。在 Git 中对文件改名,命令如下:
$ git mv file_from file_to
相当于如下三个命令:
$ mv README.md README
$ git rm README.md
$ git add README
查看提交历史
查看提交历史,git log 命令。默认不用任何参数的话,git log 会按提交时间列出所有的更新,最近的更新排在最上面。

一个常用的选项是 -p,用来显示每次提交的内容差异。 你也可以加上 -2 来仅显示最近两次提交:

想看到每次提交的简略的统计信息,可以使用 --stat 选项:

另外一个常用的选项是 --pretty。 这个选项可以指定使用不同于默认格式的方式展示提交历史。 这个选项有一些内建的子选项供你使用。 比如用 oneline 将每个提交放在一行显示,查看的提交数很大时非常有用。 另外还有 short,full 和 fuller 可以用,展示的信息或多或少有些不同。

撤消操作
有时候我们提交完了才发现漏掉了几个文件没有添加,或者提交信息写错了。 此时,可以运行带有 --amend 选项的提交命令尝试重新提交:
$ git commit --amend
这个命令会将暂存区中的文件提交。 如果自上次提交以来你还未做任何修改(例如,在上次提交后马上执行了此命令),那么快照会保持不变,而你所修改的只是提交信息。
取消暂存的文件
使用 git reset HEAD <file>... 来取消暂存。
$ git reset HEAD mytext.txt
reset强调,撤销
- git reset head - - filename
- 撤销上次暂存(取消暂存区的内容,用head指向的目录(版本库)替换暂存区)
- 如果只删除暂存,保留工作区,可以使用git rm --cached -r filename,-r表示递归删除
- git reset - -hard head:
- 撤销本地和暂存区的所有变动(用head指向的目录(版本库)替换本地和暂存区)
- git reset – hard origin/master
- 撤销本地、暂存区、版本库(用远程服务器的origin/master替换本地、暂存区、版本库)
用Git复位移动头指针
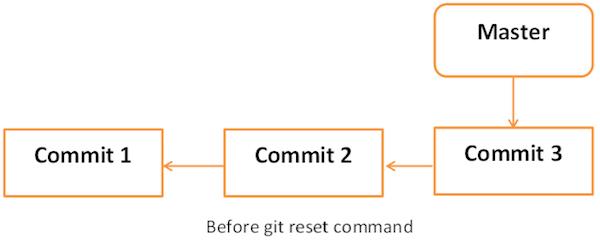
经过少量更改后,可以决定删除这些更改。 git reset命令用于复位或恢复更改。 我们可以执行三种不同类型的复位操作。语法:git reset [<mode>] [<commit>]
下图显示了git reset命令的图示。
git reset命令之前 -
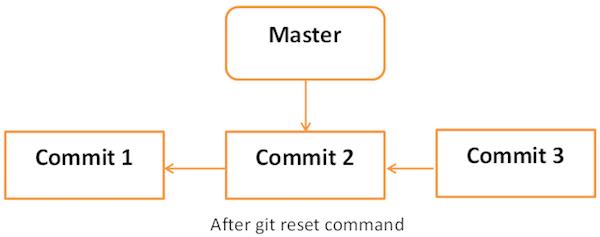
git reset命令之后 -
—soft选项
每个分支都有一个HEAD指针,它指向最新的提交。 如果用--soft选项后跟提交ID的Git reset命令,那么它将仅重置HEAD指针而不会破坏任何东西。
.git/refs/heads/master文件存储HEAD指针的提交ID。 使用git reset --soft [comittedID]命令。可使用git log -1命令验证它。
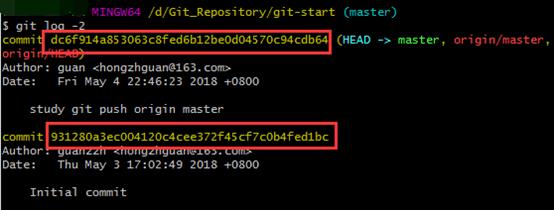
$ git reset --soft 931280a3ec004120c4cee372f45cf7c0b4fed1bc

使用--mixed选项的Git重置将从尚未提交的暂存区域还原这些更改。它仅从暂存区域恢复更改。对文件的工作副本进行的实际更改不受影响。 默认Git复位等效于执行git reset -- mixed。
如果使用--hard选项与Git重置命令,它将清除分段区域; 它会将HEAD指针重置为特定提交ID的最新提交,并删除本地文件更改。
撤消对文件的修改
用暂存区的内容替换工作区的文件。使用 git checkout -- <file>... 来撤消之前所做的修改。(未加入暂存区)
$ git checkout -- mytext.txt

加入暂存区撤销修改
当执行添加操作时,文件将从本地存储库移动到暂存区域。 如果用户意外修改文件并将其添加到暂存区域,则可以使用git checkout命令恢复其更改。
在Git中,有一个HEAD指针总是指向最新的提交。 如果要从分段区域撤消更改,则可以使用git checkout命令,但是使用checkout命令,必须提供一个附加参数,即HEAD指针。 附加的提交指针参数指示git checkout命令重置工作树,并删除分段更改。
$ git checkout head -- mytext.txt
休息片刻,接下来我们将在Git快速入门进阶篇中继续探讨Git是如何管理项目的。
以上是关于软件工程快速入门(下)的主要内容,如果未能解决你的问题,请参考以下文章