python之IO编程
Posted yhw-miracle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之IO编程相关的知识,希望对你有一定的参考价值。
(首发于 2018 年 7 月 30 日)
IO 在计算机中指的是 Input/Output,也就是输入和输出。凡是用到数据交换的地方,都会涉及到 IO 编程。在 IO 编程中,Stream(流)是一种很重要的概念,分为输入流(Input Stream)和输出流(Output Stream)对于流的概念,我们可以这样理解,流相当于一个水管,数据相当于水管中的水,但是只能单向流动,所以数据传输过程中需要架设连个两个水管,一个负责输入,一个负责输出,这样读写就可以实现读写同步了。
1. 文件读写
1.1 文件打开
Python 内置了读写文件的函数,方便了文件的 IO 操作。在读写文件前,需要打开文件,确定文件的读写模式。打开文件语法如下:
1 open(name[.mode[.buffering]])
其中, open 函数必须要给出文件名参数,模式(mode)和缓冲区(buffering)是可选的,默认模式是读模式,默认缓冲是无,若成功打开文件,会返回一个文件对象;若打开文件失败(文件不存在或文件路径错误等),会产生异常。

1.2 文件模式
open 函数中 mode 参数可以实现对文件不同的操作。其中,mode 参数具体值如下表所示。
| 值 | 功能 |
|---|---|
| ‘r’ | 读模式 |
| ‘w’ | 写模式 |
| ‘a’ | 追加模式 |
| ‘b’ | 二进制模式 |
| ‘+’ | 读/写模式 |
这里,需要注意以下几点:
- 一般在处理一些二进制文件(如,音频,视频,图像文件),需要在模式参数上加上 ‘b’;
- 模式 ‘b’ 和 ‘+’ 可以和其他模式共同使用,如,’rb’ 表示读取一个二进制文件;
- ‘w’ 模式在写文件时,每运行一次程序,会从头开始写;而 ‘a’ 模式可以以追加的方式每次默认在文件末尾进行读或写文件。
1.3 文件缓冲区
open 函数中 buffering 参数控制着文件的缓冲。如果该参数为 0,IO 操作就是无缓冲,数据是直接写到硬盘上;若果该参数是 1,IO 操作是有缓冲的,数据先写到内存里(缓冲区里),只有使用 flush 函数或者 close 函数,数据才会更新到磁盘。
如果该参数是大于 1 的数字,代表缓冲区的大小(单位为字节),-1 (或者其他任何负数)代表使用默认缓冲区的大小。
1.4 文件读取
文件读取主要分为按字节读取和按行读取,先利用 f=open(‘’) 打开文件,如果成功打开文件;接下来利用 f.read() 就可以读取文件了,将文件内容以 str 类型返回;最后需要利用 f.close() 关闭文件。文件使用完毕必须关闭,因为文件对象会占用操作系统资源,影响系统的 IO 操作。
由于文件操作过程中可能会出现 IO 异常,一旦出现 IO 异常,后面的 close() 方法就不会调用。为了保证程序的健壮性,我们可以使用 try—except—finally 来实现。
1 try: 2 f = open(r‘./test.txt‘) 3 print(f.read()) 4 finally: 5 if f: 6 f.close()
上面的代码略长, python 提供了一种简单的写法,使用 with语句来代替 try—finally 代码块和 close() 方法,可以这样写。
1 with open(r‘./test.txt‘,‘r‘) as fileReader: 2 print(fileReader.read())
这里,需要注意几点:
- 调用 read() 方法是一次将文件内容读到内存中,如果文件过大,将会出现内存不足的问题,一般对于大文件,我们可以对此调用 read(size) 方法来读取,每次读取 size 字节数;
- 对于文本文件,可以调用 readline() 函数一次读取一行内容,调用 readlines() 函数一次读取所以内容并按行返回列表。
1.5 文件写入
写文件和读文件流程是一样的,区别是在调用 open() 方法时,传入标识符 ‘w’ 或者 ‘wb’ 表示写入文本文件或者写入二进制文件;接下来调用 write() 方法,制定写入内容;最后文件使用完毕后,需要关闭文件,释放文件对象。
1 f = open(‘./test.txt‘,‘w‘) 2 f.write(‘‘) 3 f.close()
在使用 write() 方法时,操作系统不会立即将数据写入到文件中,而是先将数据写入内存中的缓冲区里,等到空间时在写入到文件中,最后使用 close() 方法将数据完整地写入文件中,也可以使用 flush() 方法将数据立即写入到文件中。写文件过程可能会出现 IO 异常,我们可以采用 with 语句。
1 with open(r‘./test.txt‘,‘w‘) as fileWriter: 2 fileWriter.write(‘hello‘)
2. 序列化操作
序列化,就是将内存中的变量变成可存储或可传输的过程。将内存中的变量序列化之后,可以把序列化的内容写入到磁盘,或者通过网络传输到别的机器上,实现程序状态的保存和共享。反过来,把变量内容从序列化的对象重新读取到内存,成为反序列化。
在 python 中提供了两个模块(cPickle 和 pickle)来实现序列化,前者是由 c 语言编写的,效率要比后者高很多,但是两个模块的功能是一样的。一般在编写程序时,采取的方案是先导入 cPickle 模块,如果此模块不存在,再导入 pickle 模块。
1 try: 2 import cPickle as pickle 3 except ImportError: 4 import pickle
ickle 实现序列化主要使用的是 dumps 方法或 dump 方法。dumps 方法可以将任意对象序列化成一个 str,然后可以将这个 str 写入到文件中保存(需额外操作)。
1 d = dict(url=‘index.html‘, tilte=‘firstPage‘, content=‘firstPage‘) 2 print pickle.dumps(d)
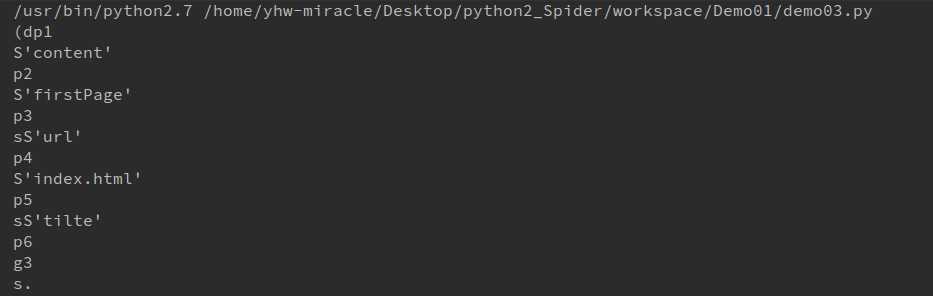
如果使用 dump 方法,可以将序列化后的对象直接写入到文件中。
1 d = dict(url=‘index.html‘, tilte=‘firstPage‘, content=‘firstPage‘) 2 f = open(‘./dump.txt‘, ‘wb‘) 3 pickle.dump(d, f)
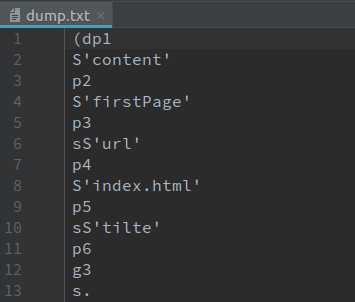
2.2 反序列化
python 实现反序列化使用的是 loads 方法或 load 方法。把序列化后的文件从磁盘上读取为一个 str,然后使用 loads 方法将这个 str 反序列化为对象,或者直接使用 load 方法将文件直接反序列化为对象。
1 with open(‘./dump.txt‘, ‘rb‘) as f: 2 print pickle.load(f)

以上是关于python之IO编程的主要内容,如果未能解决你的问题,请参考以下文章