Nacos必知必会:这些知识点你一定要掌握!
Posted wangzhongyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nacos必知必会:这些知识点你一定要掌握!相关的知识,希望对你有一定的参考价值。

前言
Nacos 是一个开源的服务发现、配置管理和服务治理平台,是阿里巴巴开源的一款产品。
Nacos 可以帮助开发者更好地管理微服务架构中的服务注册、配置和发现等问题,提高系统的可靠性和可维护性。
本文将介绍 Nacos 的必知必会知识点,包括服务注册与发现、配置管理、命名空间等内容,帮助读者更好地了解 Nacos 的使用方法和技巧。
如果你正在使用微服务架构,或者对服务发现和配置管理感兴趣,那么不要错过这篇文章!

什么是 Nacos?
Nacos 是一种分布式服务发现和配置管理工具,它可以用于服务注册、健康检查、负载均衡、故障恢复、动态配置等方面。
Nacos 支持多种服务发现方式和多种协议,可以帮助开发人员和运维人员更好地管理和维护分布式系统。
Nacos 的主要功能有哪些?
Nacos 的主要功能包括服务注册、健康检查、负载均衡、故障恢复、动态配置等。
其中,服务注册和健康检查是 Nacos 最核心的功能,它可以帮助开发人员和运维人员更好地管理和维护分布式系统。
Nacos 的服务注册是如何实现的?
- Nacos 的服务注册是通过 Agent 进程实现的。
- 当一个服务启动时,它会向 Nacos 的 Agent 发送一个注册请求,Agent 会将服务的元数据存储在本地,并将服务的信息发送到 Nacos 的 Server 上。
- 当服务停止时,它会向 Agent 发送一个注销请求,Agent 会将服务的元数据从本地删除,并将服务的信息从 Nacos 的 Server 上删除。
Nacos 的健康检查是如何实现的?
- Nacos 的健康检查是通过 Agent 进程实现的。
- 当一个服务注册后,它会向 Nacos 的 Agent 发送一个健康检查请求,Agent 会定期向服务发送健康检查请求,并根据服务的响应结果来判断服务的健康状态。
- 如果服务的健康状态发生变化,Agent 会将服务的状态信息发送到 Nacos 的 Server 上,以便其他服务可以及时发现和处理。
Nacos 的负载均衡是如何实现的?
- Nacos 的负载均衡是通过 Service Mesh 实现的。
- 当一个服务需要访问其他服务时,它会向 Nacos 的 Agent 发送一个服务发现请求,Agent 会返回一个可用的服务地址列表,并根据负载均衡算法选择一个地址进行访问。
- Nacos 支持多种负载均衡算法,包括轮询、随机、加权轮询、加权随机等。
Nacos 的故障恢复是如何实现的?
- Nacos 的故障恢复是通过 Agent 进程实现的。
- 当一个服务的健康状态发生变化时,Agent 会将服务的状态信息发送到 Nacos 的 Server 上,并通知其他服务进行故障恢复。
- 如果一个服务无法访问其他服务,它会向 Nacos 的 Agent 发送一个故障恢复请求,Agent 会返回一个可用的服务地址列表,并根据负载均衡算法选择一个地址进行访问。
Nacos 的动态配置是如何实现的?
- Nacos 的动态配置是通过 Config Server 实现的。
- 当一个服务需要读取配置信息时,它会向 Nacos 的 Config Server 发送一个配置读取请求,Server 会返回存储在 Nacos 的配置信息。
- 当配置信息发生变化时,Nacos 的 Config Server 会将变化的信息发送到所有注册了 Watcher 的服务,服务可以根据事件信息进行相应的处理。
Nacos 的服务发现方式有哪些?
- Nacos 支持多种服务发现方式,包括 DNS、HTTP API、RPC API、Service Mesh 等。
- 其中,DNS 和 HTTP API 是最常用的服务发现方式,它们可以帮助开发人员和运维人员更方便地访问和管理服务。
Nacos 的优缺点是什么?
Nacos 的优点包括:
- 支持多种服务发现方式和多种协议,可以满足不同场景下的需求。
- 支持多种负载均衡算法和故障恢复机制,可以提高系统的可用性和稳定性。
- 支持动态配置,可以帮助开发人员更好地管理和维护配置信息。
- 支持多数据中心,可以帮助开发人员和运维人员更好地管理和维护分布式系统。
Nacos 的缺点包括:
- 学习成本较高,需要掌握一定的分布式系统和网络知识。
- 部署和维护成本较高,需要投入一定的人力和物力。
- 对于小型项目来说,使用 Nacos 可能会过于复杂,不太适合初学者使用。
总之,Nacos 是一种非常强大的分布式服务发现和配置管理工具,它可以帮助开发人员和运维人员更好地管理和维护分布式系统。
但是,使用 Nacos 也需要投入一定的人力和物力,需要根据实际情况进行选择和使用。
欢迎关注 ❤
我的微信:wangzhongyang1993
视频号:王中阳Go
公众号:程序员升职加薪之旅
必知必会 - 使用kafka之前要掌握的知识
必知必会系列之kafka
前记
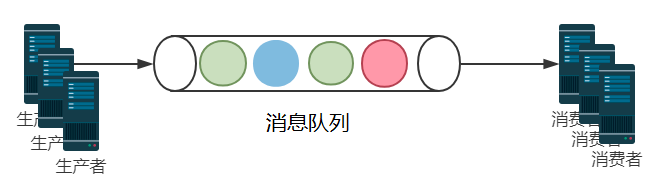
消息队列是分布式系统架构中不可或缺的基础组件,它主要负责服务间的消息通信和数据传输。
市面上有很多的开源消息队列服务可以选择,除了kafka,还有Activemq,Rocketmq等。
对于要选择哪一个服务需要根据的实际情况来定,今天主要介绍kafka。
kafka特性
大多数消息队列服务的主要功能都是大同小异,都能完成基本的消息传输和保障机制,只是在具体的实现细节上会有所不同。
而kafka也是有它独特的特性,主要体现在如下几个方面:
- 文件存储消息日志
- 支持高并发和大吞吐量
- 支持消息持久化
- 可以重复消费消息
除了这些之外的还有通用消息队列服务的标配。比如:
- 支持队列和订阅2种消息传输方式
- 支持集群部署
- 支持多机备份
kafka实现
相比于其它的消息队列服务在内存中存储消息而言,kafka最大的特点就是使用文件存储消息日志。并且这也没有导致kafka的读取性能和整体的吞吐量。
而之所以能达到这样的效果,还要取决于它的设计原理,即保证了高速读写(read before|write behind),又保证了并发效率。
顺序写
kafka之所以能高速写,是因为利用了磁盘的顺序写的特性。经测试发现磁盘的顺序写甚至比内存的随机读还要快很多,因此kafka在写文件时会批量的写入,并且追加到一个文件中。
高速读
高速读除了因为连续读取,操作系统会有预读的机制之外,还体现在它的文件结构的设计。kafka把消息按topic分类,topic又可以按分区读写,分区再按索引文件分割存取。
这样当我们知道了topic、分区、offset之后,就可以通过O(1)的方式找到目标消息所在的位置。
概念介绍
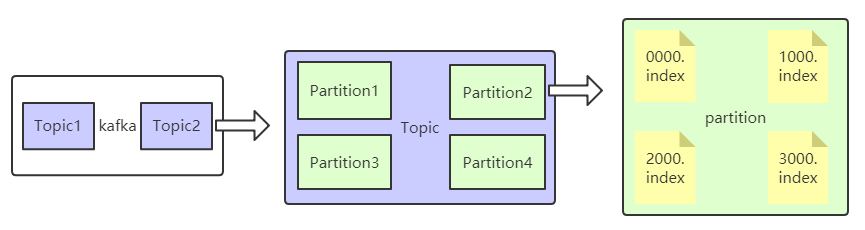
kafka中有几个重要的概念:
- Topic
- partition
- Consumer Group
- offset
Topic:定义一个消息分类,相关的生产者和消费者通过特定的Topic来进行联通。
partition:Topic下的子概念,一个Topic通常可以分为1或多个partition,该Topic中的消息会分发到不同的partition中,也可以在代码中指定特定的partition。
Consumer Group:消费者组,它的作用的限定一组消费者,同组内的消费者在消费时是一种互斥模式;即同一个组内只有一个消费者可以消费到某个特定的消息。
offset:Topic中记录某条消息位置的偏移量信息,通常offset是消费者读取消息的依据。
分区和分组
分区即一个Topic设置了多个partition(默认是1个),分区有如下的优势:
- 支持分布式
- 支持负载并发请求
- 支持容灾备份
- 保证分区内的消费顺序
分组即把相关联的消费者放在一个组内(kafka对每个消费者会分配一个默认分组,如果不指定的话),分组有如下优势:
- 组内多个消费者可以并发处理(提高消费效率的方式)
- 消费者管理更加灵活
接着,在po一张分区和分组的关系图。
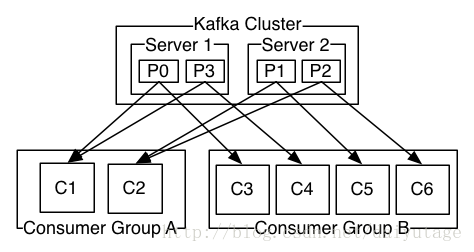
从图中可以看到的关系如下:
- Topic下的消息会分发给所有的订阅组
- 组内的消费者会各自消费不同的分区(且在分区和组内消费者数不变的情况下,关系是固定的)
- 一个消费者可以消费一或多个分区
- 一个分区只能被同一个组内的一个消费者消费
这个是设计相对合理的分区和消费者数量,组内消费者数 = 分区数 * N。如果分区数和消费者数设置不合理,则会有消费者永远拿不到数据。
所以,分区、分组是kafka支持高并发处理的基础。
队列还是分发
跟其它消息队列一样,kafka的消息模式也支持队列和分发订阅两种方式。
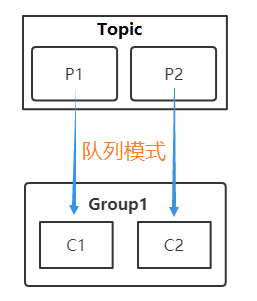
队列模式也称生产消费者模式,特点是同一个消息同时只能被一个消费者消费。其逻辑结构可以简单的通过下面的示意图来说明。
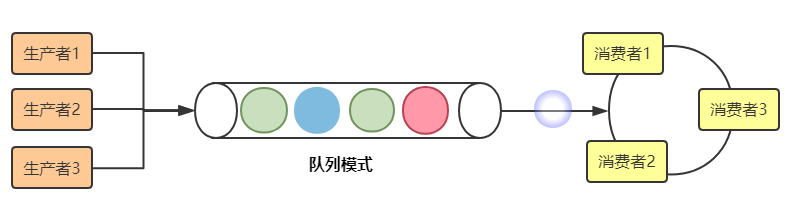
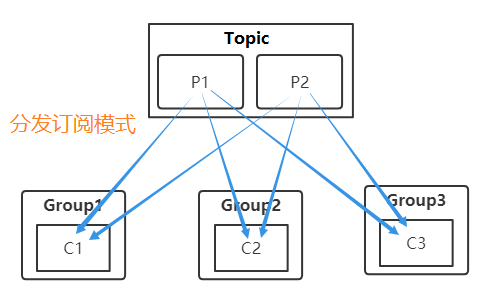
分发订阅模式的特点是同一个消息同时可以被所有的消费者消费。(类似于广播的形式)其逻辑结构的简单示意如下:
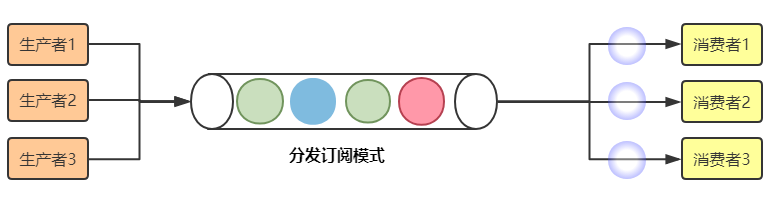
kafka中默认会把同一个消息分发给所有的订阅组(Consumer Group),即分发订阅模式。
如果想要实现队列模式,则把所有的消费者存放在一个Consumer Group内,且该Topic只有这一个组有订阅。kafka不同消费模式的示意如下:
消费方式
消息的消费方式是很多初用者会忽略的,因为简单场景下选择任意一种都是可以正常工作的,而到了生成环境可能就会出问题了。
kafka的消费方式有三种:
- At most once(消息最多被消费一次)
- At least once(消息最少被消费一次)
- Exactly once(消息刚好被消费一次)
前两者所有版本的kafka都支持,可以通过是否自动提交offset来控制。
默认kafka是会自动提交offset的,即属于第一种方式。如果设置为手动提交offset则属于第二种方式。
另外如果需要刚好一次的消费语义,则需要0.11以上的kafka版本。
如果你的版本不是0.11之后的,则可以通过At least once配合下游应用的幂等机制来实现。
API
https://kafka-python.readthedocs.io/en/master/usage.html
获取更多感兴趣的文章,请扫描如下二维码!

以上是关于Nacos必知必会:这些知识点你一定要掌握!的主要内容,如果未能解决你的问题,请参考以下文章