TimescaleDB VS TDengine:写入性能和查询性能是 TDengine 的 1/61/28
Posted 涛思数据TDengine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TimescaleDB VS TDengine:写入性能和查询性能是 TDengine 的 1/61/28相关的知识,希望对你有一定的参考价值。
基于第三方基准性能测试平台 TSBS(Time Series Benchmark Suite) 标准数据集,TDengine 团队分别就 TSBS 指定的 DevOps 中 cpu-only 五个场景,对时序数据库(Time Series Database,TSDB)TimescaleDB 和 TDengine 进行了对比测试。本文将会从写入、存储、查询及资源开销等几大维度为大家汇总分析测试结果。
为确保结果具有可比性,本次测试选用 TimescaleDB 2.6.0 版本。为获得较好的性能,TimescaleDB 需要针对不同的场景设置不同的 Chunk 参数,不同场景下参数的设置如下表所示:
| 场景一 | 场景二 | 场景三 | 场景四 | 场景五 | |
| 设备数目 | 100 | 4000 | 100,000 | 1,000,000 | 10,000,000 |
| Chunk 数目 | 12 | 12 | 12 | 12 | 12 |
| Chunk 持续时间 | 2.58 天 | 8 小时 | 15 分 | 15 秒 | 15 秒 |
| Chunk 内记录数 | 2,232,000 | 11,520,000 | 9,000,000 | 1,500,000 | 15,000,000 |
上述参数的设置,充分参考了下方 TimescaleDB vs. InfluxDB 对比报告中推荐的配置参数设置,以确保写入性能指标的最优化。
TimescaleDB vs. InfluxDB: Purpose Built Differently for Time-Series Data:https://www.timescale.com/blog/timescaledb-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/
关于系统的配置详情、如何一键复现测试结果及详细的测试数据介绍等内容,大家可参考《一键获取测试脚本,轻松验证“TSBS 时序数据库性能基准测试报告”》、《TSBS 是什么?为什么时序数据库 TDengine 会选择它作为性能对比测试平台?》两篇文章,本文便不再赘述。
写入性能最高达到了 TimescaleDB 的 6.7 倍
在 TSBS 全部的 cpu-only 五个场景中,TDengine 写入性能均优于 TimescaleDB。相比 TimescaleDB,TDengine 写入速度最领先的场景是其 6.7 倍(场景二),最少也是 1.5 倍(场景五),而且对于场景四,如果将每个采集点的记录条数由 18 条增加到 576 条,TDengine 写入速度就达到了 TimescaleDB 的 13.2 倍。此外,TDengine 在写入过程中消耗的 CPU 资源和磁盘 IO 开销也是最低的。
不同场景下写入性能对比

不同场景下写入性能的对比(metrics/sec. 数值越大越好)
从上图可以看到,在全部五个场景中,TDengine 的写入性能全面超越 TimescaleDB。在场景二中 TDengine 写入性能最大达到了 TimescaleDB 的 6.74 倍,在差距最小的场景五中,也达到了 TimescaleDB 的 1.52 倍。
写入过程资源消耗对比
但仅凭数据写入速度,并不能全面地反映出 TDengine 和 TimescaleDB 在不同场景下数据写入的整体表现。为此我们以 1,000,000 devices × 10 metrics (场景四)为例,检查数据写入过程中的服务器和客户端的整体负载状况,并以此来对比 TDengine 和 TimescaleDB 在写入过程中服务器/客户端节点的资源占用情况,这里的资源占用主要包括服务器端的 CPU 开销/磁盘 IO 开销和客户端 CPU 开销。
服务端 CPU 开销
写入过程中服务器 CPU 开销
上图展示了在场景四写入过程之中服务器端 CPU 负载状况。可以看到,TDengine 和 TimescaleDB 在返回给客户端写入完成消息以后,都还继续使用服务器的资源进行相应的处理工作,这点上,TimescaleDB 尤为明显,TimescaleDB 在 7x 秒的时候即反馈客户端写入完成,但是其服务器端仍然在调用 CPU 资源进行数据压缩和整理工作,当然整个工作带来的 CPU 负载相对而言并不高,只有其峰值 CPU 开销的一半左右,但是其持续时间相当长,接近净写入时间的 4 倍,远长于 TDengine。TDengine 对服务器的 CPU 需求较小,峰值也仅使用了 17% 左右的服务器 CPU 资源。由此可见,TDengine 独特的数据模型不仅体现在时序数据的写入性能上,也体现在整体的资源开销上。
磁盘 I/O 对比
写入过程中服务器 IO 开销
上图展示了 1,000,000 devices × 10 metrics (场景四)两大系统在数据写入过程中服务器端磁盘写入状态。结合服务器端 CPU 开销表现,可以看到,两大数据库的 IO 动作与 CPU 均呈现出同步活跃状态。
在写入相同规模数据集的情况下,TDengine 在写入过程中对于磁盘写入能力的占用远小于 TimescaleDB,整体写入过程只占用了部分磁盘写入能力(125MiB/Sec. 3000IOPS)。从图上能看到,对于两大数据库来说,数据写入过程中磁盘的 IO 瓶颈是确实存在的,但 TimescaleDB 写入过程对于写入的消耗远超过了 TDengine 对磁盘写入能力的需求。
客户端 CPU 开销
写入过程中客户端 CPU 开销
从上图可以看到,客户端上 TDengine 对 CPU 的需求大于 TimescaleDB ,TDengine 在客户端峰值瞬间达到了 56%,然后快速回落,其在客户端的开销相比于 TimescaleDB 多了 1 倍。但综合服务器与客户端的资源开销来看,TDengine 写入持续时间更短,在系统整体 CPU 开销上 TDengine 仍然具有相当大的优势。
查询性能最高达到了 TimescaleDB 的 28.6 倍
在场景一(只包含 4 天数据)与场景二的 15 个不同类型的查询中,TDengine 的查询平均响应时间全面优于 TimescaleDB,而且在复杂查询上优势更为明显,同时具有最小的计算资源开销。相比 TimeScaleDB,场景一中 TDengine 的查询性能是其 1.1 ~ 28.6 倍,场景二中 TDengine 的查询性能是其 1.2 ~ 24.6 倍。
在查询性能评估部分,我们使用场景一和场景二作为基准数据集。在查询性能评估之前,对于 TimescaleDB,我们采用上文出现的 TimescaleDB vs. InfluxDB 对比报告中推荐配置,设置为 8 个 Chunk ,以确保其充分发挥查询性能。在整个查询对比中,TDengine 数据库的虚拟节点数量(vnodes)保持为默认的 6 个,其他的数据库参数配置为默认值。
4,000 devices × 10 metrics查询性能对比
由于部分类型(分类标准参见 TimescaleDB vs. InfluxDB 对比报告)单次查询响应时间非常短,为了更加准确地测量每个查询场景的较为稳定的响应时间,我们将单个查询运行次数提升到 5,000 次,然后使用 TSBS 自动统计并输出结果,最后结果是 5,000 次查询的算数平均值,使用并发客户端 Workers 数量为 8。下表是场景二 (4,000 设备)下两大数据库的查询性能对比结果。
| 查询分类 | TDengine | TimescaleDB | TimescaleDB/TDengine | |
| Simple Rollups | single-groupby-1-1-1 | 0.94 | 3.27 | 347.87% |
| single-groupby-1-1-12 | 1.92 | 5.07 | 264.06% | |
| single-groupby-1-8-1 | 2.09 | 4.56 | 218.18% | |
| single-groupby-5-1-1 | 1.08 | 3.34 | 309.26% | |
| single-groupby-5-1-12 | 3 | 7.02 | 234.00% | |
| single-groupby-5-8-1 | 2.6 | 9.6 | 369.23% | |
| Aggregates | cpu-max-all-1 | 1.3 | 5.54 | 426.15% |
| cpu-max-all-8 | 3.36 | 23.72 | 705.95% | |
| Double-Rollups | double-groupby-1 | 266.69 | 5467.91 | 2050.29% |
| double-groupby-5 | 446.23 | 10984.63 | 2461.65% | |
| double-groupby-all | 686.42 | 16660.7 | 2427.19% | |
| Thresholds | high-cpu-1 | 2.23 | 4.05 | 181.61% |
| high-cpu-all | 3,508.00 | 4328.64 | 123.39% | |
| Complex Queries | groupby-orderby-limit | 1,527.02 | 12784.92 | 837.25% |
| lastpoint | 133.13 | 755.37 | 567.39% | |
下面我们对每个查询结果做一定的分析说明:
4000 devices × 10 metrics Simple Rollups 查询响应时间 (数值越小越好)
由于 Simple Rollups 的整体查询响应时间非常短,因此制约查询响应时间的主体因素并不是查询所涉及的数据规模,即这一类型查询的瓶颈并非数据规模。但从结果上看,TDengine 仍然在所有类型的查询响应时间上优于 TimescaleDB,具体的数值对比请参见上表。
4000 devices × 10 metrics Aggregates 查询响应时间 (数值越小越好)
通过上图可以看到,在 Aggregates 类型的查询中,TDengine 的查询性能相比 TimescaleDB 有比较大的优势,其cpu-max-all-8 查询性能是 TimescaleDB 的 6 倍。
4000 devices × 10 metrics Double rollups 查询响应时间 (数值越小越好)
在 Double-rollups 类型查询中, TDengine 同样展现出巨大的性能优势,以查询响应时间来度量,其在 double-groupby-5 和 double-groupby-all 类型下的查询性能均达到了 TimescaleDB 的 24 倍。
4000 devices × 10 metrics Thresholds 查询 high-cpu-1 响应时间 (数值越小越好)
4000 devices × 10 metrics Thresholds 查询 high-cpu-all 响应时间 (数值越小越好)
上面两图展示的是 threshold 类型的查询对比,可以看到,TDengine 的查询响应时间均显著低于 TimescaleDB。在 high-cpu-all 类型的查询上,TDengine 的性能是 TimescaleDB 的 1.23 倍。
4000 devices × 10 metrics Complex queries 查询响应时间 (数值越小越好)
对于 Complex-queries 类型的查询,TDengine 两个查询同样均大幅领先 TimescaleDB。在 lastpoint 查询中TDengine 的查询性能是 TimescaleDB 的 5 倍,在 groupby-orderby-limit 场景中 TDengine 的查询性能是 TimescaleDB 的 8 倍。在时间窗口聚合的查询过程中,针对规模较大的数据集 TimescaleDB 查询性能不佳(double rollups 类型查询),对于 groupby-orderby-limit 类型的查询,TimescaleDB 的性能表现同样不是太好。
资源开销对比
由于部分查询持续时间特别短,因此我们并不能完整地看到查询过程中服务器的 IO/CPU/网络情况。为此我们针对场景二以 Double rollups 类别中的 double-groupby-5 查询为例,执行 1,000 次查询,记录整个过程中 TDengine、TimescaleDB 两个软件系统在查询执行的整个过程中服务器 CPU、内存、网络的开销并进行对比。
查询过程中服务器 CPU 开销
如上图所示,两个系统在整个查询过程中 CPU 的使用均较为平稳。TDengine 在查询过程中整体 CPU 占用约 80%,使用的 CPU 资源最高,TimescaleDB 在查询过程中瞬时 CPU 占用约 38%。由于 TDengine 完成全部查询的时间仅 TimescaleDB 1/20,因此虽然其 CPU 稳定值是 TimescaleDB 的 2 倍多,但整体的 CPU 计算时间消耗只有其 1/10 。
- 服务器内存状况
查询过程中服务器内存情况
如上图所示,在整个查询过程中,TDengine 内存维持在一个相对平稳的状态。而 TimescaleDB 在整个查询过程中内存呈现增加的状态,查询完成后即恢复到初始状态。
- 服务器网络带宽
查询过程中网络占用情况
上图展示了查询过程中两个系统的服务器端上行和下行的网络带宽情况,可以看到,负载状况基本上和 CPU 状况相似。TDengine 网络带宽开销较高,因为在最短的时间内就完成了全部查询,需要将查询结果返回给客户端。TimescaleDB 开销较低,但持续时间长。
100 devices × 10 metrics 查询性能对比
对于场景一(100 devices x 10 metrics),TSBS 的 15 个查询对比结果如下:
| 查询分类 | TDengine | TimescaleDB | TimescaleDB/TDengine | |
| Simple Rollups | single-groupby-1-1-1 | 0.91 | 2.93 | 321.98% |
| single-groupby-1-1-12 | 1.83 | 4.87 | 266.12% | |
| single-groupby-1-8-1 | 2.09 | 4.3 | 205.74% | |
| single-groupby-5-1-1 | 1.03 | 3.19 | 309.71% | |
| single-groupby-5-1-12 | 2.94 | 6.38 | 217.01% | |
| single-groupby-5-8-1 | 2.63 | 5.91 | 224.71% | |
| Aggregates | cpu-max-all-1 | 1.27 | 5.55 | 437.01% |
| cpu-max-all-8 | 3.46 | 22.83 | 659.83% | |
| Double-Rollups | double-groupby-1 | 7.79 | 116.66 | 1497.56% |
| double-groupby-5 | 12.1 | 346.48 | 2863.47% | |
| double-groupby-all | 17.31 | 489.04 | 2825.19% | |
| Thresholds | high-cpu-1 | 2.05 | 3.92 | 191.22% |
| high-cpu-all | 96.75 | 104.68 | 108.20% | |
| Complex Queries | groupby-orderby-limit | 47.48 | 367.4 | 773.80% |
| lastpoint | 3.95 | 17.64 | 446.58% | |
如上表所示,从更小规模的数据集(100 设备)上的查询对比可以看到,整体上 TDengine 同样展现出极好的性能,在全部的查询语句中全面优于 TimescaleDB,部分查询性能超过 TimescaleDB 28 倍。
TimescaleDB 占用的磁盘空间最高达到 TDengine 的 26.9 倍
下图是TDengine 和 TimescaleDB 数据完全落盘以后,比较了两个系统在不同场景下的磁盘空间占用:
磁盘空间占用(数值越小越优)
在磁盘空间的占用上,从上图可以看到,TimescaleDB 在全部五个场景下的数据规模均显著大于 TDengine,并且这种差距随着数据规模增加快速变大。TimescaleDB 在场景四和场景五中占用磁盘空间是 TDengine 的 25.6 倍和 26.9 倍。
写在最后
从上述 TSBS 测试报告中我们可以得出结论,不管是在写入性能、查询性能还是存储性能,TDengine 比 TimescaleDB 都略胜一筹,且不论是服务器的 CPU 还是 IO 抑或是客户端的开销统计,TDengine 均远优于 TimescaleDB。尤其本次性能测试还是基于 Timescale 打造的基准性能测试平台 TSBS 进行的,测试结果的公平公正性可见一斑。
具体到实践上,在八五信息的新能源电力物联网平台项目,曾经使用的数据库便是 TimescaleDB,后面因为种种原因,他们选择应用 TDengine 升级数据架构,关于本次案例的具体信息可以查看《代替 TimescaleDB,TDengine 接管数据量日增 40 亿条的光伏日电系统》。
为了方便大家验证测试结果,本测试报告支持运行测试脚本一键复现,欢迎各位检验。同时,我们也欢迎大家添加 小T vx:tdengine1,加入 TDengine 用户交流群,和更多志同道合的开发者一起探讨数据处理难题。
TimescaleDB 简单试用
TimescaleDB 是一个对于pg进行了改造的时序数据库
安装测试使用docker
安装&&运行
docker run -d --name timescaledb -p 5432:5432 timescale/timescaledb
or 集成postgis
docker run -d --name timescaledb -p 5432:5432 timescale/timescaledb-postgis基本使用
- 连接
我使用可视化工具 postico
- 数据库管理
- 创建数据库
CREATE database dalong;
- 切换登陆
可以使用可视化工具,或者命令行工具
psql -U postgres -h localhost -d dalong
- 创建表
CREATE TABLE "public"."user" (
"id" serial,
"name" text,
PRIMARY KEY ("id")
);创建hypertable
timescaledb 进行pg 管理的抽象处理,也是核型功能,了解memsql 的基本类似,只是memsql 比较直接,不需要进行
关联处理这步
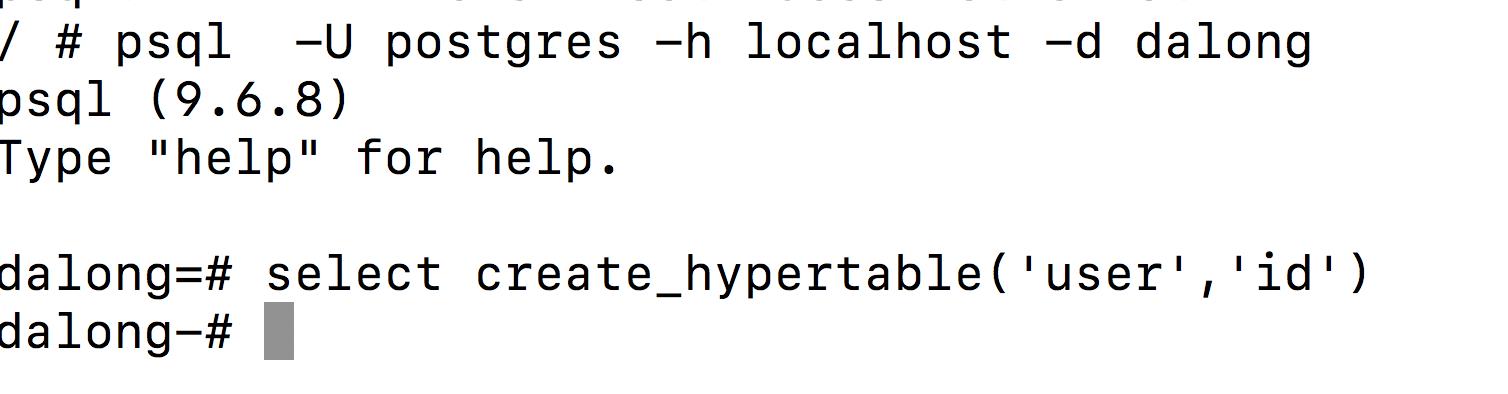
- 创建基本表
- 数据添加
INSERT INTO "user"("id", "name") VALUES(2, \'appdemo\') 从pg 迁移
从上面的简单使用中我们看不出那些不一样的,一切和pg 的使用基本一样
- 操作方法
主要分为同实例,以及不同实例的场景,具体参考https://docs.timescale.com/v0.9/getting-started/migrating-data
操作比较简单,和普通的使用是一样的,只是有一个转换hypertable 的步骤参考资料
https://docs.timescale.com/v0.9/faq
https://docs.timescale.com/v0.9/introduction/timescaledb-vs-postgres
以上是关于TimescaleDB VS TDengine:写入性能和查询性能是 TDengine 的 1/61/28的主要内容,如果未能解决你的问题,请参考以下文章
涛思数据TDengine征稿— ❤️TDEngine 的特点及应用场景❤️
在SpringBoot项目中集成TDengine,并通过SQL对数据进行增删改查
在SpringBoot项目中集成TDengine,并通过SQL对数据进行增删改查