Python进阶:迭代器与迭代器切片
Posted 豌豆花下猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python进阶:迭代器与迭代器切片相关的知识,希望对你有一定的参考价值。
Python进阶:迭代器与迭代器切片
在前两篇关于 Python 切片的文章中,我们学习了切片的基础用法、高级用法、使用误区,以及自定义对象如何实现切片用法(相关链接见文末)。本文是切片系列的第三篇,主要内容是迭代器切片。
迭代器是 Python 中独特的一种高级特性,而切片也是一种高级特性,两者相结合,会产生什么样的结果呢?
1、迭代与迭代器
首先,有几个基本概念要澄清:迭代、可迭代对象、迭代器。
迭代 是一种遍历容器类型对象(例如字符串、列表、字典等等)的方式,例如,我们说迭代一个字符串“abc”,指的就是从左往右依次地、逐个地取出它的全部字符的过程。(PS:汉语中迭代一词有循环反复、层层递进的意思,但 Python 中此词要理解成单向水平线性 的,如果你不熟悉它,我建议直接将其理解为遍历。)
那么,怎么写出迭代操作的指令呢?最通用的书写语法就是 for 循环。
# for循环实现迭代过程
for char in "abc":
print(char, end=" ")
# 输出结果:a b c
for 循环可以实现迭代的过程,但是,并非所有对象都可以用于 for 循环,例如,上例中若将字符串“abc”换成任意整型数字,则会报错: ‘int‘ object is not iterable .
这句报错中的单词“iterable”指的是“可迭代的”,即 int 类型不是可迭代的。而字符串(string)类型是可迭代的,同样地,列表、元组、字典等类型,都是可迭代的。
那怎么判断一个对象是否可迭代呢?为什么它们是可迭代的呢?怎么让一个对象可迭代呢?
要使一个对象可迭代,就要实现可迭代协议,即需要实现__iter__() 魔术方法,换言之,只要实现了这个魔术方法的对象都是可迭代对象。
那怎么判断一个对象是否实现了这个方法呢?除了上述的 for 循环外,我知道还有四种方法:
# 方法1:dir()查看__iter__
dir(2) # 没有,略
dir("abc") # 有,略
# 方法2:isinstance()判断
import collections
isinstance(2, collections.Iterable) # False
isinstance("abc", collections.Iterable) # True
# 方法3:hasattr()判断
hasattr(2,"__iter__") # False
hasattr("abc","__iter__") # True
# 方法4:用iter()查看是否报错
iter(2) # 报错:‘int‘ object is not iterable
iter("abc") # <str_iterator at 0x1e2396d8f28>
### PS:判断是否可迭代,还可以查看是否实现__getitem__,为方便描述,本文从略。
这几种方法中最值得一提的是 iter() 方法,它是 Python 的内置方法,其作用是将可迭代对象变成迭代器 。这句话可以解析出两层意思:(1)可迭代对象跟迭代器是两种东西;(2)可迭代对象能变成迭代器。
实际上,迭代器必然是可迭代对象,但可迭代对象不一定是迭代器。两者有多大的区别呢?
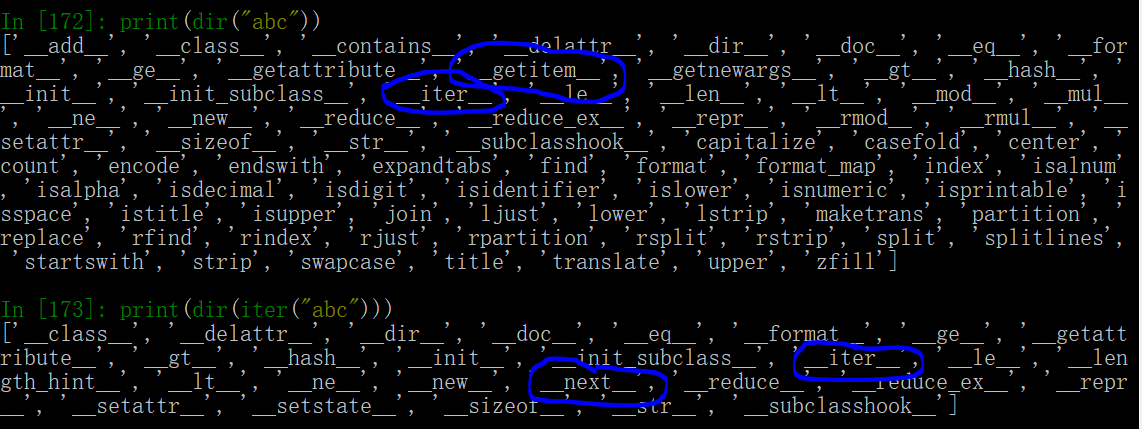
如上图蓝圈所示,普通可迭代对象与迭代器的最关键区别可概括为:一同两不同 ,所谓“一同”,即两者都是可迭代的(__iter__),所谓“两不同”,即可迭代对象在转化为迭代器后,它会丢失一些属性(__getitem__),同时也增加一些属性(__next__)。
首先看看增加的属性 __next__ , 它是迭代器之所以是迭代器的关键,事实上,我们正是把同时实现了 __iter__ 方法 和 __next__ 方法的对象定义为迭代器的。
有了多出来的这个属性,可迭代对象不需要借助外部的 for 循环语法,就能实现自我的迭代/遍历过程。我发明了两个概念来描述这两种遍历过程(PS:为了易理解,这里称遍历,实际也可称为迭代):它遍历 指的是通过外部语法而实现的遍历,自遍历 指的是通过自身方法实现的遍历。
借助这两个概念,我们说,可迭代对象就是能被“它遍历”的对象,而迭代器是在此基础上,还能做到“自遍历”的对象。
ob1 = "abc"
ob2 = iter("abc")
ob3 = iter("abc")
# ob1它遍历
for i in ob1:
print(i, end = " ") # a b c
for i in ob1:
print(i, end = " ") # a b c
# ob1自遍历
ob1.__next__() # 报错: ‘str‘ object has no attribute ‘__next__‘
# ob2它遍历
for i in ob2:
print(i, end = " ") # a b c
for i in ob2:
print(i, end = " ") # 无输出
# ob2自遍历
ob2.__next__() # 报错:StopIteration
# ob3自遍历
ob3.__next__() # a
ob3.__next__() # b
ob3.__next__() # c
ob3.__next__() # 报错:StopIteration
通过上述例子可看出,迭代器的优势在于支持自遍历,同时,它的特点是单向非循环的,一旦完成遍历,再次调用就会报错。
对此,我想到一个比方:普通可迭代对象就像是子弹匣,它遍历就是取出子弹,在完成操作后又装回去,所以可以反复遍历(即多次调用for循环,返回相同结果);而迭代器就像是装载了子弹匣且不可拆卸的枪,进行它遍历或者自遍历都是发射子弹,这是消耗性的遍历,是无法复用的(即遍历会有尽头)。
写了这么多,稍微小结一下:迭代是一种遍历元素的方式,按照实现方式划分,有外部迭代与内部迭代两种,支持外部迭代(它遍历)的对象就是可迭代对象,而同时还支持内部迭代(自遍历)的对象就是迭代器;按照消费方式划分,可分为复用型迭代与一次性迭代,普通可迭代对象是复用型的,而迭代器是一次性的。
2、迭代器切片
前面提到了“一同两不同”,最后的不同是,普通可迭代对象在转化成迭代器的过程中会丢失一些属性,其中关键的属性是 __getitem__ 。在《Python进阶:自定义对象实现切片功能》中,我曾介绍了这个魔术方法,并用它实现了自定义对象的切片特性。
那么问题来了:为什么迭代器不继承这个属性呢?
首先,迭代器使用的是消耗型的遍历,这意味着它充满不确定性,即其长度与索引键值对是动态衰减的,所以很难 get 到它的 item ,也就不再需要 __getitem__ 属性了。其次,若强行给迭代器加上这个属性,这并不合理,正所谓强扭的瓜不甜……
由此,新的问题来了:既然会丢失这么重要的属性(还包括其它未标识的属性),为什么还要使用迭代器呢?
这个问题的答案在于,迭代器拥有不可替代的强大的有用的功能,使得 Python 要如此设计它。限于篇幅,此处不再展开,后续我会专门填坑此话题。
还没完,死缠烂打的问题来了:能否令迭代器拥有这个属性呢,即令迭代器继续支持切片呢?
hi = "欢迎关注公众号:Python猫"
it = iter(hi)
# 普通切片
hi[-7:] # Python猫
# 反例:迭代器切片
it[-7:] # 报错:‘str_iterator‘ object is not subscriptable
迭代器因为缺少__getitem__ ,因此不能使用普通的切片语法。想要实现切片,无非两种思路:一是自己造轮子,写实现的逻辑;二是找到封装好的轮子。
Python 的 itertools 模块就是我们要找的轮子,用它提供的方法可轻松实现迭代器切片。
import itertools
# 例1:简易迭代器
s = iter("123456789")
for x in itertools.islice(s, 2, 6):
print(x, end = " ") # 输出:3 4 5 6
for x in itertools.islice(s, 2, 6):
print(x, end = " ") # 输出:9
# 例2:斐波那契数列迭代器
class Fib():
def __init__(self):
self.a, self.b = 1, 1
def __iter__(self):
while True:
yield self.a
self.a, self.b = self.b, self.a + self.b
f = iter(Fib())
for x in itertools.islice(f, 2, 6):
print(x, end = " ") # 输出:2 3 5 8
for x in itertools.islice(f, 2, 6):
print(x, end = " ") # 输出:34 55 89 144
itertools 模块的 islice() 方法将迭代器与切片完美结合,终于回答了前面的问题。然而,迭代器切片跟普通切片相比,前者有很多局限性。首先,这个方法不是“纯函数”(纯函数需遵守“相同输入得到相同输出”的原则,之前在《来自Kenneth Reitz大神的建议:避免不必要的面向对象编程》提到过);其次,它只支持正向切片,且不支持负数索引,这都是由迭代器的损耗性所决定的。
那么,我不禁要问:itertools 模块的切片方法用了什么实现逻辑呢?下方是官网提供的源码:
def islice(iterable, *args):
# islice(‘ABCDEFG‘, 2) --> A B
# islice(‘ABCDEFG‘, 2, 4) --> C D
# islice(‘ABCDEFG‘, 2, None) --> C D E F G
# islice(‘ABCDEFG‘, 0, None, 2) --> A C E G
s = slice(*args)
# 索引区间是[0,sys.maxsize],默认步长是1
start, stop, step = s.start or 0, s.stop or sys.maxsize, s.step or 1
it = iter(range(start, stop, step))
try:
nexti = next(it)
except StopIteration:
# Consume *iterable* up to the *start* position.
for i, element in zip(range(start), iterable):
pass
return
try:
for i, element in enumerate(iterable):
if i == nexti:
yield element
nexti = next(it)
except StopIteration:
# Consume to *stop*.
for i, element in zip(range(i + 1, stop), iterable):
pass
islice() 方法的索引方向是受限的,但它也提供了一种可能性:即允许你对一个无穷的(在系统支持范围内)迭代器进行切片的能力。这是迭代器切片最具想象力的用途场景。
除此之外,迭代器切片还有一个很实在的应用场景:读取文件对象中给定行数范围的数据。
在《给Python学习者的文件读写指南(含基础与进阶,建议收藏)》里,我介绍了从文件中读取内容的几种方法:readline() 比较鸡肋,不咋用;read() 适合读取内容较少的情况,或者是需要一次性处理全部内容的情况;而 readlines() 用的较多,比较灵活,每次迭代读取内容,既减少内存压力,又方便逐行对数据处理。
虽然 readlines() 有迭代读取的优势,但它是从头到尾逐行读取,若文件有几千行,而我们只想要读取少数特定行(例如第1000-1009行),那它还是效率太低了。考虑到文件对象天然就是迭代器 ,我们可以使用迭代器切片先行截取,然后再处理,如此效率将大大地提升。
# test.txt 文件内容
‘‘‘
猫
Python猫
python is a cat.
this is the end.
‘‘‘
from itertools import islice
with open(‘test.txt‘,‘r‘,encoding=‘utf-8‘) as f:
print(hasattr(f, "__next__")) # 判断是否迭代器
content = islice(f, 2, 4)
for line in content:
print(line.strip())
### 输出结果:
True
python is a cat.
this is the end.
3、小结
好啦,今天的学习就到这,小结一下:迭代器是一种特殊的可迭代对象,可用于它遍历与自遍历,但遍历过程是损耗型的,不具备循环复用性,因此,迭代器本身不支持切片操作;通过借助 itertools 模块,我们能实现迭代器切片,将两者的优势相结合,其主要用途在于截取大型迭代器(如无限数列、超大文件等等)的片段,实现精准的处理,从而大大地提升性能与效率。
切片系列:
相关链接:
《来自Kenneth Reitz大神的建议:避免不必要的面向对象编程》
《给Python学习者的文件读写指南(含基础与进阶,建议收藏)》
-----------------
本文原创并首发于微信公众号【Python猫】,后台回复“爱学习”,免费获得20+本精选电子书。
以上是关于Python进阶:迭代器与迭代器切片的主要内容,如果未能解决你的问题,请参考以下文章