视频字幕整理Practical Stereo Matching via Cascaded Recurrent Network With Adaptive Correlati
Posted chesstime
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频字幕整理Practical Stereo Matching via Cascaded Recurrent Network With Adaptive Correlati相关的知识,希望对你有一定的参考价值。
字幕整理:
Hello everyone, we present a novel practical stereo matching method via cascaded recurrent network with adaptive correlation.
Stereo matching is a classical research topic of computer vision and it has a wide range of applications in the real world including autonomous driving, augmented reality 3d model, reconstruction simulated bokeh rendering on smartphones and so on. The goal of stereo matching given a pair of rectified images is to compute the displacement between two corresponding pixels namely disparity.
To handle various scenes in everyday consumer photography we are faced with some major obstacles:
- Firstly it is difficult to recover intricate details of fine structures, especially in high-resolution images.
- Secondly perfect rectification is hard to obtain for real-world stereo image pairs, due to inconsistent camera modules making stereo estimation even harder.
- Thirdly repetitive texture or regions with occlusion are still typical hard cases for stereo matching
- Finally it is hard to obtain accurate ground truth disparities in real-world scenes
Next we will describe how we handle such difficulties, we propose a novel model structure to extract fine details and overcome non-ideal rectification, and we design a new synthetic stereo data set to boost the performance for various hard cases. Unlike existing algorithms we only match points in small local windows, instead of computing global correlation for every pixel, specifically we propose an adaptive group correlation layer AGCL to reduce matching ambiguity to deal with non-ideal stereo rectification cases. We adopt a 2d and 1d alternate local search strategy, with learned additional offsets. We use an adaptive search window for correlation pairs generation similar to deformable convolution. In addition we split the feature map into groups to compute group wise correlation.
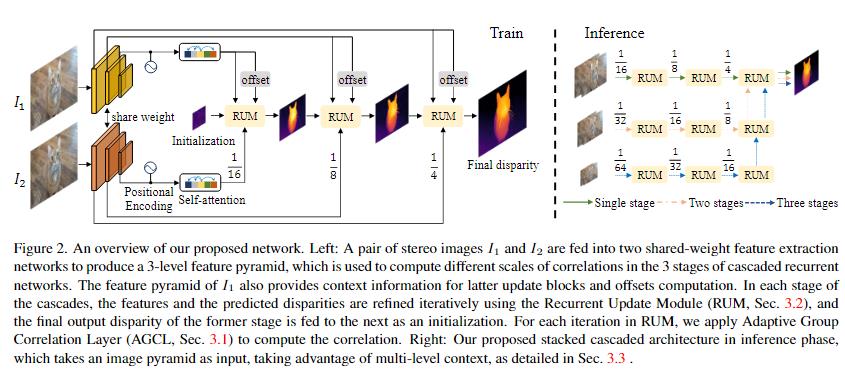
This is an overview of our proposed network. A pair of images are fed into two shared weight feature extractors to produce a three-level feature pyramid , which is used to compute different scales of correlations. In each stage of the cascades, the features and the predicted disparities are refined iteratively using the recurrent update module rum with an exponentially weighted multi-level loss as supervision.
For each iteration in rum, the group blocks update current prediction and feed it to the AGCL with learned offsets. This structure well preserves the fine-detailed object edges and alleviates ambiguity in non-ideal rectification cases as well as on non-texture areas.
During inference phase downsampling is necessary for high-res images to enlarge the receptive field, which may result in deterioration for features of small objects with large displacement . To solve this problem we designed a stacked cascaded architecture for inference to take advantage of multi-level context for a specific stage of the stacked cascades, denoted as rows in the figure all the rums in that stage will be used followed by the last rum and next stage of higher resolution.All stages of the stacked cascades share the same weight during training so no
Fine tuning is needed compared to previous synthetic data sets. Our data set devotes extra attention to challenging cases in real-world scenes. We collect over 40 000 3d models of objects with various shapes as the basic source content with textures from real world as the surface and we place different types of lights with random color and luminance at random position . Furthermore to cover different baseline settings. We ensure the disparities distribute smoothly within a wide range.
So far our method ranks first on both middlebury and eth 3d benchmarks and achieves competitive performance on KITTI among published methods . Our method not only outperforms existing state-of-the-art methods by a notable margin, but also exhibits high quality details and fine structures. Here we show qualitative comparisons for different methods on holopex 50k dataset. Our method has a significant advantagein thin objects like cat whiskers and wire meshes.
We also achieve better performance on textureless areas like walls and windows. we also simulate common disturbances in practical scenes including image blur color transform spatial distortion and so on. The results demonstrate that our method is more robust than others.
Here we show more results on holopex 50k. Our method achieves high accuracy for arbitrary scenes and preserves superior details for various fine-structured objects such as net wires and wheel spokes.
More results can be found on our paper and supplementary material
Thank you for listening for more information about our code and data sets, please visit our website
字幕:
hello everyone we present a novel 大家好,我们提出了一种新颖 practical stereo matching method via 实用的立体匹配方法,通过 cascaded recurrent network with adaptive 自适应相关的级联循环网络进行 correlation stereo matching is a classical research 立体匹配, topic of computer vision and it has a 这是计算机视觉的经典研究课题, wide range of applications in the real 在现实世界中具有广泛的应用, world including autonomous driving 包括自动驾驶、 augmented reality 3d model 增强现实、3D 模型 reconstruction simulated bokeh rendering 重建、模拟散景渲染 on smartphones and so on 在智能手机等上, the goal of stereo matching given a pair 给定一对 of rectified images is to compute the 校正后的图像,立体匹配的目标是计算 displacement between two corresponding 两个相应像素之间的位移, pixels namely disparity 即视差, to handle various scenes in everyday 以处理日常消费摄影中的各种场景, consumer photography we are faced with 我们首先面临 some major obstacles 一些主要障碍, firstly it is difficult to recover 很难恢复 intricate details of fine structures 复杂的细节 精细结构, especially in high-resolution images 尤其是在高分辨率图像中; secondly perfect rectification is hard 其次,由于相机模块不一致,很难 to obtain for real-world stereo image 获得真实世界立体图像对的完美 pairs due to inconsistent camera modules 校正,这 making stereo estimation even harder 使得立体估计更加困难; thirdly repetitive texture or regions 第三,重复纹理或 with occlusion are still typical hard 遮挡区域仍然是 cases for stereo matching 立体匹配的典型困难案例。 finally it is hard to obtain accurate ground truth disparities in real-world 在现实世界场景中很难获得准确的地面实况差异 scenes next we will describe how we handle such 接下来我们将描述我们如何处理这些 difficulties we propose a novel model 困难我们提出了一种新颖的模型 structure to extract fine details and 结构来提取精细细节并 overcome non-ideal rectification and we 克服非理想校正我们 design a new synthetic stereo data set 设计了一个新的合成立体数据集 to boost the performance for various 来提高 与 hard cases unlike existing algorithms we only match 现有算法不同的各种困难情况的性能我们只匹配 points in small local windows instead of 小局部窗口中的点而不是 computing global correlation for every 计算每个像素的全局相关性 pixel specifically we propose an adaptive 特别是我们提出了一个自适应 group correlation layer agcl to reduce 组相关层 agcl 来减少 matching ambiguity to deal with 匹配歧义以处理 non-ideal stereo rectification cases we 非理想立体校正情况我们 adopt a 2d and 1d alternate local search 采用 2d 和 1d 替代局部搜索 strategy 策略 with learned additional offsets we use 与学习的额外偏移我们使用 an adaptive search window for 自适应搜索窗口来 correlation pairs generation similar to 生成类似于 deformable convolution 可变形卷积的相关对 in addition we split the feature map 此外,我们将特征映射分成 into groups to compute group wise 组以计算组 correlation 相关性 this is an overview of our proposed 这是我们提出的网络的概述 network a pair of images are fed into 一对图像 被馈送到 two shared weight feature extractors to 两个共享权重特征提取器以 produce a three-level feature pyramid 产生一个三级特征金字塔, which is used to compute different 该金字塔用于计算级联的每个阶段中不同 scales of correlations 比例的相关性使用具有指数加权的循环 in each stage of the cascades the features and the predicted disparities are refined iteratively using the recurrent update module rum with an 更新模块 rum 迭代 exponentially weighted multi-level loss 地细化特征和预测的差异 多级损失 as supervision for each iteration in rum the group 作为 rum 中每次迭代的监督 group blocks update current prediction and blocks 更新当前预测并将 feed it to the agcl with learned offsets 其提供给具有学习偏移量的 agcl this structure well preserves the 这种结构很好地保留了 fine-detailed object edges and 精细的对象边缘并 alleviates ambiguity in non-ideal 减轻了非理想 rectification cases as well as on 校正情况下以及非理想校正情况下的歧义 - non-texture areas during inference phase downsampling is 推理阶段下采样期间的纹理区域 necessary for high-res images to enlarge 对于高分辨率图像来说是必要的,以扩大 the receptive field which may result in 感受野,这可能会导致具有 deterioration for features of small objects with large displacement 大位移的小物体的特征恶化, to solve this problem we designed a 为了解决这个问题,我们设计了一个 stacked cascaded architecture for 堆叠级联架构来 inference to take advantage of 推理,以利用 multi-level context 多 for a specific stage of the stacked 堆叠级联的特定阶段的级别上下文 cascades denoted as rows in the figure 在图中表示为行 all the rums in that stage will be used 该阶段的所有朗姆酒将被使用, followed by the last rum and next stage 然后是最后一个朗姆酒和 of higher resolution 更高分辨率的下一阶段 all stages of the stacked cascades share 堆叠级联的所有阶段 the same weight during training so no 在训练期间共享相同的权重所以没有 fine tuning is needed compared to previous synthetic data sets 与以前的合成数据集相比,需要进行微调 our data set devotes extra attention to 我们的数据集特别关注 challenging cases in real-world scenes 现实世界场景中具有挑战性的案例 we collect over 40 000 3d models of 我们收集了超过 40,000 个 objects with various shapes as the basic 具有各种形状的物体 3d 模型作为基本 source content with textures from real 源内容,以来自现实 world as the surface and we place 世界的纹理作为表面和 我们在随机位置放置 different types of lights with random 具有随机颜色和亮度的不同类型的灯, color and luminance at random position furthermore to cover different baseline 进一步覆盖不同的基线 settings we ensure the disparities 设置,我们确保视差 distribute smoothly within a wide range 在广泛范围内平滑分布,到目前为止, so far our method ranks first on both 我们的方法在 middlebury and eth 3d benchmarks and middlebury 和 eth 3d 基准测试中均排名第一,并 achieves competitive performance on kidi 在 kidi 上取得了具有竞争力的性能 among published methods 已发布的方法 our method not only outperforms existing 我们的方法不仅以显着优势优于现有的 state-of-the-art methods by a notable 最先进方法, margin but also exhibits high quality 而且还展示了高质量的 details and fine structures 细节和精细结构 here we show qualitative comparisons for 我们 different methods on holopex 50k dataset 在 holopex 50k 数据集上展示了不同方法的定性比较 our method has a significant advantage 我们的方法 in thin objects like cat whiskers and 在薄物体上具有显着优势 像猫须和 wire meshes 金属丝网一样, we also achieve better performance on 我们在墙壁和窗户等无纹理区域也取得了更好的性能 textureless areas like walls and windows we also simulate common disturbances in 我们还模拟了实际场景中的常见干扰, practical scenes including image blur 包括图像模糊 color transform spatial distortion and 颜色变换空间失真等 so on the results demonstrate that our 结果表明我们的 method is more robust than others 方法比我们展示的其他方法更稳健 here we show more results on holopex 50k holopex 50k 上的更多结果 our method achieves high accuracy for 我们的方法实现了 arbitrary scenes and preserves superior 任意场景的高精度,并保留了 details for various fine-structured 各种精细结构 objects such as net wires and wheel 对象(如网线和轮辐)的卓越细节 spokes more results can be found on our paper 更多结果可以在我们的论文 and supplementary material 和补充材料中找到 thank you for listening for more 感谢您收听 information about our code and data sets 有关我们的更多信息 代码和数据集 please visit our website 请访问我们的网站
如何把字幕和视频合成到一个文件?
不需要重新压制吧?
可以使用【格式工厂】来将字幕和视频合成,具体方法为:
1.首先打开下载安装好的【格式工厂】,然后点击软件首页的【视频】开始选择需要加入字幕的视频文件。

2.接着在弹出的文件选择窗口选择需要处理的视频。(这里以处理一个【.avi】视频文件为例,其他视频文件处理方法相同)

3.成功添加视频文件后,点击【输出配置】开始为视频文件添加字幕文件。

4.在输出配置的菜单选项中,选择【附加字幕】,然后选择好字幕文件的存放文件。

5.选择好视频和字幕文件后返回软件的首页,点击【开始】按钮开始视频和字幕的合成。

6.文件的合成需要一定的时间,等待页面上提示【完成】则成功将视频和字幕合成为一个视频文件。此时视频是带有字幕显示的。

ffmpeg安装:
sudo apt-get install ffmpeg
字幕文件转换
字幕文件有很多种,常见的有 .srt , .ass 文件等,下面使用FFmpeg进行相互转换。
1、将.srt文件转换成.ass文件
ffmpeg -i subtitle.srt subtitle.ass
2、将.ass文件转换成.srt文件
ffmpeg -i subtitle.ass subtitle.srt
3、集成字幕,选择播放
这种字幕集成比较简单,播放时需要在播放器中选择相应的字幕文件。
ffmpeg -i input.mp4 -i subtitles.srt -c:s mov_text -c:v copy -c:a copy output.mp4
4、嵌入SRT字幕到视频文件
单独SRT字幕
字幕文件为subtitle.srt
ffmpeg -i video.avi -vf subtitles=subtitle.srt out.avi
5、嵌入在MKV等容器的字幕
将video.mkv中的字幕(默认)嵌入到out.avi文件
ffmpeg -i video.mkv -vf subtitles=video.mkv out.avi
6、将video.mkv中的字幕(第二个)嵌入到out.avi文件
ffmpeg -i video.mkv -vf subtitles=video.mkv:si=1 out.avi
7、嵌入ASS字幕到视频文件
ffmpeg -i video.avi -vf "ass=subtitle.ass" out.avi 参考技术C
手机上有几个,我自己用来做视频字幕,还没有水印,特别好:导入视频,边播放边在合适位置输入字幕,然后一键导出,就是一体的了
InShot、VUE
以上是关于视频字幕整理Practical Stereo Matching via Cascaded Recurrent Network With Adaptive Correlati的主要内容,如果未能解决你的问题,请参考以下文章