ThreadLocal 的原理讲述 + 基于ThreadLocal实现MVC中的M层的事务控制
Posted TheMagicalRainbowSea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadLocal 的原理讲述 + 基于ThreadLocal实现MVC中的M层的事务控制相关的知识,希望对你有一定的参考价值。
ThreadLocal 的原理讲述 + 基于ThreadLocal实现MVC中的M层的事务控制

- ThreadLocal 的原理讲述 + 基于ThreadLocal实现MVC中的M层的事务控制
- 每博一文案
- 1. ThreadLocal 给概述
- 2. 抛砖引玉——>ThreadLocal
- 3. ThreadLocal 的模拟编写
- 4. ThreadLocal 源码原理分析
- 6. ThreadLocal 注意移除数据
- 7. ThreadLocal 内存泄漏
- 8. 正确的使用ThreadLocal
- 9. ThreadLocal 常见使用场景
- 10. 案例:MVC三层架构 + 面向接口编程 + ThreadLocal 事务处理实:现用户转账功能的优化
- 11. ThreadLocal与Synchronized的区别
- 12. ThreadLocal与Thread,ThreadLocalMap之间的关系
- 13. 总结:
- 14. 最后:
每博一文案
生活不是努力了就可以变好的,喜欢做的事情也不是轻易就可以做的。以前总听别人说,
坚持就好了,努力就好了,都会好的,可是真的做起来压根就不是这样。这种时候要怎么办?
这种时候还能轻易地相信时间吗?
我总是一时间不知道怎么回答:直到今天我决定记录这些日子的生活时,直到我写完以上的文字时,我
脑海里才出现了一个清晰的答案。四个字:尽力而为。
我想这样的。世事无常,分道扬镳,生老病死,我们常常没法得偿所愿。
然而我们都必须尽力而为。
我觉得挺好的:把眼前的事情做好就行了,路都是走着走着才知道能走到哪里的。
越是焦虑,就越是要回到生活里去。因为身处迷雾中本就很难找到方向,能看见的也就
眼前的五米,那就五米五米地一步步走下去。
至于路能走成什么样,又能走去哪里......
走着走着,就都知道了。
但或许其实终点到底是哪里也不是那么重要。
重要的是,我们走了很远的路,最终找到的人,是我们自己。
是哪个可以很好地应对挫折,应对痛苦,应对生活的变故的自己。
是那个依然前行,依然努力,依然能够为了小事而欣喜,为了善良而感动的自己。
是那个终于学会了珍惜的自己,是那个不再害怕平方的自己。
生活如河,自己就是自己的船。
——————卢思浩《你也走了,很远的路吧》
1. ThreadLocal 给概述
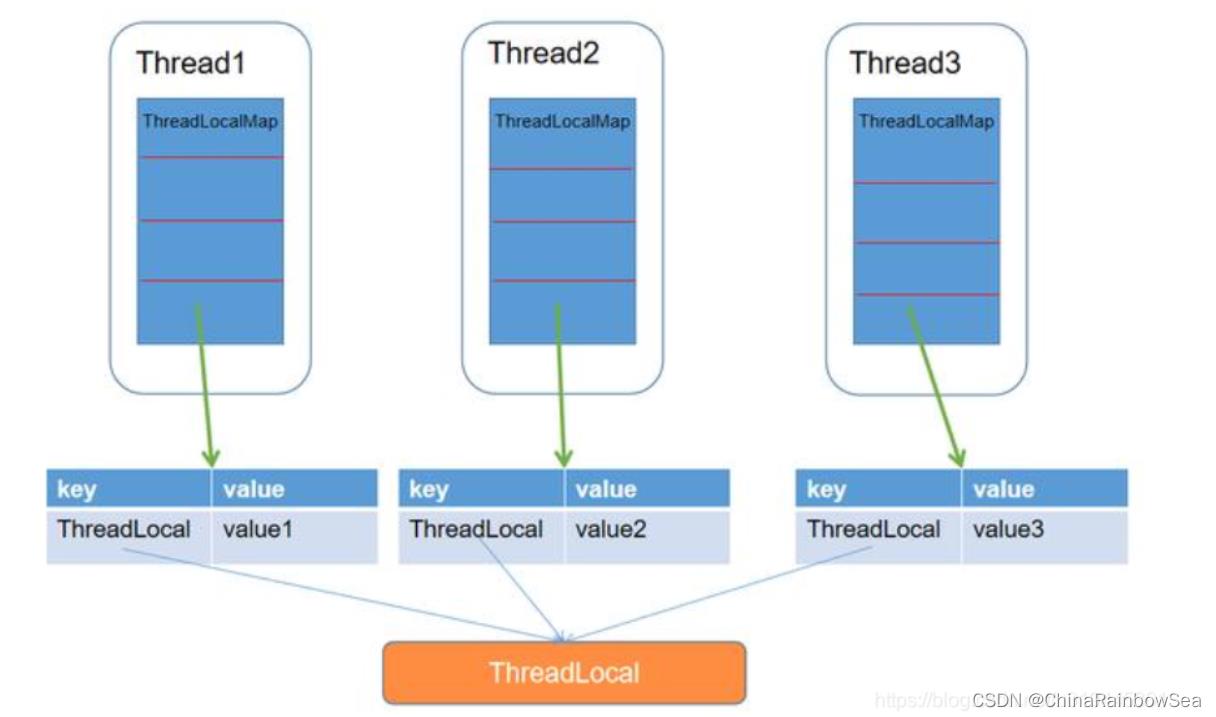
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程 ,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
ThreadLoal 变量,线程局部变量,同一个 ThreadLocal 所包含的对象,在不同的 Thread 中有不同的副本。这里有几点需要注意:
- 因为每个 Thread 内有自己的实例副本,且该副本只能由当前 Thread 使用。这是也是 ThreadLocal 命名的由来。
- 既然每个 Thread 有自己的实例副本,且其它 Thread 不可访问,那就不存在多线程间共享的问题。
ThreadLocal 提供了线程本地的实例。它与普通变量的区别在于,每个使用该变量的线程都会初始化一个完全独立的实例副本。ThreadLocal 变量通常被private static修饰。当一个线程结束时,它所使用的所有 ThreadLocal 相对的实例副本都可被回收。
- 这种变量在多线程环境下访问(通过get和set方法访问)时能保证各个线程的变量相对独立于其他线程内的变量
- 在线程的生命周期内起作用,可以减少同一个线程内多个函数或组件之间一些公共变量传递的复杂度
总的来说,ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景
下图可以增强理解:
2. 抛砖引玉——>ThreadLocal
从上述一篇文章中:我们运用 MVC的架构模式——> 实现了用户转账的功能:
Hash寻址详解
Hash寻址详解
最近在使用ThreadLocal保存上下文信息,原本准备写ThreadLocal原理以及源码详解,然后在偶尔中看到关于ThreadLocal中的hash寻址方式,与HashMap中寻址方式不同,于是决定先写一篇讲述Hash寻址方式的文章,再回头讲述ThreadLocal源码。
Hash
还是得从Hash的定义开始说起,hash的基本思想就是从一条记录中取出一条一个字段称之为key,通过一些固定的过程将key转换为数值,该数值称为散列键,散列键表示存储或者查找项中的位置,其中该数值将在0到n-1的范围,其中n是表中最大的槽数。
将key转换成散列键的固定过程称之为散列函数,如果需要访问hash表,则需要使用该函数。
我们可以用以下散列函数来确定散列键,公式为:

上图中,如果一般key为数值类型,则整除槽数作为散列值一般是一个比较合理的选择,但是并不是所有的key都是数值类型,也有字符串类型之类的,当然这种也是也办法的,根据key获取ASCII值,或者使用key做一个变换运算等等,都可以解决这个问题。
但在上图中仍然有个显而易见的问题就是并不是每个元素都是能算到一个独一无二的散列值,有可能多个key的散列值均是一样,这时候该如何解决这个问题,这种情况就叫做碰撞。
在发生这种碰撞的情况下,一般来说就是两个方法。
- 链表
- 线性探针
一般而言均是采用上述两种简单办法,当然还有稍微复杂一点,就是二次探针与双重哈希,这个在上述方案讲完后再来讲述。
链表处理
当哈希发生冲突时,比较简单的办法就是将具有相同hash值的元素放在同一个链表中,同时hash表槽中将不再存储对应hash值元素,而是存储链表地址,如下图:

在计算出hash值后,如果hash表槽中对应槽已经是链表地址,那么则遍历链表寻找与key相同的元素,如果key相同则返回,否则返回null,如果是插入操作,则进行插入即可,一般是将当前元素放在链表的表头,这样操作时间复杂度为o(1),不需要再遍历到队尾才进行插入,HashMap在进行插入操作时就是用的该方法。
线性探测处理
上述是使用数组加链表的形式来处理hash冲突,也可以不使用链表的方法来处理hash冲突,全部元素都在同一个数组里面的处理方法,这就是线性探测,当数组中数据并没有满的时候,此时发生hash碰撞,则寻找当前碰撞位置的下一个可用位置,如果下一个可用位置处没有数据则占用该位置处用于存放元素,如果不可用则继续向下寻找下一个可用位置,如果到了数组的末端,仍然没有空闲节点,则将指针重置到数组队首重新寻找空闲节点,如果到到碰撞点仍未找到空闲节点,则数组已满,需要进行扩容处理,线性探测如下:

当然,如果在发生hash冲突,解决冲突后,会形成一个连续的数据块,在这块区域内多个元素的hash值均相同,那么在此时如果有新插入的元素计算出的hash值也是与数据块中的相同,那么就有可能要进行多次寻找空闲节点来解决冲突。
二次线性探测
使用线性探针处理hash碰撞会带来一个问题,就是多个相同hash值的元素会聚集到一起,这样就会导致后续如果有相邻元素被计算出来时,需要寻找空闲节点的时间就比之前大大增长,那么此时就需要考虑将聚集在一起的元素进行打散,这就是二次线性探测的由来。
使用二次探测时,并不是每次都是移动一个点,而是从碰撞点向下寻找,直至不碰撞为止,此时不碰撞时移动步数记作为i,如果使用二次线性探测的方式避免hash碰撞,则移动步数为i^2,如下图:

二次线性探测有个限制就是,如果当表中有一半的位置已经被填满以后,就很难找到一个新的空位用来填充,需要对数组进行扩容。
双重hash
解决冲突的还有一个办法就是在当hash后的结果发生碰撞时,对第一次的hash结果进行第二次hash,第二次hash后的结果即为该元素将要插入的点。
一般来说,第二次hash方法许多都是采用使用一值减去第一次哈希结果,即为第二次点位置,即为:Hash2(key) = R - ( key % R ) ,其中R一般为小于hash表大小的一个素数,具体如下图:

以上是关于ThreadLocal 的原理讲述 + 基于ThreadLocal实现MVC中的M层的事务控制的主要内容,如果未能解决你的问题,请参考以下文章