大模型知识点
Posted 15375357604
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大模型知识点相关的知识,希望对你有一定的参考价值。
参数有效化微调(Parameter Efficient Fine Tuning,PEFT)
参数有效化微调大致可以分为三个方法:Adapter、Prompt、LoRA

LORA:
LoRA的思想也很简单,在自注意力层的四个权重矩阵Wq, Wk, Wv, Wo的所有或者部分旁边增加一个旁路(如文中表示在GPT3上只有Wq和Wv加了旁路),做一个降维再升维的操作,来模拟所谓的 intrinsic rank(文中表示把LoRA应用在前馈神经网络层或者RNN等结构的研究留给后续研究工作) 。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的输出叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full fine-tuning的过程。并且,full fine-tuning可以被看做是LoRA的特例(当r等于k时)。实验结果表明基于LoRA的方法效果不亚于甚至能超过微调。
总结,基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的。GPT的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到四两拨千斤的效果。
技术创新:全球首个知识增强千亿大模型是怎样炼成的?
近日,百度与鹏城自然语言处理联合实验室重磅发布鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan),该模型是全球首个知识增强的千亿AI大模型,也是目前为止全球最大的中文单体模型。
基于业界领先的鹏城实验室算力系统“鹏城云脑Ⅱ”和百度飞桨深度学习平台强强练手,鹏城-百度·文心模型参数规模超越GPT-3达到2600亿,致力于解决传统AI模型泛化性差、强依赖于昂贵的人工标注数据、落地成本高等应用难题,降低AI开发与应用门槛。目前该模型在60多项任务取得最好效果,并大幅刷新小样本学习任务基准。
百度文心大模型官网:
文心_文心大模型_百度文心-产业级知识增强大模型
鹏城-百度·文心模型如何诞生?
鹏城-百度·文心基于百度知识增强大模型ERNIE 3.0全新升级,模型参数规模达到2600亿,相对GPT-3的参数量提升50%。
在算法框架上,该模型沿袭了ERNIE 3.0的海量无监督文本与大规模知识图谱的平行预训练算法,模型结构上使用兼顾语言理解与语言生成的统一预训练框架。为提升模型语言理解与生成能力,研究团队进一步设计了可控和可信学习算法。
在训练上,结合百度飞桨自适应大规模分布式训练技术和“鹏城云脑Ⅱ”算力系统,解决了超大模型训练中多个公认的技术难题。在应用上,首创大模型在线蒸馏技术,大幅降低了大模型落地成本。
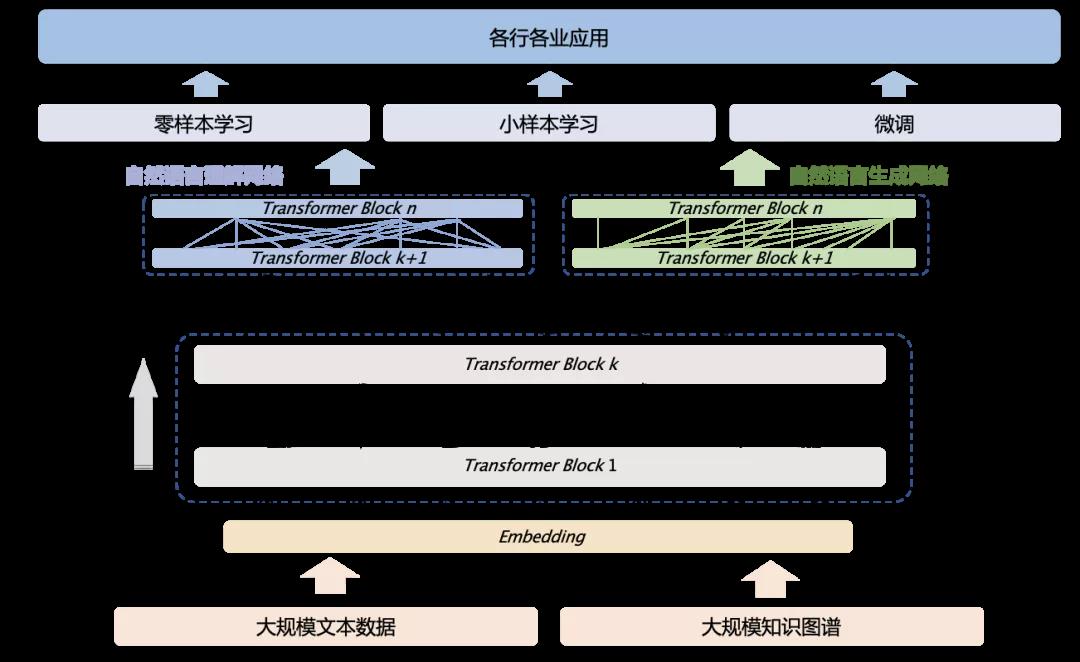
鹏城-百度·文心模型结构图
鹏城-百度·文心的可控和可信学习算法
在算法设计上,为进一步提升模型语言理解能力以及写小说、歌词、诗歌、对联等文学创作能力,研究团队提出了可控学习和可信学习算法。在可控学习方面,通过将模型预测出的文本属性和原始文本进行拼接,构造从指定属性生成对应文本的预训练数据,模型通过对该数据的学习,实现不同类型的零样本生成能力。用户可以将指定的体裁、情感、长度、主题、关键词等属性自由组合,无需标注任何样本,便可生成不同类型的文本。
在可信学习方面,针对模型生成结果与真实世界的事实一致性问题,鹏城-百度·文心通过自监督的对抗训练,让模型学习区分数据是真实的还是模型伪造的,使得模型对生成结果真实性具备判断能力,从而让模型可以从多个候选中选择最可靠的生成结果,显著提升了生成结果的可信度。
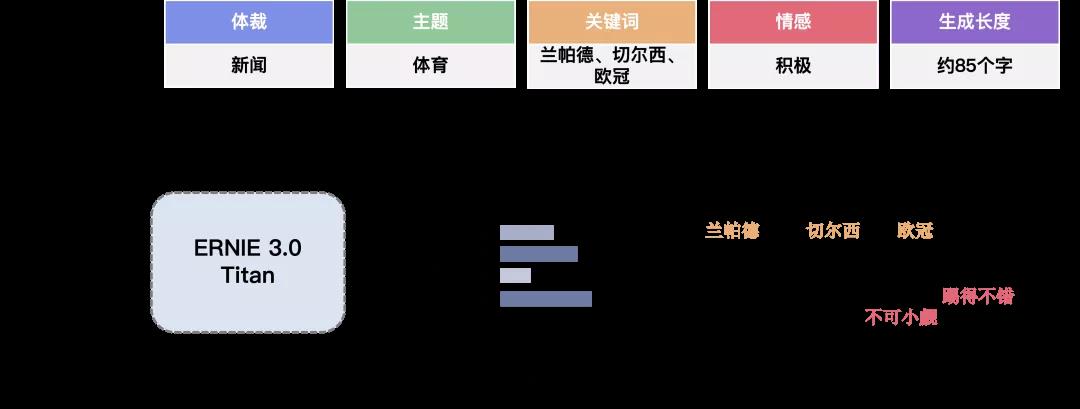
高可信的可控生成预训练
高性能集群支撑鹏城-百度·文心训练
鹏城-百度·文心基于百度百舸集群初始化,并基于“鹏城云脑II”高性能集群训练。“鹏城云脑Ⅱ”由鹏城实验室联合国内优势科研力量研发,是我国首个国产E级AI算力平台。
“鹏城云脑Ⅱ”于去年11月和今年7月接连两次夺得IO 500总榜和10节点榜的双料世界冠军。今年5月,“鹏城云脑Ⅱ”在“MLPerf training V1.0”基准测试中取得了自然语言处理领域模型性能第一名和图像处理领域模型性能第二名的好成绩。今年11月,“鹏城云脑”继去年取得首届AIPerf 500榜单冠军后,再次荣获排行榜冠军。多次在相关领域国际权威竞赛中斩获头名,充分展现了其优越的智能计算性能和软硬件系统协同水平,也为鹏城-百度·文心强大技术能力奠定基础。
飞桨自适应大规模分布式训练和推理 “保驾护航”
超大规模模型的训练和推理给深度学习框架带来很大考验,需要利用大规模集群分布式计算才能在可接受时间内完成训练或推理的计算要求,同时面临着模型参数量单机无法加载、多机通信负载重、并行效率低等难题。早在今年4月,国产深度学习框架百度飞桨发布了4D混合并行技术,可支持千亿参数模型的高效分布式训练。
但鹏城-百度·文心的训练任务给飞桨带来全新挑战:一方面,鹏城-百度·文心的模型结构设计引入诸多小形状的张量计算,导致层间计算量差异较大,流水线负载不均衡;另一方面,“鹏城云脑II”的自有软件栈需要深度学习框架高效深度适配,才能充分发挥其集群的领先算力优势。
针对以上挑战,并综合考虑当前主流硬件、模型的特点与发展趋势,飞桨设计并研发了具备更强扩展能力的端到端自适应大规模分布式训练架构
*论文链接:https://arxiv.org/abs/2112.02752
该架构可以针对不同的模型和硬件,抽象成统一的分布式计算视图和资源视图,并通过硬件感知细粒度切分和映射功能,搜索出最优的模型切分和硬件组合策略,将模型参数、梯度、优化状态按照最优策略分配到不同的计算卡上,达到节省存储、负载均衡、提升训练性能的目的。
飞桨自适应大规模分布式训练架构使得鹏城-百度·文心的训练性能是传统分布式训练方法2.1倍,并行效率高达90%。此外,为进一步提高模型训练的稳定性,飞桨还设计了容错功能,可以在不中断训练的情况下自动替换故障机器,加强模型训练的鲁棒性。
在推理方面,飞桨基于服务化部署框架Paddle Serving,通过多机多卡的张量模型并行、流水线并行等一系列优化技术,获得最佳配比和最优吞吐。通过统一内存寻址(Unified Memory)、算子融合、模型IO优化、量化加速等方式,鹏城-百度·文心的推理速度得到进一步提升。

飞桨超大模型训练与推理
鹏城-百度·文心超强性能:60多项任务取得最好效果大幅刷新小样本学习任务基准
鹏城-百度·文心究竟效果如何?目前,该模型已在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果。
在行业领域,仅利用少量标注数据甚至无需标注数据,就能解决新场景的任务已成为AI工业化大规模应用的关键。该模型在30余项小样本和零样本任务上均取得了最优成绩,能够实现各类AI应用场景效果的提升,也为产业化规模应用打开了新窗口。

鹏城-百度·文心小样本学习效果

鹏城-百度·文心零样本学习效果
解决应用落地难题:百度团队首创大模型在线蒸馏技术
大模型训练、推理所消耗的资源极其昂贵和密集。Paddle Serving已提供了超大模型的高速推理方案,但为了进一步打造大模型的绿色落地方案,降低大模型应用成本,研究团队提出了大模型在线蒸馏技术。
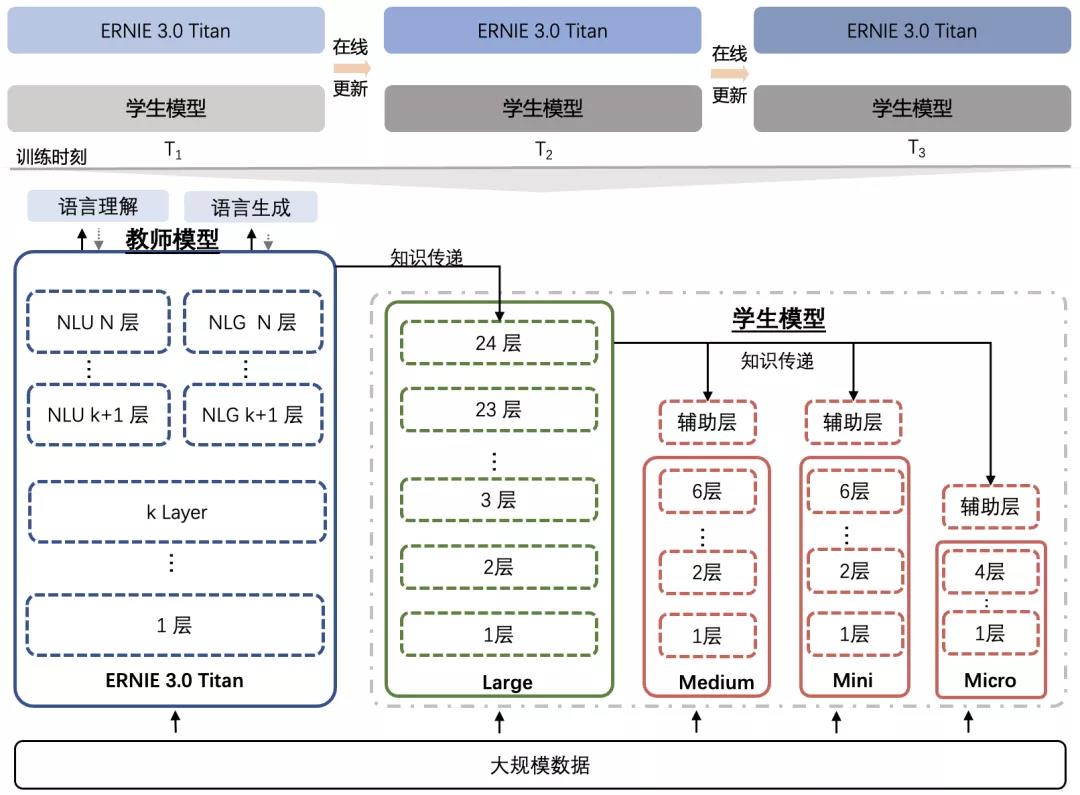
在线蒸馏技术
具体来说,该技术在鹏城-百度·文心学习的过程中周期性地将知识信号传递给若干个学生模型同时训练,从而在蒸馏阶段一次性产出多种尺寸的学生模型。相对传统蒸馏技术,该技术极大节省了因大模型额外蒸馏计算以及多个学生的重复知识传递带来的算力消耗。
这种新颖的蒸馏方式利用了鹏城-百度·文心规模优势,在蒸馏完成后保证了学生模型的效果和尺寸丰富性,方便不同性能需求的应用场景使用。此外,研究团队还发现,鹏城-百度·文心与学生模型尺寸差距千倍以上,模型蒸馏难度极大甚至失效。为此,研究团队引入了助教模型进行蒸馏的技术,利用助教作为知识传递的桥梁以缩短学生模型和鹏城-百度·文心 表达空间相距过大的问题,从而促进蒸馏效率的提升。
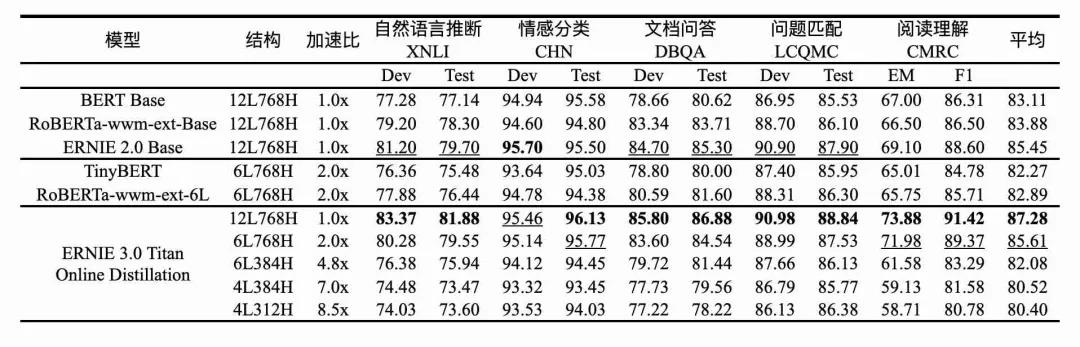
鹏城-百度·文心压缩版模型效果
鹏城-百度·文心在线蒸馏方案的效果非常显著,模型参数压缩率可达99.98%。压缩版模型仅保留0.02%参数规模就能与原有模型效果相当。相比直接训练参数规模是自身2倍的BERT Base模型,鹏城-百度·文心在5项任务准确率上绝对提升了2.5%,而相对于同等规模的RoBERTa Base,准确率则绝对提升了3.4%,验证了鹏城-百度·文心在线蒸馏方案的有效性。
结语
文心ERNIE自2019年诞生至今,在语言理解、文本生成、跨模态语义理解等领域取得多项技术突破,在公开权威语义评测中斩获了十余项世界冠军。2020年,文心ERNIE荣获世界人工智能大会WAIC最高奖项SAIL奖。
目前,文心ERNIE已大规模应用于搜索、信息流、智能音箱等互联网产品,并通过百度智能云输出到工业、能源、金融、通信、媒体、教育等各行各业,助力产业智能化升级。本次发布的鹏城-百度·文心将进一步解决 AI 技术在应用中缺乏领域和场景化数据等关键难题,降低门槛,加快人工智能大规模产业应用。
以上是关于大模型知识点的主要内容,如果未能解决你的问题,请参考以下文章