Python[08]基于CGI的Web开发
Posted diaomaoxiaoge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python[08]基于CGI的Web开发相关的知识,希望对你有一定的参考价值。
开始web开发前,先来认识几个概念:
CGI(Common Gateway Interface):称为通用网关接口,是一个Internet标准。
官方解释是生成动态内容的过程,这个动态过程大概是:web服务器先找到所要执行的程序,然后执行找到的程序,再捕获程序的输出作为web响应,把它发回还在等待的web浏览器。这个程序被叫做CGI脚本。
MVC(Model-View-Controller):模型-视图-控制器模式,这是设计web应用应遵循的模式,他有助于把代码分解成易于管理的功能模块或者组件。
模型:存储(以及有时处理)web应用数据的代码
试图:格式化和显示web应用用户界面的代码
控制器:将wenbb应用“粘合”在一起并提供业务逻辑的代码
下面正式开始使用python编写一个web应用
需求是:Kelly教练想要把他带的运动员的成绩放在网页上,方便大家及时查询成绩
1、首先对运动员的成绩进行数据建模
因为计算机处理程序时,只能识别和应用二进制格式的数据,所以在启动web应用时,先把要用到的文本文件转换成数据对象实例。比如,这里需要先把教练的各学员的.txt数据,转换成对象实例存储在字典里,这样在web运行时,字典里的数据就可以直接被web应用所使用。
import pickle from athletelist import AthleteList def get_coach_date(filename): #读取教练的数据文件 try: with open(filename) as f: date=f.readline() templ=date. strip().split(".") return (AthleteList(templ.pop(0),templ.pop(0),templ)) except IOError as ioerror: print("File error:"+str(ioerror)) return(None) def put_to_store(files_list): #将各学员的文本文件写入字典,方便web应用运行 all_athletes={} for each_file in files_list: ath=get_coach_date(each_file) all_athletes[ath.name]=ath #将文件中的数据迭代到字典中,以运动员的名字作为字典的键 try: with open("athletes.pickle","wb") as athf: pickle.dump(all_athletes,athf) #pickle.dump()函数是将数据保存到磁盘的意思 except IOError as ioerror: print("File error(put_to_store):"+str(ioerror)) return(all_athletes) def get_from_store(): #获取存入字典中的学员成绩数据 all_athletes={} try: with open("athletes.pickle","rb") as athf: pickle.load(all_athletes,athf) #pickle.load()函数是从磁盘恢复数据 except IOError as ioerror: print("File error(get_from_store):"+str(ioerror)) return(all_athletes)
2、整理web应用执行代码的目录
主要由以下几个成分构成:
a、一个父文件夹,存放其他文件夹 b、一个date文件夹,用来放运动员数据 c、一个images文件夹,放图片 d、templetes文件夹,放模板库 e、最重要的cgi-bin文件夹,所有的代码都要放在这里
3、需要一个运行代码的服务器
python自带的有个小型服务器,这个服务器包含在http.server库模块中
用python构建一个服务器时,必须执行一下代码:
from http.server import HTTPServer,CGIHTTPRequestHandler #导入HTTP服务器和CGI模块
port=8080 #指定一个端口
httpd=HTTPServer((‘‘,port),CGIHTTPRequestHandler) #创建一个HTTP服务器
print("启动服务器:"+str(httpd.server_port))
httpd.server_forever() #提示并启动服务器
在要运行代码的文件夹下,打开终端窗口运行服务器(shift+右键,运行终端窗口),输入“.+服务器代码的py文件名”
这是启动服务器后得到的反馈:
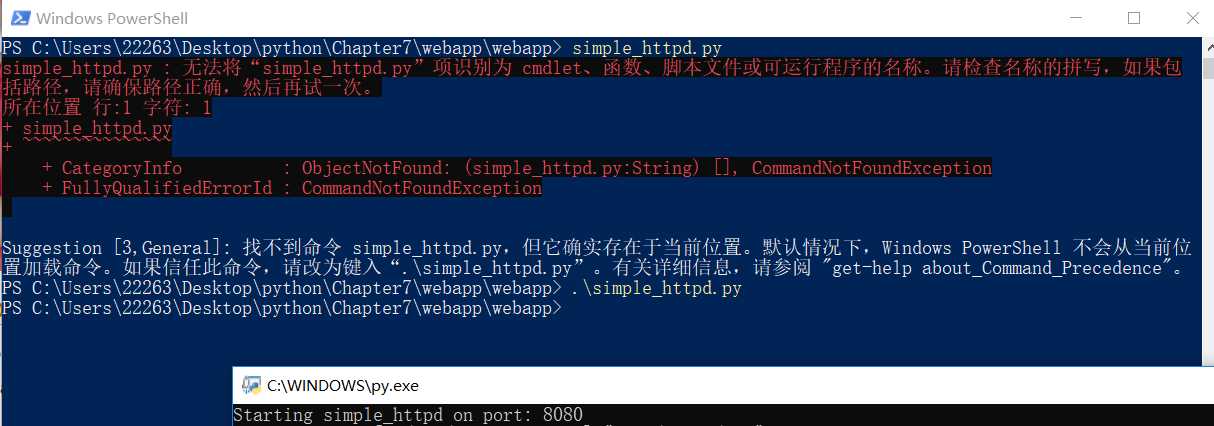
然后再浏览器中,可以输入:http://localhost:8080网址来访问页面了
4、CGI跟踪日志
import cgitb cgitb.enable()
放在要跟踪的CGI的头部,可以在浏览器窗口中看见详细的异常信息,可以快速准确地定位问题,如果没有加这个CGI跟中的话,只能看见标准的异常输出,需要自己去排查问题
5、@property 修饰符(修饰符前面会有一个@符号)
放在类方法前面,可以使类方法表现的像类属性一样,差不多意思就是,将类方法当作类属性一样使用,如:

最终完成的效果页面如下所示:
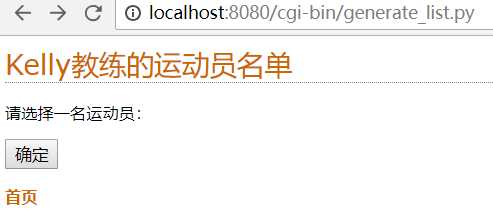
这里写出来个BUG,运动员列表没有显示出来,且直接点击确定按钮时,需要一个提示信息,提示“需要选择一个运动员”。
但我很久都没找到原因,决定先掠过这次的BUG,等我找到原因再来更新。这里放入我的代码,若是有前辈知道问题原因,还望不吝赐教
generate_list.py文件:
1 import cgitb 2 cgitb.enable() 3 4 import athletemodel 5 import yate 6 import glob #glob模块可以向操作系统查询文件名列表,这里要查询date文件夹中的各运动员文件列表 7 date_files=glob.glob("date/*.txt") 8 athletes=athletemodel.put_to_store(date_files) 9 10 print(yate.start_response()) 11 print(yate.include_header("Kelly教练的运动员名单")) 12 print(yate.start_form("generate_timing_date.py")) 13 print(yate.para("请选择一名运动员:")) 14 15 for each_athlete in athletes: 16 print(yate.radio_button("which_athlete",athletes[each_athlete].name)) 17 18 print(yate.end_form("确定")) 19 print(yate.include_footer({"首页":"/index.html"}))
generate_timing_date.py文件:
import cgi import athletemodel import yate athletes=athletemodel.get_from_store() form_date=cgi.FieldStorage() athlete_name=form_date["which_athlete"].value print(yate.start_respone()) print(yate.include_header("Kelly教练的时间数据")) print(yate.header("运动员:"+athlete_name+",生日是:"+athletes[athlete_name].dob)) print(yate.para("最快的三个时间为:")) print(yate.u_llist(athletes[athlete_name].top3)) print(yate.include_footer({"首页":"index.html","返回上一页":"generate_list.py"}))
yate.py文件:
from string import Template def start_response(resp="text/html"): return(‘Content-type: ‘ + resp + ‘ ‘) def include_header(the_title): with open(‘templates/header.html‘) as headf: head_text = headf.read() header = Template(head_text) return(header.substitute(title=the_title)) def include_footer(the_links): with open(‘templates/footer.html‘) as footf: foot_text = footf.read() link_string = ‘‘ for key in the_links: link_string += ‘<a href="‘ + the_links[key] + ‘">‘ + key + ‘</a> ‘ footer = Template(foot_text) return(footer.substitute(links=link_string)) def start_form(the_url, form_type="POST"): return(‘<form action="‘ + the_url + ‘" method="‘ + form_type + ‘">‘) def end_form(submit_msg="Submit"): return(‘<p></p><input type=submit value="‘ + submit_msg + ‘"></form>‘) def radio_button(rb_name, rb_value): return(‘<input type="radio" name="‘ + rb_name + ‘" value="‘ + rb_value + ‘"> ‘ + rb_value + ‘<br />‘) def u_list(items): u_string = ‘<ul>‘ for item in items: u_string += ‘<li>‘ + item + ‘</li>‘ u_string += ‘</ul>‘ return(u_string) def header(header_text, header_level=2): return(‘<h‘ + str(header_level) + ‘>‘ + header_text + ‘</h‘ + str(header_level) + ‘>‘) def para(para_text): return(‘<p>‘ + para_text + ‘</p>‘)
athletemodel.py文件
import pickle from athletelist import AthleteList def get_coach_data(filename): try: with open(filename) as f: data = f.readline() templ = data.strip().split(‘,‘) return(AthleteList(templ.pop(0), templ.pop(0), templ)) except IOError as ioerr: print(‘File error (get_coach_data): ‘ + str(ioerr)) return(None) def put_to_store(files_list): all_athletes = {} for each_file in files_list: ath = get_coach_data(each_file) all_athletes[ath.name] = ath try: with open(‘athletes.pickle‘, ‘wb‘) as athf: pickle.dump(all_athletes, athf) except IOError as ioerr: print(‘File error (put_and_store): ‘ + str(ioerr)) return(all_athletes) def get_from_store(): all_athletes = {} try: with open(‘athletes.pickle‘, ‘rb‘) as athf: all_athletes = pickle.load(athf) except IOError as ioerr: print(‘File error (get_from_store): ‘ + str(ioerr)) return(all_athletes)
(PS:书中说的head first python支持网站里的数据文件,我也是找了好久才找到,这里记一下地址:http://examples.oreilly.com/0636920003434/)
以上是关于Python[08]基于CGI的Web开发的主要内容,如果未能解决你的问题,请参考以下文章