吴裕雄 python 爬虫
Posted 天生自然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴裕雄 python 爬虫相关的知识,希望对你有一定的参考价值。
from urllib.parse import urlparse url = \'http://www.pm25x.com/city/beijing.htm\' o = urlparse(url) print(o) print("scheme={}".format(o.scheme)) # http print("netloc={}".format(o.netloc)) # www.pm25x.com print("port={}".format(o.port)) # None print("path={}".format(o.path)) # /city/beijing.htm print("query={}".format(o.query)) # 空

import requests url = \'http://www.wsbookshow.com/\' html = requests.get(url) html.encoding="GBK" print(html.text)

import requests url = \'http://www.wsbookshow.com/\' html = requests.get(url) html.encoding="gbk" htmllist = html.text.splitlines() n=0 for row in htmllist: if "新概念" in row: n+=1 print("找到 {} 次!".format(n))

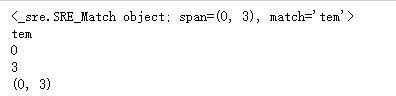
import re pat = re.compile(\'[a-z]+\') m = pat.match(\'tem12po\') print(m) if not m==None: print(m.group()) print(m.start()) print(m.end()) print(m.span())

import re m = re.match(r\'[a-z]+\',\'tem12po\') print(m) if not m==None: print(m.group()) print(m.start()) print(m.end()) print(m.span())
import re pat = re.compile(\'[a-z]+\') m = pat.search(\'3tem12po\') print(m) # <_sre.SRE_Match object; span=(1, 4), match=\'tem\'> if not m==None: print(m.group()) # tem print(m.start()) # 1 print(m.end()) # 4 print(m.span()) # (1,4)

import re pat = re.compile(\'[a-z]+\') m = pat.findall(\'tem12po\') print(m) # [\'tem\', \'po\']

import requests,re regex = re.compile(\'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+\') url = \'http://www.wsbookshow.com/\' html = requests.get(url) emails = regex.findall(html.text) for email in emails: print(email)

以上是关于吴裕雄 python 爬虫的主要内容,如果未能解决你的问题,请参考以下文章