Python使用代理的方法
Posted 雨轩恋i
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python使用代理的方法相关的知识,希望对你有一定的参考价值。
我们在做爬虫的过程中经常会遇到这样的情况:最初爬虫正常运行,正常抓取数据,一切看起来都是那么的美好,然而一杯茶的功夫可能就会出现错误,比如403 Forbidden;出现这样的原因往往是网站采取了一些反爬虫的措施,比如,服务器会检测某个IP在单位时间内的请求次数,如果超过了某个阈值,那么服务器会直接拒绝服务,返回一些错误信息。这时候,代理就派上用场了。
国内的免费代理网站:
接下来看如何设置代理:
urllib代理设置:
from urllib.error import URLError from urllib.request import ProxyHandler,build_opener proxy=\'123.58.10.36:8080\' #使用本地代理 #proxy=\'username:password@123.58.10.36:8080\' #购买代理 proxy_handler=ProxyHandler({ \'http\':\'http://\'+proxy, \'https\':\'https://\'+proxy }) opener=build_opener(proxy_handler) try: response=opener.open(\'http://httpbin.org/get\') #测试ip的网址 print(response.read().decode(\'utf-8\')) except URLError as e: print(e.reason)
运行结果如下:
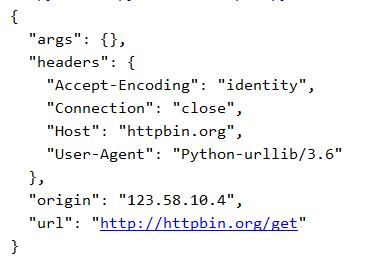
requests代理设置:
import requests proxy=\'123.58.10.36:8080\' #本地代理 #proxy=\'username:password@123.58.10.36:8080\' proxies={ \'http\':\'http://\'+proxy, \'https\':\'https://\'+proxy } try: response=requests.get(\'http://httpbin.org/get\',proxies=proxies) print(response.text) except requests.exceptions.ConnectionError as e: print(\'错误:\',e.args)
运行结果如下:
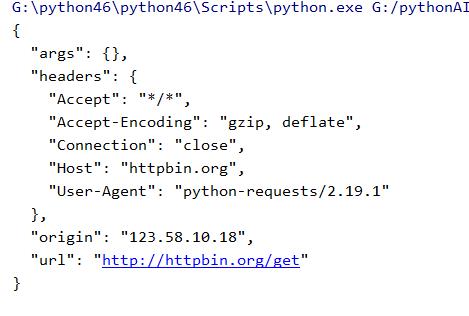
Selenium代理设置:
from selenium import webdriver proxy=\'123.58.10.36:8080\' chrome_options=webdriver.ChromeOptions() chrome_options.add_argument(\'--proxy-server=http://\'+proxy) browser=webdriver.Chrome(chrome_options=chrome_options) browser.get(\'http://httpbin.org/get\')
运行结果:
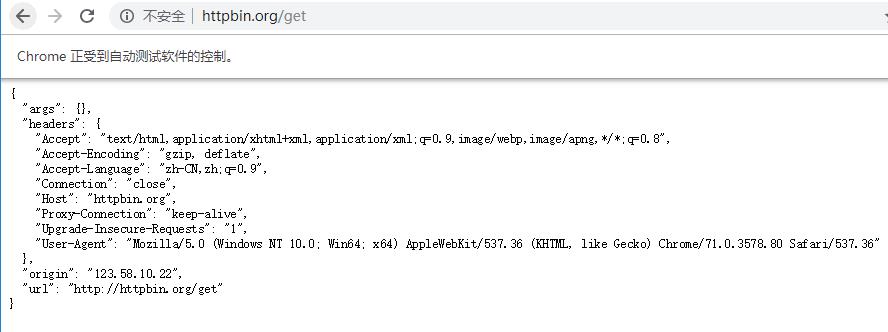
以上就是代理的一些简单设置、、、
以上是关于Python使用代理的方法的主要内容,如果未能解决你的问题,请参考以下文章