系统的实时性的思考
Posted Rabbit-susu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统的实时性的思考相关的知识,希望对你有一定的参考价值。
系统实时性
1.什么是实时性?
实时性(Real-Time),目前不清楚起源于什么,但是可以通过下面的示例来理解它.
- 图灵机的特点
输入 --> 计算 --> 输出
一个具备实时性的系统,应该可以在很短的的时间内,处理输入的数据,并给出输出.
我们知道,大部分嵌入式系统是需要和外界交互的,像是人与设备,设备与设备等,这种交互过程可以归类为通信过程.
通信过程总会有一个传输延迟,对于一个嵌入式软件系统而言,这个传输延迟,应该由计算特点来表示:
\\[T(通信系统的传输延迟) = T(编码)+T(传输)+T(解码) \\]
\\[T(嵌入式系统的<传输延迟>) = T(输入)+T(计算)+T(输出) \\]
一般的,我们认为 T(嵌入式系统的<传输延迟>) 足够小,即可为满足实时性的要求.
这个足够小总要有一个阈值,我们假定这个阈值为T(window),[叫做时间窗口],超过这个阈值我们认为系统实时性差,或者实时性不好,不是实时系统.
\\[T(嵌入式系统的<传输延迟>) < T(window) \\]
什么是实时性?
实时性表示一个条件,满足实时性的系统,应满足\\[T(嵌入式系统的<传输延迟>) < T(window) \\]
2.T(window)怎么确定
T(window)并不是恒值,它依赖于一个具体的系统.比如数据处理系统,AD采集系统,以及一些控制系统.即他们是和具体的软件功能绑定的.
2.1数据处理系统
拿数据处理系统来说,我们根据图灵机的特点,给出数据处理系统的软件特点:
接收数据 --> 处理数据 --> 发送数据
T(window)这里应该表示满足从接收数据,到处理数据,最后发送数据这个过程所需要的时间.
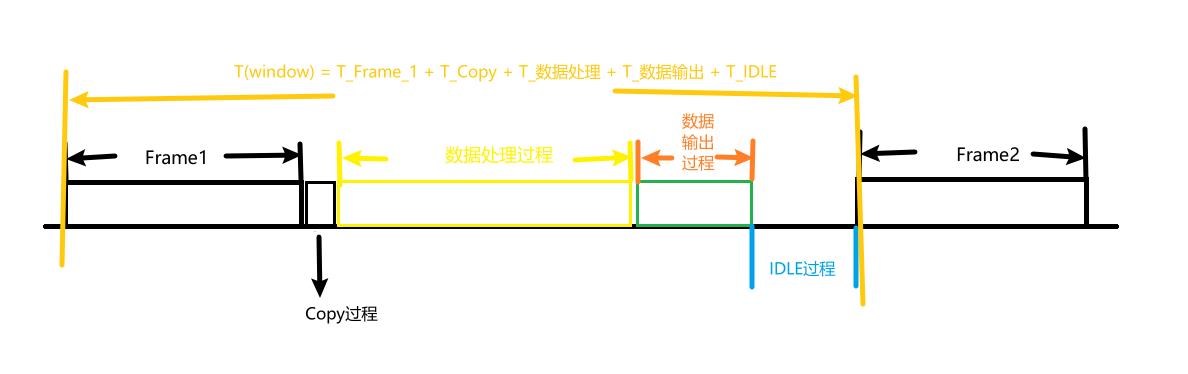
如图所示,T(window)这里表示两帧数据之间的时间间隔.
x = 数据处理系统
\\[T(x,window) = T(FrameRate) \\]
上面这个模型只是考虑了帧长固定的情况,如果一帧的数据不是固定的,上式应该考虑一帧的长度length.
\\[T(x,window) = T(FrameRate, FrameLength) \\]
从图中,我们也能够得到数据传输系统的传输延迟是多少
delay = <传输延迟>
\\[T(x,delay) = T(Copy) + T(DataProcess) + T(DataOutput) \\]
于是,我们的到了x = 数据处理系统 时,x的满足实时性系统的条件是:
\\[T(FrameRate, FrameLength) > T(Copy) + T(DataProcess) + T(DataOutput) \\]
T(Idle)
\\[T(Idle) = T(x,delay)- T(x,window) \\]\\[= T(FrameRate, FrameLength) - (T(Copy) + T(DataProcess) + T(DataOutput)) \\]
T(Idle)就是我们可以控制的变量.
这里有人问我,为什么是可以控制的?
可以控制是说,我们可以通过一些手段来控制这个值,比如:
通过RTOS提供的rt_thread_mdelay(n ms)来改变这个 Idle 时间.
除此之外,还可以通过下面的手段,来估计这个n的最小值.
而T(Copy) + T(DataProcess) + T(DataOutput)这部分大多是由协议绑定的,是存在一个最小值的.
为了增大T(Idle)来给x更多的时间来处理其它事物,且要满足实时性的条件.我们不得不改变T(FrameRate,FrameLength).
\\[T(Idle) \\propto 1/FrameRate \\]\\[T(Idle) \\propto -k*FrameLength \\]
T(Idle)和FrameRate成反比,与-FrameLength成正比.
即帧率(FrameRate)越高,T(Idle)就越小.
(这里少了个条件,是在一定时间范围内)
于是,为了保证系统的实时性,我们要么降低帧率(FrameRate);要么提高cpu的主频.
这里有人跟我说改变
FrameLength不行么?
一般来说,FrameLength对实时性的影响较低,改变FrameLength,一种情况是,定长帧+多帧协议,比如CAN报文中经常用的方法:
8bytes/frame + 多帧传输协议(TP协议)
2.2. AD采集系统
分析同上.
2.3. 控制系统
分析同上.
我们利用图灵机系统的特点,简化满足实时性系统的条件.
\\[T(x, window) > T(Input) + T(Process) + T(Output) \\]如果假定两者的差值为T(Idle)
\\[T(Idle) = T(x, window)-T(Input) + T(Process) + T(Output) \\]那么T(Idle)需要大于0,才可以满足系统的实时性要求.
\\[T(Idle) > 0 \\]
3.T(嵌入式系统的<传输延迟>)怎么计算
我们当下很多嵌入式系统都是多功能,多任务的.对于这些功能复杂的系统,希望它们满足实时性的要求,则需要对系统有一个良好的设计.
什么是良好的设计呢?
首先可以确定的一点是 T(Idle) > 0 ,为了确保CPU有空闲时间,我们可以根据经验,事先计算需要的主频.
我们先写好相关的协议/算法/逻辑.
然后选择好内核,比如ARM内核.
然后,根据指令估算这部分代码所需要的时间.
在此基础上,加上一个冗余,这部分冗余,是给中断,RTOS调度,等其它功能.
T(Process)的计算.
\\[T(Process)=T(Code)+T(Others) \\]其中 Others 指 Interrupt, schedule 等
同理,我们也可以计算出 T(Input) , T(Output) .
\\[T(Input)=T(Code)+T(Others) \\]\\[T(Output)=T(Code)+T(Others) \\]其中 Others 指 Interrupt, schedule 等
于是,我们可以计算某个系统的<传输延迟>了.
x=某个嵌入式系统
y=task(m),m为某个任务的标号,y表示某个任务.\\[T(x,y,delay) = T(Input) + T(Process) + T(Output) \\]\\[= T(InputCode) + T(ProcessCode) + T(OutputCode) + T(OthersCode) \\]
4.并发问题
上面我们讨论了嵌入式系统单个任务/功能的<传输延迟>,这也可以粗略的给出该任务满足实时性要求的时间窗口.
但是当,某一个时刻,出现多个输入事件时,原有的 T(Idle) 可能就不足以确保彼此的实时性.
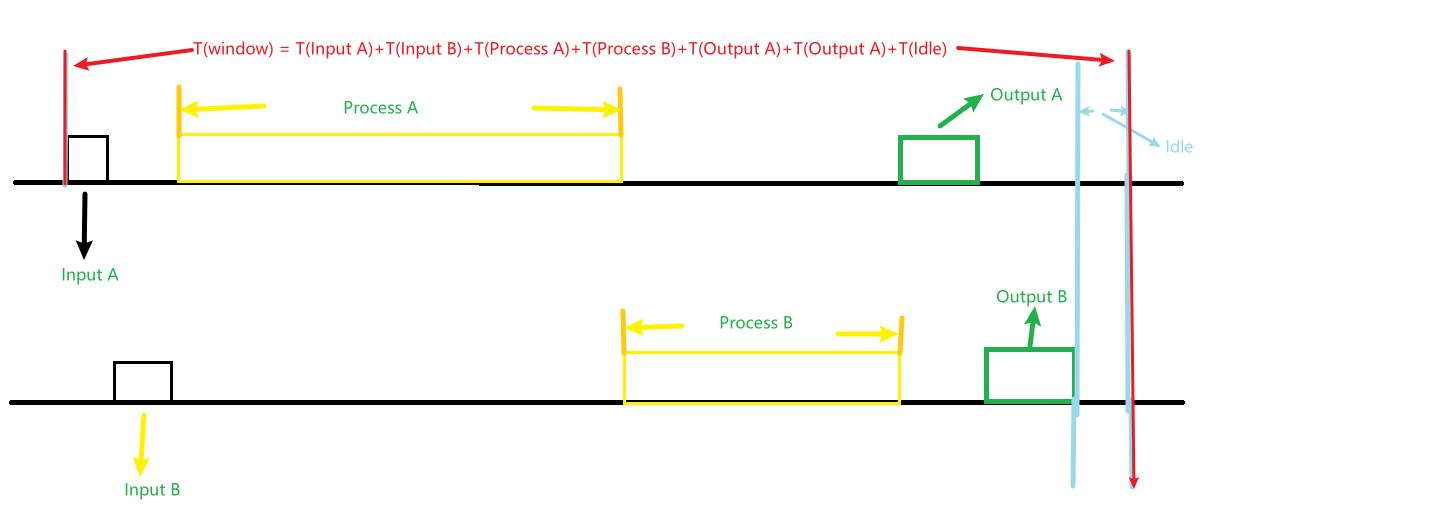
如图,我们可以计算出多任务,并发情况的时间窗口示意图.
x=某个嵌入式系统
y=[task(A),task(B)]\\[T(x,y, window) = T(Input A) + T(Input B) + T(Process A) + T(Process B) + T(Output A) + T(Output B) + T(Idle) \\]其中
\\[T(x,y,delay) = T(Input A) + T(Input B) + T(Process A) + T(Process B) + T(Output A) + T(Output B) \\]
为了方便对比单任务和多任务之间时间窗口的差距.我绘制了多任务时,每个任务独自的时间窗口.如图.
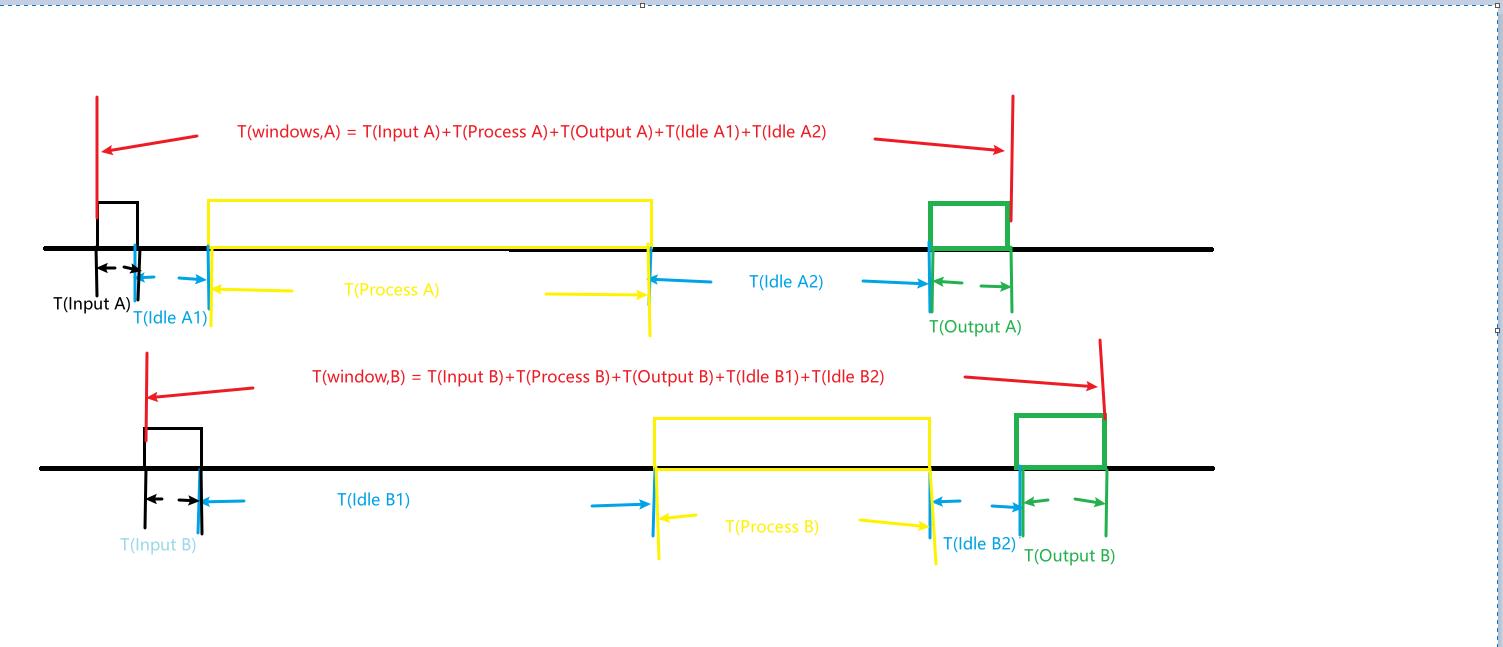
task(A)的时间窗口示意图
\\[T(x,y=task(A), window) = T(Input A) + T(Process A) + T(Output A)+ T(Idle A1) + T(Idle A2) \\]其中
\\[T(x,y=task(A),delay) = T(Input A) + T(Process A) + T(Output A) \\]task(B)的时间窗口示意图
\\[T(x,y=task(B), window) = T(Input B) + T(Process B) + T(Output B) + T(Idle B1) + T(Idle B2) \\]其中
\\[T(x,y=task(B),delay) = T(Input B) + T(Process B) + T(Output B) \\]
若要task(A)和task(B)满足实时性,则应同时满足下面条件.
若task(A)满足实时性的要求.
则\\[T(Idle A1) + T(Idle A2) >= T(x,y=task(B),delay) \\]同理,若task(B)满足实时性的要求.
则\\[T(Idle B1) + T(Idle B2) >= T(x,y=task(A),delay) \\]
这里回顾一下单系统(任务)时的方程,可以得出以下规律:
单独task(A)系统(任务)时,
T(Idle)=m
而task(A),task(B)两个任务时,
(Idle A1) + T(Idle A2) = p;
(Idle B1) + T(Idle B2) = q;
m,p,q之间满足如下关系:\\[p>m, \\]\\[q>m, \\]\\[m>T(x,y=task(A),delay), \\]\\[m>T(x,y=task(B),delay) \\]
这与直觉是一致的:
1.单任务系统时,只要满足 T(Idle)>0 ,该系统就满足实时性的要求.
2.双任务系统时,每个任务的 T(Idle) 被拆为多个部分,总和分别为p,q,...
p,q,...需要比除自身外其它任务的<传输延迟>之和 T(x,y=task(?),delay) 要大.
这意味着,原有的 T(Idle) 有一个下限值 m ,这个下限值 m 要比 T(x,y=task(?),delay) 任意一个都大.
3.更多的任务时,系统的并发实时性,有更高的要求.下限值 m ,应该比除自身外,其它所有任务的 <传输延迟> 之和sum(T(x,y=task(?-self),delay))要大.
5.总结
一个系统的实时性并非只由代码部分决定,还与环境有关.
代码能决定的是下限,环境决定的是上限.
6.问与答
没有蠢问题
问题1:嵌入式系统的<传输延迟>是什么?
答: 这里是指一个嵌入式系统完成图灵机的完整特性的过程.
图灵机有一个特性,那就是
输入 --> 计算 --> 输出
完成这个过程是需要时间的,我把这个时间叫做 嵌入式系统的<传输延迟>
问题2:怎么分析系统的实时性
答:
只要把握住这个关系,系统的实时性就可以通过
这几部分代码所需时间 T(嵌入式系统的<传输延迟>)
与
事件序列的频率/周期 T(window)
之间的大小关系来分析该系统的实时性.只要
\\[T(window) > T(嵌入式系统的<传输延迟>) \\]
即可认为系统的实时性满足.
问题3:怎么提高系统的实时性
答: 实时性的问题,跟我们平时想的差不多.
1.减少 rt_thread_mdelay(n ms) 中 n 的大小,让cpu更频繁的执行该任务. ---- 从 T(Idle) 入手
2.降低输入数据的帧的速率或者提高事件触发的间隔 ---- 从 T(Idle) 入手
3.提高数据处理的速率.(提升主频) ---- 从 T(process) 入手
T(Input) , T(Output) 一般使用中断或DMA的方式,占用的时间并不多,优化空间有限.
问题4:改变输入缓冲区的大小,为啥不能解决实时性的问题
答: 系统的实时性不好,本质是没满足实时性要求.
增加缓冲区的大小,对于 T(Input) , T(process) , T(Output) 没有任何的改变,甚至还增加了 T(Input) 的时间.
问题5:T(Idle) 究竟代表什么?为什么有时候是rt_thread_mdelay(n ms) 影响,有时候是事件的触发速率影响
答: T(Idle) 并不是这么来理解的,看我上面的定义.
T(Idle) 是 T(x,delay) 与 T(x,window) 的差值,它代表的是一个冗余量.
比如,我们在购买东西时,我们会有一个估值,在这个值的基础上,我们允许所购买的东西价格上有所波动,这个波动的范围,就是一个冗余量,我们事先并不知道这个个冗余量具体该是多少,而是通过一些额外的方式,比如自己的积蓄总额,我们根据这个积蓄总额,我们确定了一个购买该物品的上限,于是我们就可以通过这个上限减去需要购买的东西的价格,得出这个波动的范围.
这里,积蓄总额就相当于 T(x,window) ,而需要购买的物品的估价就是 T(x,delay) .
有了这也的观念后,再去思考改变 T(Idle) 的手段有哪些:
rt_thread_mdelay(n ms)是一种方式,它显式的标注了该任务的一个冗余量.
而事件的触发速率,是通过另外两个值影响到 T(Idle) 的,参见 T(Idle) 控制方式.
一般两个事件的触发间隔,是我们执行 输入-->计算-->输出 的过程.这个过程影响了 T(Idle)
EventRate :表示事件的触发速率,它决定了事件的间隔.
EventHoldTime :表示事件的持续事件,它和EventRate共同决定了图灵机进行有效计算的时间.\\[T(Idle) \\propto 1/EventRate \\]\\[T(Idle) \\propto -k*EventHoldTime \\]
本文来自博客园,作者:当最后一片树叶落下,转载请注明原文链接:https://www.cnblogs.com/Rabbit-susu/p/17407373.html
slope实时推荐算法的系统设计思考
首先我不是做推荐的,无意间看到这个算法觉得比较简单有趣,然后就执拗的想设计下如何在系统层面保证算法实时性。
Slope是一个能够做到在线实时计算的简单通俗推荐算法,其基本原理源自数学上线性关系。具体原理Google上随手一搜很多介绍和应用实例。本篇主要谈论从系统角度,如何将slope做成在线实时更新的推荐引擎。
根据slope的原理:用户对某个产品可能的兴趣取决于已有用户标签和物品之间的加权平均差值。主要应用于“猜你喜欢”、“换一批”等类似的TopK推荐。TopK的推荐一定是基于打分原则,通过可量化的指标和算法,得到某个用户user_id对某件物品的感兴趣程度,f(user_id, item_id) 。
可见slope的所有轮子启动取决于用户对某一件商品点下评分的那一瞬间。
一、从系统角度,这一瞬间发生了什么
1、用户-物品打分更新
2、物品间关联系数更新
3、TopK更新
二、这3个变动触发了哪些系统层次的设计
1、存储结构设计
(1)物品表 Items
item_id
Item_profile (复合结构)
(2)用户-物品-打分表 UserItemScores
user_id
item_id
score
(3)物品关联表 ItemRelations
item_id
ration_id
factor
total
cnt
(4)用户-物品-预测表 UserItemPredicts
所有的业务流程围绕这4张表展开。
2、逻辑
(1)UserItemScores 增加一条用户打分记录;
(user_id, item_id, score)
(2)ItemRelations
UserItemScores中user_id对应的item_ids关联的(item_id, item_id’)的相关系数都需要做校正
(3)Top-K
三、场景分解和系统设计挑战
用户在线状态下打分处于高频状态,根据业务场景可以进行如下细化:
(1)同一user_id的打分处于低频状态
即一个用户不可能给多件物品同时打分;
(2)不同user_id在同一时刻打分处于高频状态
即多个用户在同一时刻打分;
(3)你不同user_id在同一时刻对同一item_id处于变化状态;
即物品的冷热程度不同,某一段时间可能某个物品非常热,多数物品都处于冷状态。
因此,通过场景归纳,关键问题在于:
(1)ItemRelations中(item(i), item(j))的差值在多用户打分更新的时候如何保证高并发量的写入操作;
(2)某个用户的推荐列表topK如何实时动态更新。
1、高并发写入
高并发更新数据的方法论在于:尽可能减少粒度,降低并发度冲突范围。这个问题也不例外,100个、1w个和100w个请求同时更新一个数据的处理时延是不一样的。
其次,这个问题分为水平和垂直两个方向,水平是指ItemRelations的全量数据集如何解决高并发更新;垂直是指某一数据如何解决高并发更新。
最后,个人理解推荐系统中所描述的实时性跟后台系统API的实时性的理解是一样的,API的实时性是毫秒级的,推荐系统能够在秒级甚至1分钟内完成都可以称之为实时。
(1)水平方向
基础的方法论:粒度放小,降低并发冲突率。这个问题也不例外。
最简单的做法是机械式分库分表,百库百表大法。
如果想做的好一点:冷热数据分离,冷数据集中,热数据单独处理。
还有经典的削峰理论:请求经过消息队列,相当于做一层平滑处理,将峰值降下来。
(2)垂直方向
高并发下如何更新同一个数据,解决方式取决于请求量级。
a、排队
简单即为美,最基础的排队方式就可以解决。更新数据的入口挂一层proxy将所有操作通过proxy排队,变并行为串行。
b、聚合+排队
机械排队可能延迟会有点大,变简单排队为聚合+排队。proxy层每收集n个请求将其聚合计算,比如每100次聚合一次请求更新一次,那么请求量就下降了100倍。
c、内存+异步更新+聚合+排队
这种场景在在线广告计费系统中应该遇到,曝光并发量很大的时候如何实时更新数据库内的计费。
解决之道的本质还是分离,变实时更新数据库为异步更新数据库,加一层内存级别的数据存储,在线系统经聚合后只更新内存,数据库异步更新完成。
2、Top-K的动态更新
上述高并发写入能够保证实时性后,Top-K完全可以在接口层做聚合。
(1)读取用户已有的打分列表和item_relations的关联factor将未打分列表计算后取Top-K。
(2)如果过程(1)慢,变为聚合方式,每n秒计算一次更新到结果存储,API直接取结果。
(3)如果(2)还是慢,每次计算完的结果取定长的5倍或者10倍top-k的数据作为中间数据用于计算真正的top-k,中间数据定期去更新。
物品的种类少说百万级,采用方案(3)的可能性最大。
没有什么问题是中间层解决不了的,如果不行就再来一层。
四、Slope的缺点
1、冷启动
没有用户评价物品的时候这个算法是不生效的。
2、数据稀疏性
多数用户是不评价的,那么有评价的数据占比很少,多数物品没有任何用户评价,那么有效数据是稀疏的。
这两个问题还是需要算法同学多想想办法了。
以上是关于系统的实时性的思考的主要内容,如果未能解决你的问题,请参考以下文章