在 Transformers 中使用对比搜索生成可媲美人类水平的文本 🤗
Posted Hugging Face 博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在 Transformers 中使用对比搜索生成可媲美人类水平的文本 🤗相关的知识,希望对你有一定的参考价值。
1. 引言
自然语言生成 (即文本生成) 是自然语言处理 (NLP) 的核心任务之一。本文将介绍神经网络文本生成领域当前最先进的解码方法 对比搜索 (Contrastive Search)。提出该方法的论文 “A Contrastive Framework for Neural Text Generation” 最初发表于 NeurIPS 2022 ([论文]、[官方实现])。此后, “Contrastive Search Is What You Need For Neural Text Generation” 的作者又进一步证明了对比搜索可以用 现有的 语言模型在 16 种语言上生成可媲美人类水平的文本 ([论文]、[官方实现])。
[备注] 对于不熟悉文本生成的用户,请参阅 此博文 了解更多详情。
2. Hugging Face
RASATED Policy:Dialogue Transformers
最近工作中使用到rasa,其core部分有一个rasa自己提出的TED Policy框架组建,可用于进行对话决策。今天有空,就来研究下它~
论文《Dialogue Transformers》地址:https://arxiv.org/abs/1910.00486
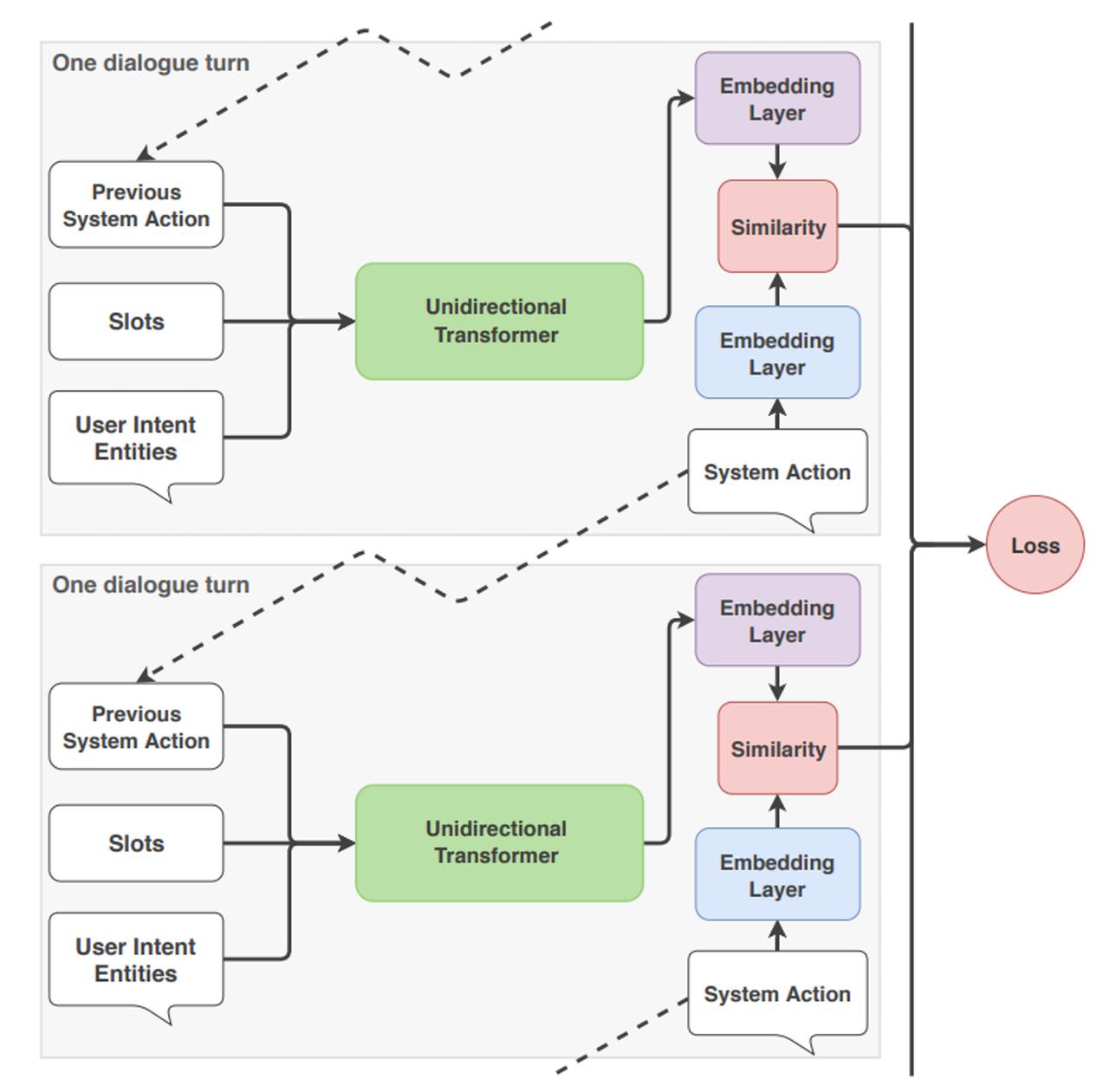
让我们整体的看一下当 TED Policy从输入到输出进行预测时会发生什么。
在每个对话回合,TED Policy将三条信息作为输入:用户的消息、预测的先前系统动作以及作为插槽保存到助手内存中的任何值。这些中的每一个都在输入到transformer之前进行了特征化和连接。
这就是自注意力机制发挥作用的地方:transformer 在每一轮动态访问对话历史的不同部分,然后评估和重新计算前几轮的相关性。这允许 TED Policy一次考虑用户话语,但在另一轮完全忽略它,这使得transformer 成为处理对话历史的有用架构。
接下来,将dense layer应用于transformer的输出以获得用于近似文本含义的嵌入数值特征,用于对话上下文和系统动作。计算嵌入之间的差异,TED Policy最大化与目标标签的相似性并最小化与错误标签的相似性,这是一种基于Starspace算法的技术。这种比较嵌入之间相似性的过程类似于Rasa NLU pipeline中的EmbeddingIntentClassifier预测意图分类的方式。
当需要预测下一个系统动作时,所有可能的系统动作根据它们的相似度进行排序,并选择相似度最高的动作。
这个过程在每个对话回合中重复,如下所示:
效果:
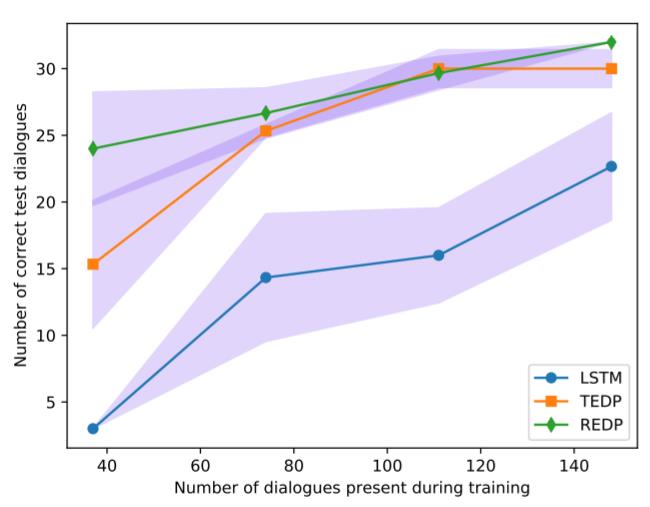
在极低数据情况下,REDP 优于 TED Policy。应该注意的是,REDP 严重依赖其复制机制来预测非合作题外话后先前提出的问题。然而,TED Policy既简单又通用,在不依赖于重复问题等对话属性的情况下实现了类似的性能。此外,由于transformer架构,TED 政策训练比 REDP 更快,并且需要更少的训练周期来达到相同的精度。
以上是关于在 Transformers 中使用对比搜索生成可媲美人类水平的文本 🤗的主要内容,如果未能解决你的问题,请参考以下文章