用Python爬取猫眼上的top100评分电影
Posted cs_wu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python爬取猫眼上的top100评分电影相关的知识,希望对你有一定的参考价值。
代码如下:
# 注意encoding = \'utf-8\'和ensure_ascii = False,不写的话不能输出汉字
import requests
from requests.exceptions import RequestException
import re
import json
#from multiprocessing import Pool
# 测试了下 这里需要自己添加头部 否则得不到网页
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36\'
}
# 得到html代码
def get_one_page(url):
try:
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
# 解析html代码
def parse_one_page(html):
pattern = re.compile(\'<dd>.*?board-index.*?>(\\d+)</i>.*?data-src="(.*?)".*?name"><a.*?">(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?(/dd)\', re.S)
items = re.findall(pattern, html)
for item in items:
# 将元组形式变为字典
yield {
\'【排名】\': item[0],
\'【图片】\': item[1],
\'【标题】\': item[2],
\'【主演】\': item[3].strip()[3:],
\'【上映时间】\': item[4].strip()[5:],
\'【评分】\': item[5] + item[6]
}
# 写入文件,写入的是一个json格式的数据
def write_to_file(content):
with open(\'top100.csv\', \'a\', encoding = \'utf-8\') as f:
f.write(json.dumps(content, ensure_ascii = False) + \'\\n\')
f.close()
# 主函数
def main(offset):
url = \'http://maoyan.com/board/4?offset=\' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == \'__main__\':
for i in range(10):
main(i * 10)
# 多进程(测试有bug)
# if __name__ == \'__main__\':
# pool = Pool()
# pool.map(main, [i * 10 for i in range(10)])
# pool.join()
# pool.close()
运行结果如下:
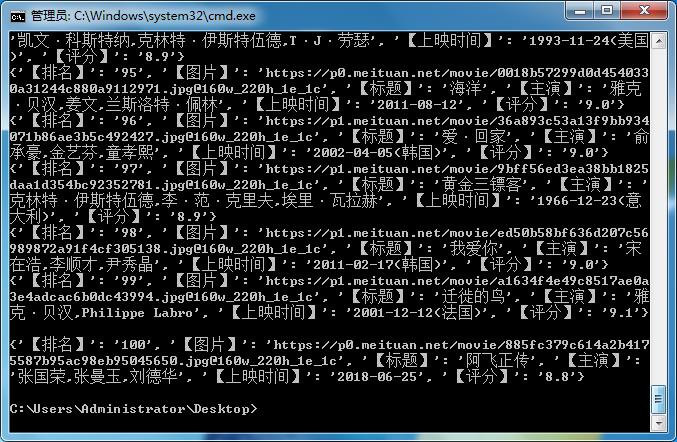
在top100.csv文件中的数据如下:
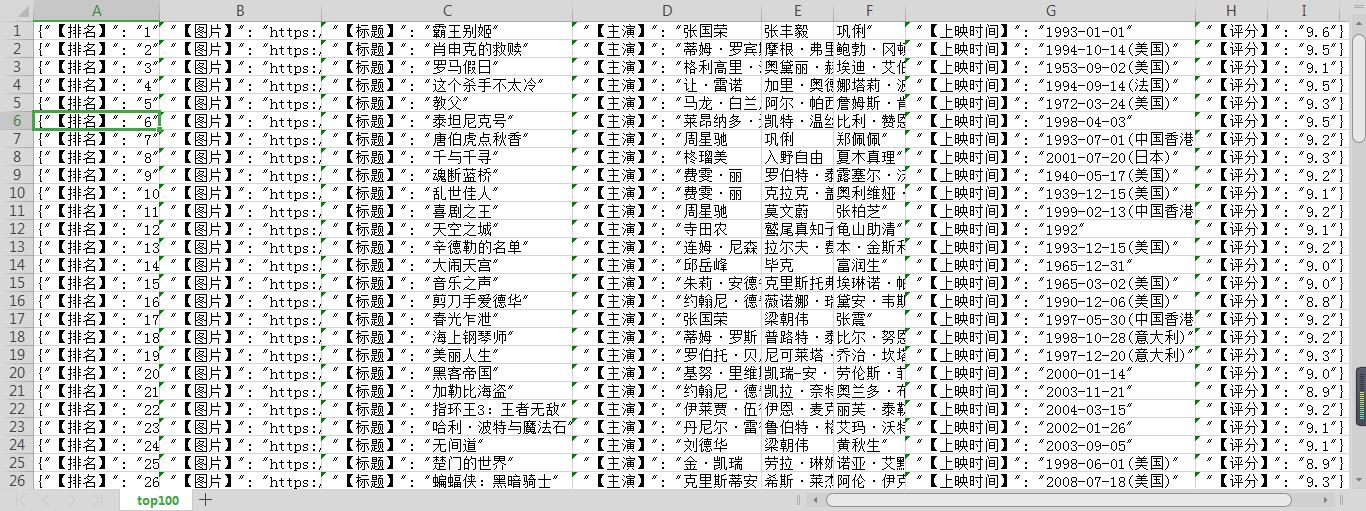
因为没有下载模块所以这里只是显示首页图片的链接,如果想下载首页图片还需再加上下载模块
以上是关于用Python爬取猫眼上的top100评分电影的主要内容,如果未能解决你的问题,请参考以下文章