Booking.com如何在毫秒内搜索数百万个地点
Posted charlieroro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Booking.com如何在毫秒内搜索数百万个地点相关的知识,希望对你有一定的参考价值。
译自:How Booking.com Searches Through Millions of Locations in Milliseconds
Booking.com是一家与酒店、旅馆、度假租赁等相关的在线旅行社。每个月都有数亿用户通过访问该网站来寻找合适的度假住宿。Booking的一个主要特性是可以以地图的方式提供查找服务,其地图市场提供了上千万套房产,用户可以通过地图查找到:
- 提供租赁房产的位置
- 附近感兴趣的地方(博物馆、沙滩、历史建筑等)
- 租赁房产与感兴趣的地方的距离
为实现此需求,需要能够快速加载地图,其后端需要搜索世界各地数百万个不同的点。
Igor Dotsenko 写了一篇博客来探究他们是如何实现该目标的。
在地图上查找
当用户打开地图查找房产时,会出现一个有边界的框,此时需要在边框内展示感兴趣的点,这样Booking才能在该框中快速查找最感兴趣的点。

Quadtrees(四叉树)
底层数据结构采用的是Quadtree。Quadtrees是一种树,特别适用于2D空间数据,如地图、图像、视频游戏等。通过Quadtrees可以实现高效地插入/删除点操作、快速范围查找、最近邻搜索等。
Quadtrees和其他树结构一样存在父子节点。对于一个Quadtrees,其内部节点总是包含4个子节点(内部节点即非叶子的节点,叶子节点没有子节点)。父节点表示一个特定的2D区域空间,每个子节点表示该区域的象限。
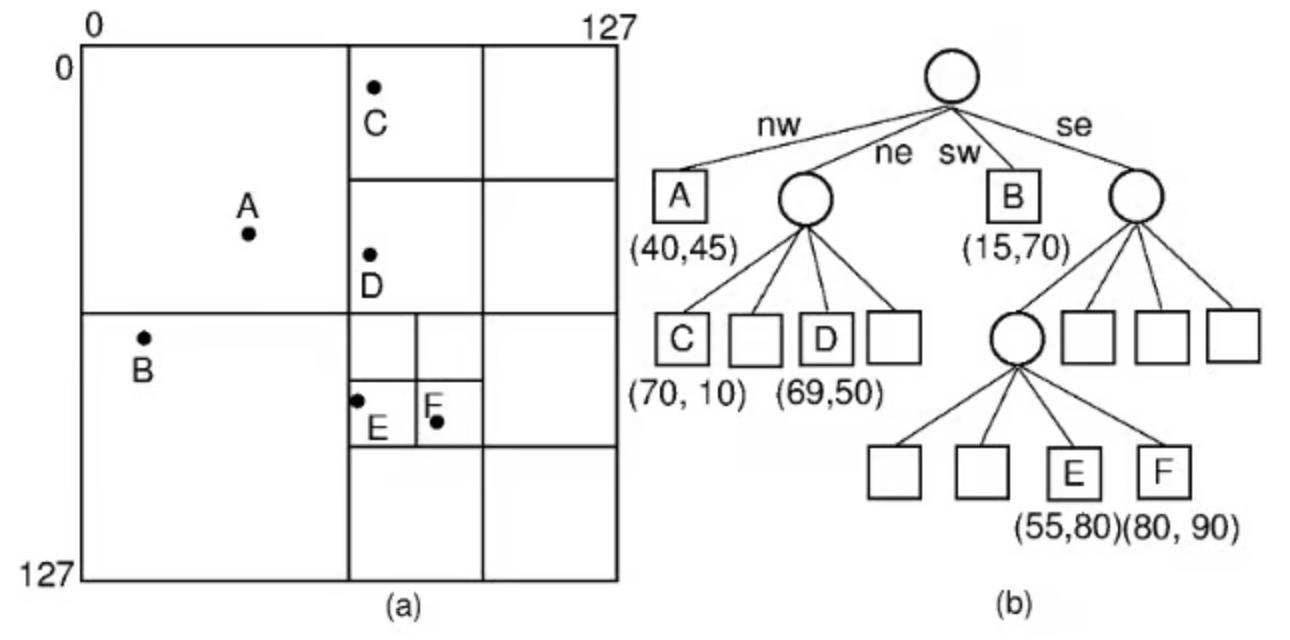
当处理地图数据时,父节点表示地图上的某些区域,其4个子节点分别表示父区域的西北、东北、西南和东南四个象限。
对于Booking,每个节点表示地图上的特定有界框,用户可以通过在地图上放大或平移来修改可见的有界框。节点的每个子节点将西北、东北、西南和东南边界框保持在父节点的边界框内。
每个节点还包含少量标记(代表感兴趣的地点),每个标记会分配一个重要值,重要值大的标记被分配给树中更高的节点(即根节点中的标记是最重要的)。
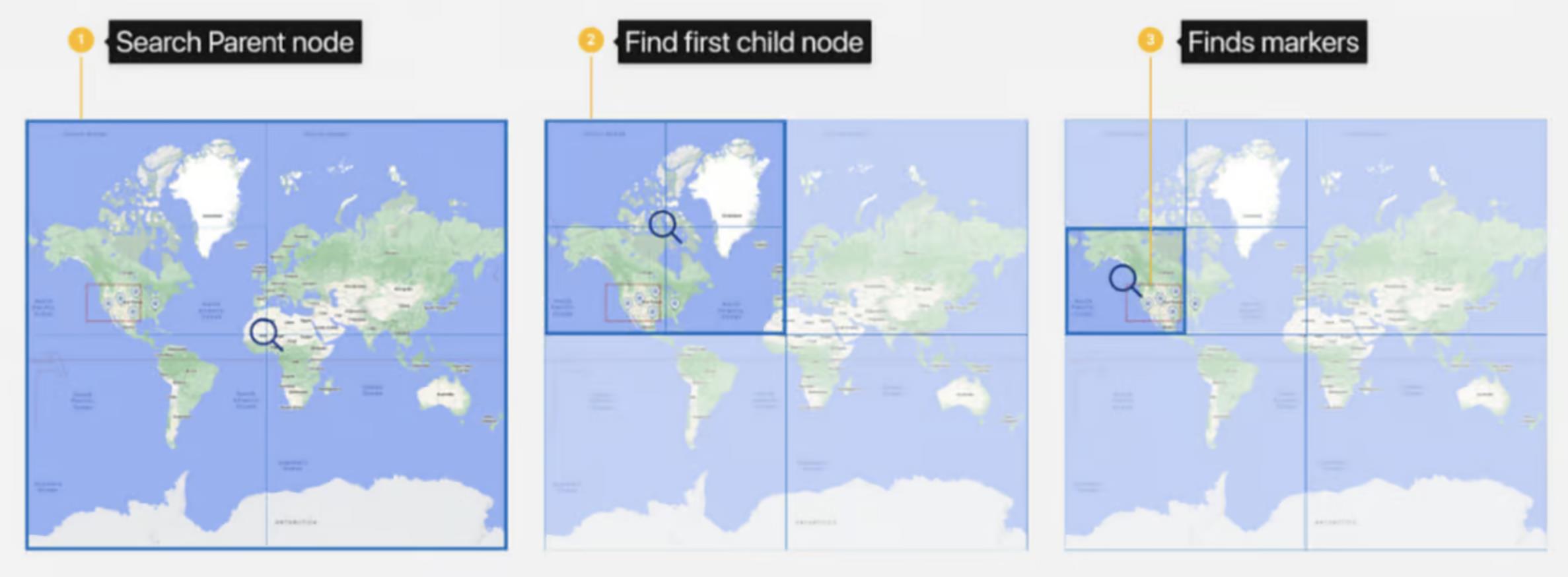
下面看下Booking是如何查找、构建和更新Quadtree的。
查找Quadtree
当用户选择一个特定的有界框时,Booking会从Quadtree 中为该有界框查找最重要的标记,因此使用了广度优先查找(从上往下按照重要度查找到一定数目的标记)。
首先从根节点开始查找与选择的有界框交叉的标记,如果需要更多的标记,则会继续查找与有界框交叉的子节点,并将其添加到队列中。使用先进先出的顺序处理队列中的节点(查找和有界框交叉的标记)。一旦查找到足够(等于请求数目)的标记,则结束查找并将结果发送给用户(展示在地图上)。
构建Quadtree
本段内容来自该博客
Quadtree保存在内存中,且会时不时地通过重建来添加新的标记(或修改标记的重要程度)。
一开始只有一个表示整个世界的根节点,且为空。为了使用标记构建树,需要通过遍历所有标记来将其插入到树中。假设每个节点最多可以包含10个标记,每次插入时:
- 将当前标记放到当前节点的标记集中
- 如果当前标记的数目<=10,则插入结束,遍历下一个标记
- 如果当前标记的数目>10,则需要从该节点中找到重要值最低的标记,并将其放到子节点中(越靠近根节点的节点,其标记的重要值越高)
- 如果该节点没有子节点,则需要创建子节点(将节点的有界框分为4个子有界框,即4个子节点)
- 从子节点中查找与有界框重要值最低的标记相交的节点
- 将此标记递归放入子节点(即重复第一个步骤)
结果
Booking通过创建更多的Quadtree,并让每个Quadtree负责特定的地理区域来实现水平伸缩。对于存储了300,000个标记的Quadtree,其p99检索速度小于5.5毫秒。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/17395203.html
如何有效地计算数百万个字符串之间的余弦相似度
【中文标题】如何有效地计算数百万个字符串之间的余弦相似度【英文标题】:How to efficiently compute the cosine similarity between millions of strings [closed] 【发布时间】:2013-02-09 02:26:48 【问题描述】:我需要计算列表中字符串之间的余弦相似度。例如,我有一个超过 1000 万个字符串的列表,每个字符串都必须确定其自身与列表中每个其他字符串之间的相似性。我可以用来高效快速地完成此类任务的最佳算法是什么?分治算法是否适用?
编辑
我想确定哪些字符串与给定字符串最相似,并且能够拥有与相似度相关的度量/分数。我认为我想做的事情与最初不知道集群数量的集群一致。
【问题讨论】:
根据您的问题的定义,余弦相似度计算的执行复杂度为 O(n²)。 @Xion345 是的,这么大的数据可以接受吗?我不认为是 您必须为此使用动态编程。见this链接 1000 万乘以 1000 万 = 1000 亿。如果余弦相似度的每次应用需要 50 微秒,那么您得到的最短时间约为 5000 万秒,也就是大约一年半。如果余弦相似度只需要 1 纳秒,您仍然需要 1000 秒。因此,即使使用动态编程,您也无法做太多事情。您应该找到一种方法来避免所有这些余弦相似度计算。 @Xion345 好吧,如果你很聪明,你可以节省计算 0*something。如果你利用稀疏性,它只是非稀疏部分的二次方。哪个更好。 【参考方案1】:使用转置矩阵。这就是 Mahout 在 Hadoop 上为快速完成此类任务(或仅使用 Mahout)所做的。
本质上,以幼稚的方式计算余弦相似度是不好的。因为你最终会计算很多 0 * 的东西。相反,你最好在列中工作,并且把所有的0都留在那里。
【讨论】:
【参考方案2】:你可以试试SimString。
它是一个用于近似字符串匹配的 C++ 库(带有 Python 或 Ruby 绑定)。
它声称可以在 1 毫秒内为包含 1300 万个字符串的数据库找到具有高余弦相似度的字符串。
所使用的算法描述为here 基于倒排列表的修剪。
【讨论】:
以上是关于Booking.com如何在毫秒内搜索数百万个地点的主要内容,如果未能解决你的问题,请参考以下文章