写python爬虫时,想抓图片的原图?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了写python爬虫时,想抓图片的原图?相关的知识,希望对你有一定的参考价值。
参考技术A 点图片之前开启firebug,切换到网络标签,看看你点图片的时候发生了什么。然后模仿那个http请求。
重新看了一下图,好像没那么麻烦。
下面那个img标签里的 data-src 不就是原图地址?
用python批量下载图片
一 写爬虫注意事项
网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么样的爬虫是违法的:
如果爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取公民个人信息的违法行为。除此之外,根据相关规定,对于违反国家有关规定,向他人出售或者提供公民个人信息,情节严重的,窃取或者以其他方法非法获取公民个人信息的,均可构成成“侵犯公民个人信息罪”,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
重点关注:下列情况下,爬虫有可能违法,严重的甚至构成犯罪。
- 爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法获取相关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。
- 爬虫程序干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成“破坏计算机信息系统罪”
- 爬虫采集的信息属于公民个人信息的,有可能构成非法获取公民个人信息的违法行为,情节严重的,有可能构成“侵犯公民个人信息罪”。
详情可以通过知乎爬虫
)这个链接来了解下。
简单来说,就是不要碰公民个人信息,不要多线程或多进程过度爬取,不要违反反爬虫协议或破解服务器爬取。
二 . 找数据源
假如我们要找明星照片信息,我们首先要找到来源,搜索引擎是可以方便找;在豆瓣这种文艺范的网站上也有,鉴于豆瓣上的接口更容易些,所以这次就从豆瓣上下载吧。
在谷歌浏览器中打开豆瓣的搜索框内搜索明星“李孝利”,按F12进入开发工具,如下图,然后在Network地方点击XHR,XHR是XMLHttpRequest的简称,在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下,对网页某部分的内容进行更新。
是Ajax的一种用法,一般为JSON格式,我们下载图片,就是要先找到XHR的请求地址,分析请求内容,再通过请求的链接去下载图片,保存到本地即可。
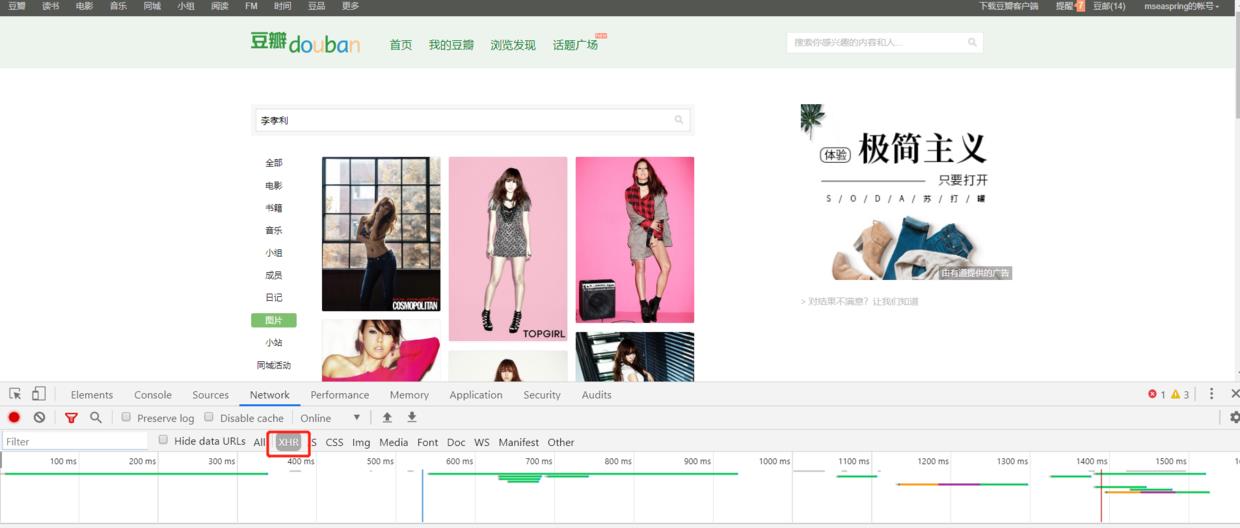
分析下XHR的地址和格式: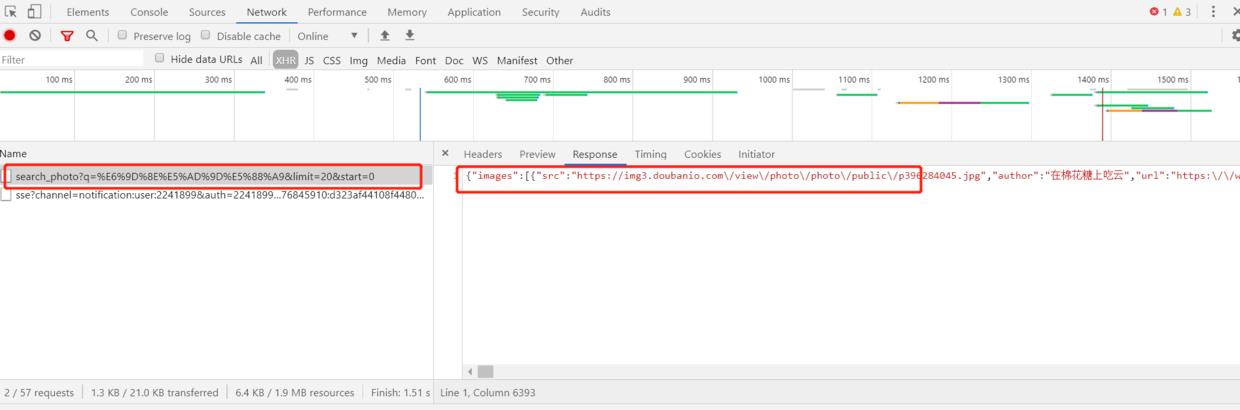
在左边地址右键在新的tab页面打开,即可以看到更详细的信息,如下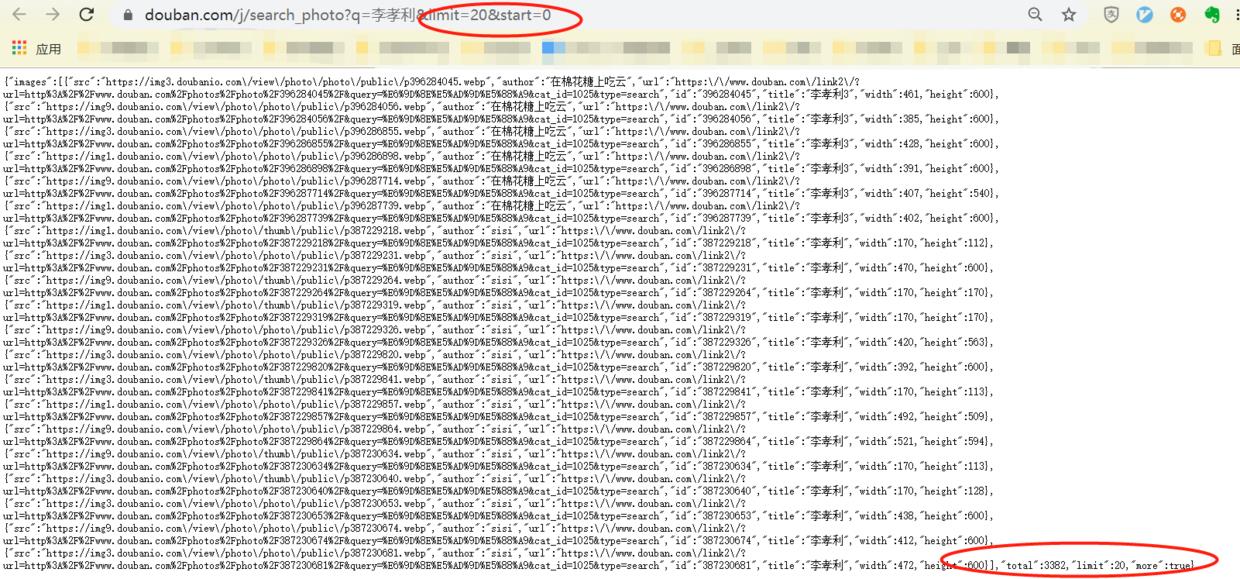
如果懂solr的朋友,会发现这个链接非常类似于solr的搜索,里面有要查询参数为q,查询限制的条数20条,start是开始的位置,结果是一个大的json,同时会有总数:3382个。
每个图片的信息如下:
{
"src": "https://img3.doubanio.com\\/view\\/photo\\/photo\\/public\\/p396284045.webp",
"author": "在棉花糖上吃云",
"url": "https:\\/\\/www.douban.com\\/link2\\/?url=http%3A%2F%2Fwww.douban.com%2Fphotos%2Fphoto%2F396284045%2F&query=%E6%9D%8E%E5%AD%9D%E5%88%A9&cat_id=1025&type=search",
"id": "396284045",
"title": "李孝利3",
"width": 461,
"height": 600
}
三 python准备
requests库是一个常用的用于http请求的模块,它使用python语言编写,可以方便的对网页进行爬取,可以通过下面命令安装:
pip install requests
selenium是web自动化测试工具,可以调用浏览器执行一些自动化操作,支持对网页元素的分析和提取等,对于比较复杂的场景,用它来编写爬虫是非常合适的。
pip install selenium
使用过程中如有问题,可以看下:https://www.jianshu.com/p/1531e12f8852来详细了解下。
代码如下:
# -*- coding: utf-8 -*-
import requests
import json
import sys
import io
import os
headers = {
\'Accept\': \'*/*\',
\'Accept-Encoding\': \'gzip, deflate\',
\'Accept-Language\': \'zh-CN,zh;q=0.9\',
\'Connection\': \'keep-alive\',
\'Cookie\': \'ll="118318"; bid=VphkMecYUeI; __yadk_uid=RmReW2rcZ2z0mvK7XU2Hk5lbJRkh9Xmt; viewed="1140457"; gr_user_id=06ee0f44-322d-4247-93ac-de144da52338; _vwo_uuid_v2=DC05E55FE4B8188FEF5DD65F5152BE5D2|7eed6e6d696f6c06984eef171f438b14; __utmz=30149280.1576832766.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=30149280; dbcl2="2241899:Qr3KzLK8mY4"; push_doumail_num=0; push_noty_num=0; __utmv=30149280.224; ck=QxRM; douban-fav-remind=1; __gads=ID=c2c2b4d1b545c075:T=1576833631:S=ALNI_ManfN_EbMMtHwjeyAGIuRlVSkk3kw; _pk_ses.100001.8cb4=*; ap_v=0,6.0; __utma=30149280.426358312.1576832766.1576840609.1576845825.3; __utmt=1; loc-last-index-location-id="118318"; _pk_id.100001.8cb4=9fac3e30c5487d2c.1576832764.3.1576845892.1576840608.; __utmb=30149280.8.10.1576845825\',
\'Host\': \'www.douban.com\',
\'Sec-Fetch-Mode\': \'cors\',
\'Sec-Fetch-Site\': \'same-origin\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36\',
\'X-Requested-With\': \'XMLHttpRequest\'
}
def download(picPath,src, id):
if not os.path.isdir(picPath):
os.mkdir(picPath)
dir = picPath+\'/\' + str(id) + \'.jpg\'
print(src)
try:
pic = requests.get(src)
fp = open(dir, \'wb\')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print(\'Sorrry,image cannot downloaded, url is error{}.\'.format(src))
def query_img(query,downloadUrl,headers):
realUrl = downloadUrl.format(query)
print(realUrl)
response = requests.get(realUrl,headers = headers,timeout=30)
respJson = json.loads(response.text,encoding=\'utf-8\')
picPath = \'F:\\\\python\\\\images\'
for image in respJson[\'images\']:
#print(image)
download(picPath,image[\'src\'], image[\'id\'])
if __name__ == "__main__":
query = \'李孝利\'
url = \'https://www.douban.com/j/search_photo?q=\\\'{}\\\'&limit=20&start=0\'
query_img(query,url,headers)
3.1 遇到requests请求返回为空的问题
r = requests.get(\'https://www.douban.com/j/search_photo?q=\'李孝利\'&limit=20&start=0\')
简单用这种请求是不行的,因为没有配置头,直接返回状态码为418,返回内容为空。
3.2 遇到编码一直有问题的导致无法解析
r = requests.get(\'https://www.douban.com/j/search_photo?q=\'李孝利\'&limit=20&start=0\',headers=headers)
print(r.content.decode(\'utf-8\'))
print(r.text)
print(r.encoding)
返回的编码为utf-8,但是r.content一直解析不了,很奇怪,这个问题也折腾了很久,最后我无意中打印下返回的头信息:
print (r.headers)
结果:
{\'Date\': \'Sat, 21 Dec 2019 02:19:21 GMT\',
\'Content-Type\': \'application/json; charset=utf-8\',
\'Transfer-Encoding\': \'chunked\', \'Connection\': \'keep-alive\', \'Keep-Alive\': \'timeout=30\', \'Vary\': \'Accept-Encoding\', \'X-Xss-Protection\': \'1; mode=block\', \'X-Douban-Mobileapp\': \'0\',
\'Expires\': \'Sun, 1 Jan 2006 01:00:00 GMT\',
\'Pragma\': \'no-cache\', \'Cache-Control\': \'must-revalidate, no-cache, private\', \'X-DAE-App\': \'bywater\', \'X-DAE-Instance\': \'default\', \'X-DAE-Mountpoint\': \'True\', \'Server\': \'dae\', \'Strict-Transport-Security\': \'max-age=15552000;\',
\'Content-Encoding\': \'br\'}
看样子也是正常,发现最后内容的编码为br,这是什么东西。原来是一种牛逼的压缩算法,压缩各项指标强于gzip,我设置请求头的时候,指定可以接受这种压缩算法:
\'Accept-Encoding\': \'gzip, deflate, br\',
简单的解决办法是去掉这个br,然后后面的各个步骤处理正常了。
3.3 下载图片大小为0
看了下返回的状态码是418,又是出错的,这个就知道了,原来我headers设置的有问题,这个具体的headers哪里获取那,其实也简单,就是通过浏览器访问一次,用开发者模式进去看看其中的请求头信息,搬过去就ok,至此简单图片批量下载完成。
本来一个简单的小脚本,但是整个过程还是蛮曲折的,应了那句话“绝知此事要躬行”,看上去懂了和实际操作还是有一段距离的。
四 一些参考
关于br的压缩算法有兴趣可以参考:
https://blog.csdn.net/weixin_40414337/article/details/88561066
以上是关于写python爬虫时,想抓图片的原图?的主要内容,如果未能解决你的问题,请参考以下文章