ListNet和ListMLE
Posted xd_xumaomao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ListNet和ListMLE相关的知识,希望对你有一定的参考价值。
背景
ListNet和ListMLE都是listwise的排序方法
ListNet
ListNet用如下公式表示一种排列的概率:

举个例子:
假设有3个doc <doc1, doc2, doc3>,对应的score为 <s1, s2, s3>,那么对于这样一种排列 <s2, s3, s1>,其概率为:
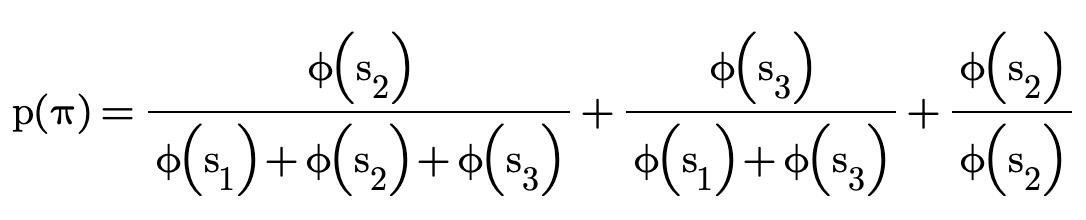
这样,得到排列的概率分布后,我们就可以用交叉熵来计算loss了:

可以看出LIstNet的计算一个query时间复杂度为n!,非常高。再实践中只会计算top k文档排列概率,时间复杂度降为n!/(n-k)!
ListMLE
ListMLE和ListNet的主要不同点在与,ListMLE采用了最大似然估计来计算损失,ListMLE的loss可以表示为:
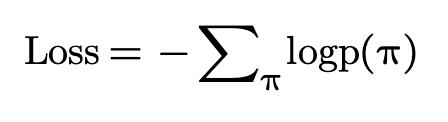
参考资料
《Learning to Rank: From Pairwise Approach to Listwise Approach》
《Listwise Approach to Learning to Rank - Theory and Algorithm》
利用Python将txt文件批量去除重复行内容
main.py
# -*- coding: utf-8 -*-
if __name__ == '__main__':
with open(r'cfg.txt', 'r', encoding='utf-8') as f:
listNet = f.readlines()
print(f"去重前数量:len(listNet)")
# print(listNet)
# 去除有’ \\n‘, ’ ‘,’\\n’
listNet = [x.strip() for x in listNet]
# print(listNet)
# 去除空字符串''
listNet = [x.strip() for x in listNet if x.strip() != '']
# listNet = list(filter(None, listNet))
print(f"去除空行后数量:len(listNet)")
# print(listNet)
# 去重
listNet = list(set(listNet))
print(f"去重后数量:len(listNet)")
# print(listNet)
with open(r'cfg_new.txt', 'w', encoding='utf-8') as f2:
for i in range(len(listNet)):
listNet[i] = listNet[i] + '\\n'
f2.writelines(listNet)
print(f"数据处理后,已成功写入文件!")
以上是关于ListNet和ListMLE的主要内容,如果未能解决你的问题,请参考以下文章