Python爬虫-爬取斗鱼网页selenium+bs
Posted 夏至稻花如白练,大暑池畔赏红莲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-爬取斗鱼网页selenium+bs相关的知识,希望对你有一定的参考价值。
爬取斗鱼网页(selenium+chromedriver得到网页,用Beasutiful Soup提取信息)
=============================
=================================

=======================================
#self.driver.page_source 得到页面源码用 xml解析
soup = BeautifulSoup(self.driver.page_source, \'xml\')
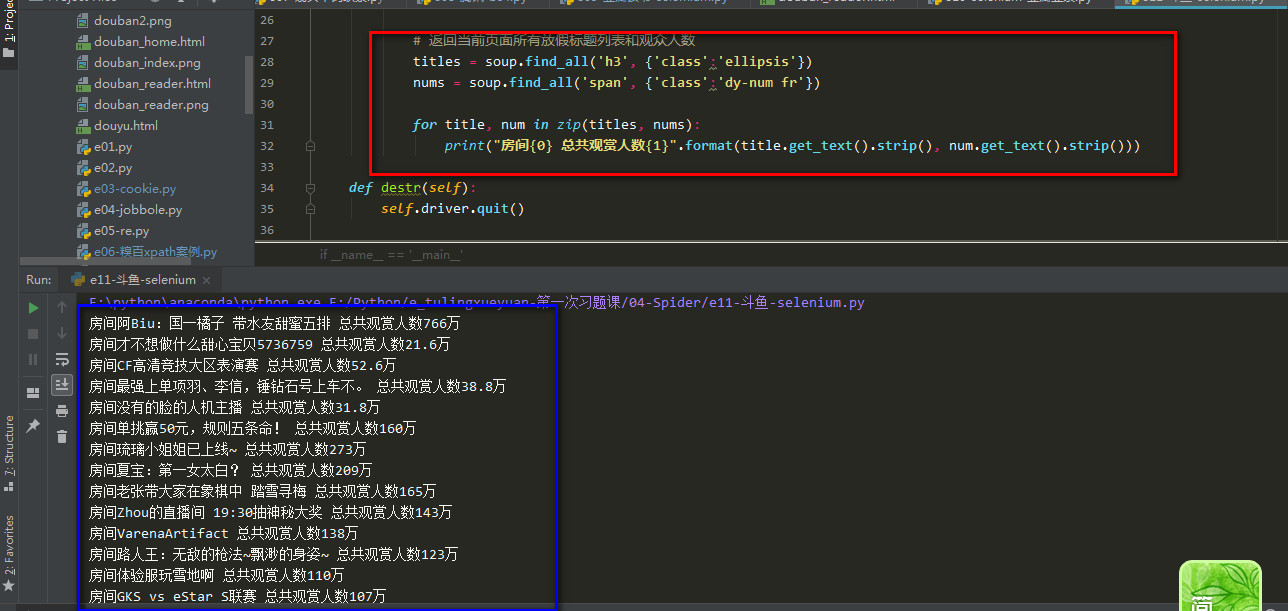
结果示例:
================================
1 \'\'\'\' 2 任务: 3 爬去斗鱼直播内容 4 https://www.douyu.com/directory/all 5 思路: 6 1. 利用selenium得到页面内容 7 2. 利用xpath或者bs等在页面中进行信息提取 8 \'\'\' 9 10 from selenium import webdriver 11 from bs4 import BeautifulSoup 12 13 14 class Douyu(): 15 #初始化方法 16 def setUp(self): 17 self.driver = webdriver.Chrome() 18 self.url = \'https://www.douyu.com/directory/all\' 19 20 21 def douyu(self): 22 self.driver.get(self.url) 23 24 while True: 25 soup = BeautifulSoup(self.driver.page_source, \'xml\') 26 27 # 返回当前页面所有放假标题列表和观众人数 28 titles = soup.find_all(\'h3\', {\'class\':\'ellipsis\'}) 29 nums = soup.find_all(\'span\', {\'class\':\'dy-num fr\'}) 30 31 for title, num in zip(titles, nums): 32 print("房间{0} 总共观赏人数{1}".format(title.get_text().strip(), num.get_text().strip())) 33 34 def destr(self): 35 self.driver.quit() 36 37 if __name__ == \'__main__\': 38 douyu = Douyu() 39 douyu.setUp() 40 douyu.douyu() 41 douyu.destr()
以上是关于Python爬虫-爬取斗鱼网页selenium+bs的主要内容,如果未能解决你的问题,请参考以下文章