怎么用Python写爬虫抓取网页数据
Posted AIData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么用Python写爬虫抓取网页数据相关的知识,希望对你有一定的参考价值。
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取。本篇介绍怎么写一个爬虫从网上抓取公开的数据。
很多语言都可以写爬虫,但是不同语言的难易程度不同,Python作为一种解释型的胶水语言,上手简单、入门容易,标准库齐全,还有丰富的各种开源库,语言本身提供了很多提高开发效率的语法糖,开发效率高,总之“人生苦短,快用Python”(Life is short, you need Python!)。在Web网站开发,科学计算,数据挖掘/分析,人工智能等很多领域广泛使用。
开发环境配置,Python3.5.2,Scrapy1.2.1,使用pip安装scrapy,命令:pip3 install Scrapy,此命令在Mac下会自动安装Scrapy的依赖包,安装过程中如果出现网络超时,多试几次。
创建工程
首先创建一个Scrapy工程,工程名为:kiwi,命令:scrapy startproject kiwi,将创建一些文件夹和文件模板。
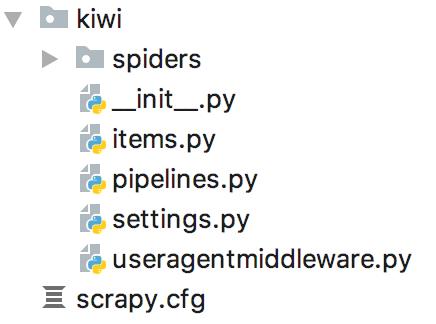
定义数据结构
settings.py是一些设置信息,items.py用来保存解析出来的数据,在此文件里定义一些数据结构,示例代码:
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # http://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class AuthorInfo(scrapy.Item): 12 authorName = scrapy.Field() # 作者昵称 13 authorUrl = scrapy.Field() # 作者Url 14 15 class ReplyItem(scrapy.Item): 16 content = scrapy.Field() # 回复内容 17 time = scrapy.Field() # 发布时间 18 author = scrapy.Field() # 回复人(AuthorInfo) 19 20 class TopicItem(scrapy.Item): 21 title = scrapy.Field() # 帖子标题 22 url = scrapy.Field() # 帖子页面Url 23 content = scrapy.Field() # 帖子内容 24 time = scrapy.Field() # 发布时间 25 author = scrapy.Field() # 发帖人(AuthorInfo) 26 reply = scrapy.Field() # 回复列表(ReplyItem list) 27 replyCount = scrapy.Field() # 回复条数
上面TopicItem中嵌套了AuthorInfo和ReplyItem list,但是初始化类型必须是scrapy.Field(),注意这三个类都需要从scrapy.Item继续。
创建爬虫蜘蛛
工程目录spiders下的kiwi_spider.py文件是爬虫蜘蛛代码,爬虫代码写在这个文件里。示例以爬豆瓣群组里的帖子和回复为例。
1 # -*- coding: utf-8 -*- 2 from scrapy.selector import Selector 3 from scrapy.spiders import CrawlSpider, Rule 4 from scrapy.linkextractors import LinkExtractor 5 6 from kiwi.items import TopicItem, AuthorInfo, ReplyItem 7 class KiwiSpider(CrawlSpider): 8 name = "kiwi" 9 allowed_domains = ["douban.com"] 10 11 anchorTitleXPath = \'a/text()\' 12 anchorHrefXPath = \'a/@href\' 13 14 start_urls = [ 15 "https://www.douban.com/group/topic/90895393/?start=0", 16 ] 17 rules = ( 18 Rule( 19 LinkExtractor(allow=(r\'/group/[^/]+/discussion\\?start=\\d+\',)), 20 callback=\'parse_topic_list\', 21 follow=True 22 ), 23 Rule( 24 LinkExtractor(allow=(r\'/group/topic/\\d+/$\',)), # 帖子内容页面 25 callback=\'parse_topic_content\', 26 follow=True 27 ), 28 Rule( 29 LinkExtractor(allow=(r\'/group/topic/\\d+/\\?start=\\d+\',)), # 帖子内容页面 30 callback=\'parse_topic_content\', 31 follow=True 32 ), 33 ) 34 35 # 帖子详情页面 36 def parse_topic_content(self, response): 37 # 标题XPath 38 titleXPath = \'//html/head/title/text()\' 39 # 帖子内容XPath 40 contentXPath = \'//div[@class="topic-content"]/p/text()\' 41 # 发帖时间XPath 42 timeXPath = \'//div[@class="topic-doc"]/h3/span[@class="color-green"]/text()\' 43 # 发帖人XPath 44 authorXPath = \'//div[@class="topic-doc"]/h3/span[@class="from"]\' 45 46 item = TopicItem() 47 # 当前页面Url 48 item[\'url\'] = response.url 49 # 标题 50 titleFragment = Selector(response).xpath(titleXPath) 51 item[\'title\'] = str(titleFragment.extract()[0]).strip() 52 53 # 帖子内容 54 contentFragment = Selector(response).xpath(contentXPath) 55 strs = [line.extract().strip() for line in contentFragment] 56 item[\'content\'] = \'\\n\'.join(strs) 57 # 发帖时间 58 timeFragment = Selector(response).xpath(timeXPath) 59 if timeFragment: 60 item[\'time\'] = timeFragment[0].extract() 61 62 # 发帖人信息 63 authorInfo = AuthorInfo() 64 authorFragment = Selector(response).xpath(authorXPath) 65 if authorFragment: 66 authorInfo[\'authorName\'] = authorFragment[0].xpath(self.anchorTitleXPath).extract()[0] 67 authorInfo[\'authorUrl\'] = authorFragment[0].xpath(self.anchorHrefXPath).extract()[0] 68 69 item[\'author\'] = dict(authorInfo) 70 71 # 回复列表XPath 72 replyRootXPath = r\'//div[@class="reply-doc content"]\' 73 # 回复时间XPath 74 replyTimeXPath = r\'div[@class="bg-img-green"]/h4/span[@class="pubtime"]/text()\' 75 # 回复人XPath 76 replyAuthorXPath = r\'div[@class="bg-img-green"]/h4\' 77 78 replies = [] 79 itemsFragment = Selector(response).xpath(replyRootXPath) 80 for replyItemXPath in itemsFragment: 81 replyItem = ReplyItem() 82 # 回复内容 83 contents = replyItemXPath.xpath(\'p/text()\') 84 strs = [line.extract().strip() for line in contents] 85 replyItem[\'content\'] = \'\\n\'.join(strs) 86 # 回复时间 87 timeFragment = replyItemXPath.xpath(replyTimeXPath) 88 if timeFragment: 89 replyItem[\'time\'] = timeFragment[0].extract() 90 # 回复人 91 replyAuthorInfo = AuthorInfo() 92 authorFragment = replyItemXPath.xpath(replyAuthorXPath) 93 if authorFragment: 94 replyAuthorInfo[\'authorName\'] = authorFragment[0].xpath(self.anchorTitleXPath).extract()[0] 95 replyAuthorInfo[\'authorUrl\'] = authorFragment[0].xpath(self.anchorHrefXPath).extract()[0] 96 97 replyItem[\'author\'] = dict(replyAuthorInfo) 98 # 添加进回复列表 99 replies.append(dict(replyItem)) 100 101 item[\'reply\'] = replies 102 yield item 103 104 # 帖子列表页面 105 def parse_topic_list(self, response): 106 # 帖子列表XPath(跳过表头行) 107 topicRootXPath = r\'//table[@class="olt"]/tr[position()>1]\' 108 # 单条帖子条目XPath 109 titleXPath = r\'td[@class="title"]\' 110 # 发帖人XPath 111 authorXPath = r\'td[2]\' 112 # 回复条数XPath 113 replyCountXPath = r\'td[3]/text()\' 114 # 发帖时间XPath 115 timeXPath = r\'td[@class="time"]/text()\' 116 117 topicsPath = Selector(response).xpath(topicRootXPath) 118 for topicItemPath in topicsPath: 119 item = TopicItem() 120 titlePath = topicItemPath.xpath(titleXPath) 121 item[\'title\'] = titlePath.xpath(self.anchorTitleXPath).extract()[0] 122 item[\'url\'] = titlePath.xpath(self.anchorHrefXPath).extract()[0] 123 # 发帖时间 124 timePath = topicItemPath.xpath(timeXPath) 125 if timePath: 126 item[\'time\'] = timePath[0].extract() 127 # 发帖人 128 authorPath = topicItemPath.xpath(authorXPath) 129 authInfo = AuthorInfo() 130 authInfo[\'authorName\'] = authorPath[0].xpath(self.anchorTitleXPath).extract()[0] 131 authInfo[\'authorUrl\'] = authorPath[0].xpath(self.anchorHrefXPath).extract()[0] 132 item[\'author\'] = dict(authInfo) 133 # 回复条数 134 replyCountPath = topicItemPath.xpath(replyCountXPath) 135 item[\'replyCount\'] = replyCountPath[0].extract() 136 137 item[\'content\'] = \'\' 138 yield item 139 140 parse_start_url = parse_topic_content
特别注意
1、KiwiSpider需要改成从CrawlSpider类继承,模板生成的代码是从Spider继承的,那样的话不会去爬rules里的页面。
2、parse_start_url = parse_topic_list 是定义入口函数,从CrawlSpider类的代码里可以看到parse函数回调的是parse_start_url函数,子类可以重写这个函数,也可以像上面代码那样给它赋值一个新函数。
3、start_urls里是入口网址,可以添加多个网址。
4、rules里定义在抓取到的网页中哪些网址需要进去爬,规则和对应的回调函数,规则用正则表达式写。上面的示例代码,定义了继续抓取帖子详情首页及分页。
5、注意代码里用dict()包装的部分,items.py文件里定义数据结构的时候,author属性实际需要的是AuthorInfo类型,赋值的时候必须用dict包装起来,item[\'author\'] = authInfo 赋值会报Error。
6、提取内容的时候利用XPath取出需要的内容,有关XPath的资料参看:XPath教程 http://www.w3school.com.cn/xpath/。开发过程中可以利用浏览器提供的工具查看XPath,比如Firefox 浏览器中的FireBug、FirePath插件,对于https://www.douban.com/group/python/discussion?start=0这个页面,XPath规则“//td[@class="title"]”可以获取到帖子标题列表,示例:
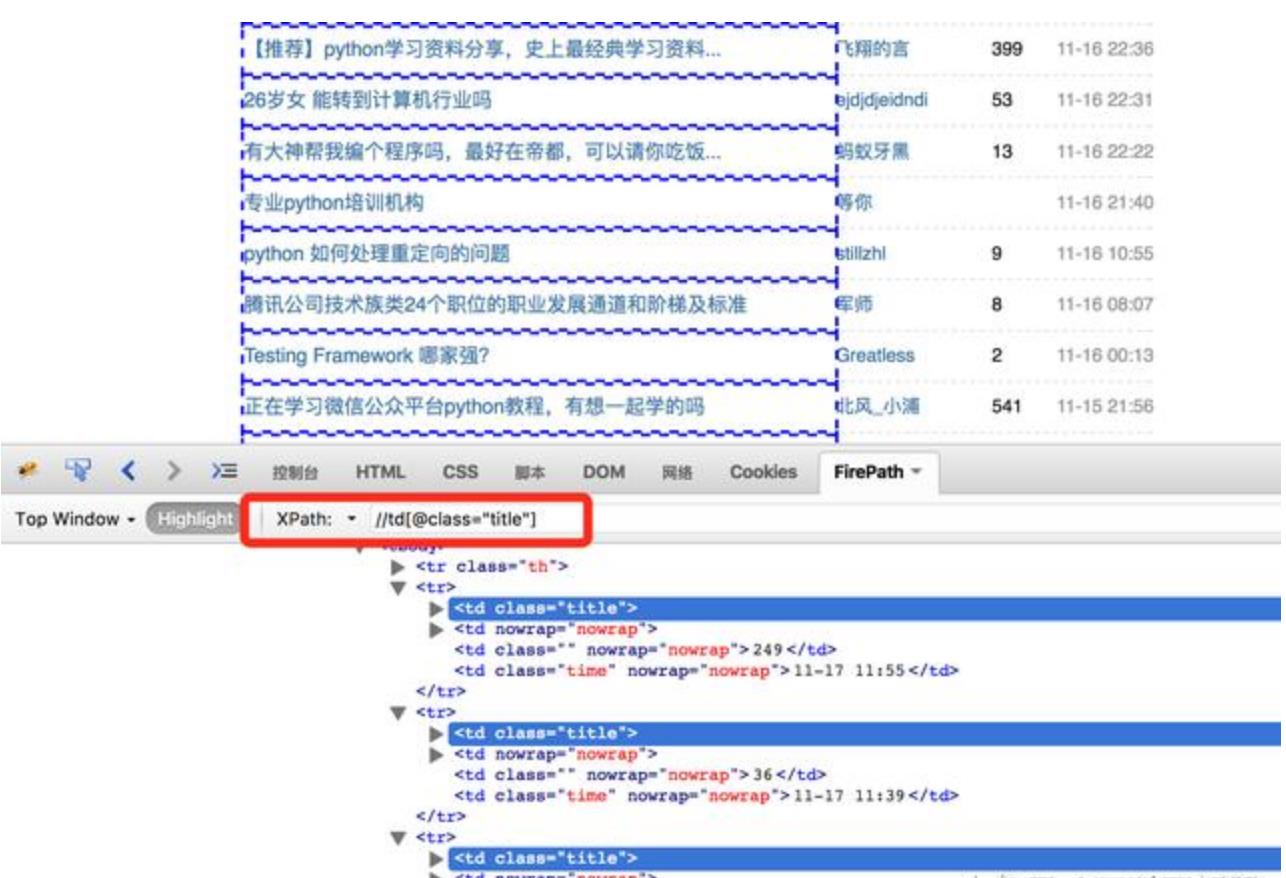
上图红框中可以输入XPath规则,方便测试XPath的规则是否符合要求。新版Firefox可以安装 Try XPath 这个插件 查看XPath,Chrome浏览器可以安装 XPath Helper 插件。
使用随机UserAgent
为了让网站看来更像是正常的浏览器访问,可以写一个Middleware提供随机的User-Agent,在工程根目录下添加文件useragentmiddleware.py,示例代码:
1 # -*-coding:utf-8-*- 2 3 import random 4 from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware 5 6 7 class RotateUserAgentMiddleware(UserAgentMiddleware): 8 def __init__(self, user_agent=\'\'): 9 self.user_agent = user_agent 10 11 def process_request(self, request, spider): 12 ua = random.choice(self.user_agent_list) 13 if ua: 14 request.headers.setdefault(\'User-Agent\', ua) 15 16 # for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php 17 user_agent_list = [ \\ 18 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \\ 19 "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \\ 20 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \\ 21 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \\ 22 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \\ 23 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \\ 24 "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \\ 25 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \\ 26 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \\ 27 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \\ 28 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \\ 29 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \\ 30 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \\ 31 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \\ 32 "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \\ 33 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \\ 34 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \\ 35 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" 36 ]
修改settings.py,添加下面的设置,
DOWNLOADER_MIDDLEWARES = { \'kiwi.useragentmiddleware.RotateUserAgentMiddleware\': 1, }
同时禁用cookie,COOKIES_ENABLED = False。
运行爬虫
切换到工程根目录,输入命令:scrapy crawl kiwi,console窗口可以看到打印出来的数据,或者使用命令“scrapy crawl kiwi -o result.json -t json”将结果保存到文件里。
怎么抓取用JS代码动态输出的网页数据
上面的例子对由执行js代码输出数据的页面不适用,好在Python的工具库多,可以安装phantomjs这个工具,从官网下载解压即可。下面以抓取 http://www.kjj.com/index_kfjj.html 这个网页的基金净值数据为例,这个页面的数据是由js代码动态输出的,js代码执行之后才会输出基金净值列表。fund_spider.py代码
1 # -*- coding: utf-8 -*- 2 from scrapy.selector import Selector 3 from datetime import datetime 4 from selenium import webdriver 5 from fundequity import FundEquity 6 7 class PageSpider(object): 8 def __init__(self): 9 phantomjsPath = "/Library/Frameworks/Python.framework/Versions/3.5/phantomjs/bin/phantomjs" 10 cap = webdriver.DesiredCapabilities.PHANTOMJS 11 cap["phantomjs.page.settings.resourceTimeout"] = 1000 12 cap["phantomjs.page.settings.loadImages"] = False 13 cap["phantomjs.page.settings.disk-cache"] = False 14 self.driver = webdriver.PhantomJS(executable_path=phantomjsPath, desired_capabilities=cap) 15 16 def fetchPage(self, url): 17 self.driver.get(url) 18 html = self.driver.page_source 19 return html 20 21 def parse(self, html): 22 fundListXPath = r\'//div[@id="maininfo_all"]/table[@id="ilist"]/tbody/tr[position()>1]\' 23 itemsFragment = Selector(text=html).xpath(fundListXPath) 24 for itemXPath in itemsFragment: 25 attrXPath = itemXPath.xpath(r\'td[1]/text()\') 26 text = attrXPath[0].extract().strip() 27 if text != "-": 28 fe = FundEquity() 29 fe.serial = text 30 31 attrXPath = itemXPath.xpath(r\'td[2]/text()\') 32 text = attrXPath[0].extract().strip() 33 fe.date = datetime.strptime(text, "%Y-%m-%d") 34 35 attrXPath = itemXPath.xpath(r\'td[3]/text()\') 36 text = attrXPath[0].extract().strip() 37 fe.code = text 38 39 attrXPath = itemXPath.xpath(r\'td[4]/a/text()\') 40 text = attrXPath[0].extract().strip() 41 fe.name = text 42 43 attrXPath = itemXPath.xpath(r\'td[5]/text()\') 44 text = attrXPath[0].extract().strip() 45 fe.equity = text 46 47 attrXPath = itemXPath.xpath(r\'td[6]/text()\') 48 text = attrXPath[0].extract().strip() 49 fe.accumulationEquity = text 50 51 attrXPath = itemXPath.xpath(r\'td[7]/font/text()\') 52 text = attrXPath[0].extract().strip() 53 fe.increment = text 54 55 attrXPath = itemXPath.xpath(r\'td[8]/font/text()\') 56 text = attrXPath[0].extract().strip().strip(\'%\') 57 fe.growthRate = text 58 59 attrXPath = itemXPath.xpath(r\'td[9]/a/text()\') 60 if len(attrXPath) > 0: 61 text = attrXPath[0].extract().strip() 62 if text == "购买": 63 fe.canBuy = True 64 else: 65 fe.canBuy = False 66 67 attrXPath = itemXPath.xpath(r\'td[10]/font/text()\') 68 if len(attrXPath) > 0: 69 text = attrXPath[0].extract().strip() 70 if text == "赎回": 71 fe.canRedeem = True 72 else: 73 fe.canRedeem = False 74 75 yield fe 76 77 def __del__(self): 78 self.driver.quit() 79 80 def test(): 81 spider = PageSpider() 82 html = spider.fetchPage("http://www.kjj.com/index_kfjj.html") 83 for item in spider.parse(html): 84 print(item) 85 del spider 86 87 if __name__ == "__main__": 88 test()
1 # -*- coding: utf-8 -*- 2 from datetime import date 3 4 # 基金净值信息 5 class FundEquity(object): 6 def __init__(self): 7 # 类实例即对象的属性 8 self.__serial = 0 # 序号 9 self.__date = None # 日期 10 self.__code = "" # 基金代码 11 self.__name = "" # 基金名称 12 self.__equity = 0.0 # 单位净值 13 self.__accumulationEquity = 0.0 # 累计净值 14 self.__increment = 0.0 # 增长值 15 self.__growthRate = 0.0 # 增长率 16 self.__canBuy = False # 是否可以购买 17 self.__canRedeem = True # 是否能赎回 18 19 @property 20 def serial(self): 21 return self.__serial以上是关于怎么用Python写爬虫抓取网页数据的主要内容,如果未能解决你的问题,请参考以下文章