Python爬虫爬取糗事百科(xpath+re)
Posted 夏至稻花如白练,大暑池畔赏红莲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫爬取糗事百科(xpath+re)相关的知识,希望对你有一定的参考价值。
爬取糗事百科,用xpath、re提取
===================================================
=====================================================
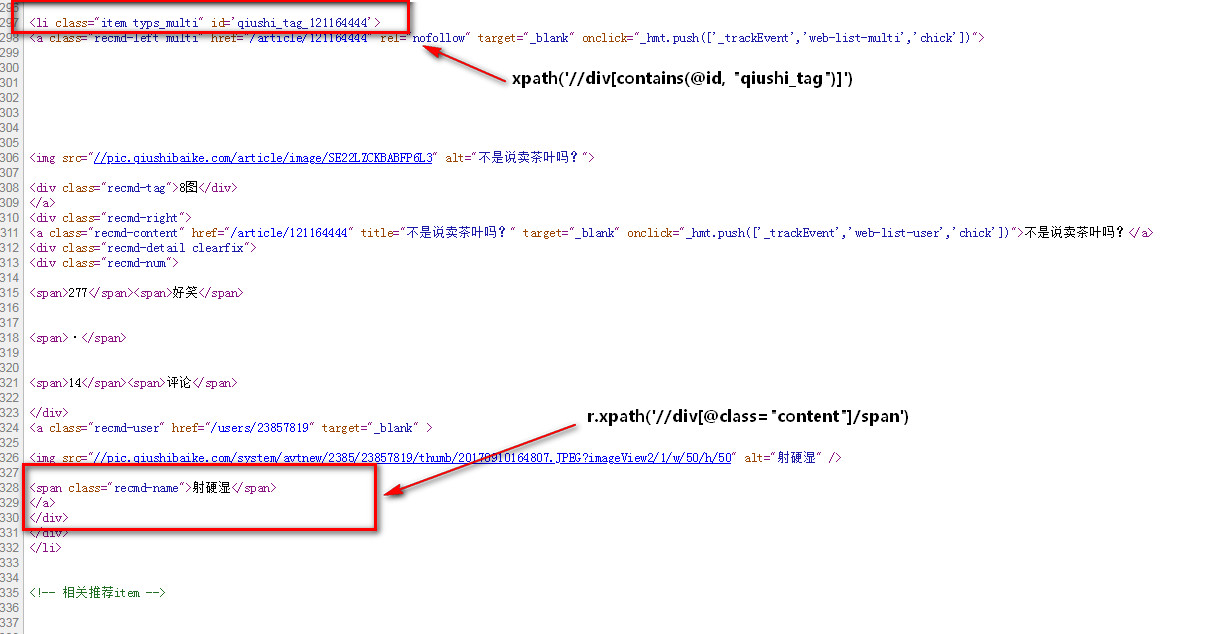
1 \'\'\' 2 爬取丑事百科, 页面自己来找 3 分析: 4 1. 需要用到requests爬去页面,用xpath、re来提取数字 5 2. 可提取信息谁用户头像链接,段子内容,点赞,好评次数 6 3. 保存到json文件中 7 8 大致分三部分 9 1. down下页面 10 2。 利用xpath提取信息 11 3. 保存文件落地 12 \'\'\' 13 14 import requests 15 from lxml import etree 16 17 url = "https://www.qiushibaike.com/8hr/page/1/" 18 headers = { 19 "User-Agent": \'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36\', 20 "Accept":\'ext/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\', 21 "Accept-Language":\'zh-CN,zh;q=0.9\' 22 } 23 24 # 下载页面 25 rsp = requests.get(url, headers=headers) 26 html = rsp.text 27 28 # 把页面解析成html 29 html = etree.HTML(html) 30 print(html.text) 31 rst = html.xpath(\'//div[contains(@id, "qiushi_tag")]\') 32 33 for r in rst: 34 print(r.text) 35 item = {} 36 print(r) 37 38 content = r.xpath(\'//div[@class="content"]/span\')[0].text 39 print(content)
以上是关于Python爬虫爬取糗事百科(xpath+re)的主要内容,如果未能解决你的问题,请参考以下文章