Python基于dtw实现股票预测(多线程)
Posted 云山之巅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基于dtw实现股票预测(多线程)相关的知识,希望对你有一定的参考价值。
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Dec 4 08:53:08 2018 4 5 @author: zhen 6 """ 7 from dtw import fastdtw 8 import matplotlib.pyplot as plt 9 import numpy as np 10 import pandas as pd 11 import threading 12 import time 13 from datetime import datetime 14 15 def normalization(x): # np.std:计算矩阵的标准差(方差的算术平方根) 16 return (x - np.mean(x)) / np.std(x) 17 18 def corrcoef(a,b): 19 corrc = np.corrcoef(a,b) # 计算皮尔逊相关系数,用于度量两个变量之间的相关性,其值介于-1到1之间 20 corrc = corrc[0,1] 21 return (16 * ((1 - corrc) / (1 + corrc)) ** 1) # ** 表示乘方 22 23 print("begin Main Thread") 24 startTimeStamp = datetime.now() # 获取当前时间 25 # 加载数据 26 filename = \'C:/Users/zhen/.spyder-py3/sh000300_2017.csv\' 27 # 获取第一,二列的数据 28 all_date = pd.read_csv(filename,usecols=[0, 1], dtype = \'str\') 29 all_date = np.array(all_date) 30 data = all_date[:, 0] 31 times = all_date[:, 1] 32 33 data_points = pd.read_csv(filename,usecols=[3]) 34 data_points = np.array(data_points) 35 data_points = data_points[:,0] #数据 36 37 topk = 10 #只显示top-10 38 baselen = 100 # 假设在50到150之间变化 39 basebegin = 361 40 basedata = data[basebegin]+\' \'+times[basebegin]+\'~\'+data[basebegin+baselen-1]+\' \'+times[basebegin+baselen-1] 41 length = len(data_points) #数据长度 42 43 # 定义自定义线程类 44 class Thread_Local(threading.Thread): 45 def __init__(self, thread_id, name, counter): 46 threading.Thread.__init__(self) 47 self.thread_id = thread_id 48 self.name = name 49 self.counter = counter 50 self.__running = threading.Event() # 标识停止线程 51 self.__running.set() # 设置为True 52 53 def run(self): 54 print("starting %s" % self.name) 55 split_data(self, self.counter) # 执行代码逻辑 56 57 def stop(self): 58 self.__running.clear() 59 60 # 分割片段并执行匹配,多线程 61 def split_data(self, split_len): 62 base = data_points[basebegin:basebegin+baselen] # 获取初始要匹配的数据 63 subseries = [] 64 dateseries = [] 65 for j in range(0, length): 66 if (j < (basebegin - split_len) or j > (basebegin + split_len - 1)) and j <length - split_len: 67 subseries.append(data_points[j:j+split_len]) 68 dateseries.append(j) #开始位置 69 search(self, subseries, base, dateseries) # 调用模式匹配 70 71 # 定义结果变量 72 result = [] 73 base_list = [] 74 date_list = [] 75 def search(self, subseries, base, dateseries): 76 # 片段搜索 77 listdistance = [] 78 for i in range(0, len(subseries)): 79 tt = np.array(subseries[i]) 80 dist, cost, acc, path = fastdtw(base, tt, dist=\'euclidean\') 81 listdistance.append(dist) 82 # distance = corrcoef(base, tt) 83 # listdistance.append(distance) 84 # 排序 85 index = np.argsort(listdistance, kind=\'quicksort\') #排序,返回排序后的索引序列 86 result.append(subseries[index[0]]) 87 print("result length is %d" % len(result)) 88 base_list.append(base) 89 date_list.append(dateseries[index[0]]) 90 # 关闭线程 91 self.stop() 92 93 # 变换数据(收缩或扩展),生成50到150之间的数据,间隔为10 94 loc = 0 95 for split_len in range(round(0.5 * baselen), round(1.5 * baselen), 10): 96 # 执行匹配 97 thread = Thread_Local(1, "Thread" + str(loc), split_len) 98 loc += 1 99 # 开启线程 100 thread.start() 101 102 boo = 1 103 104 while(boo > 0): 105 if(len(result) < 10): 106 if(boo % 100 == 0): 107 print("has running %d s" % boo) 108 boo += 1 109 time.sleep(1) 110 else: 111 boo = 0 112 113 # 片段搜索 114 listdistance = [] 115 for i in range(0, len(result)): 116 tt = np.array(result[i]) 117 dist, cost, acc, path = fastdtw(base_list[i], tt, dist=\'euclidean\') 118 # distance = corrcoef(base_list[i], tt) 119 listdistance.append(dist) 120 # 最终排序 121 index = np.argsort(listdistance, kind=\'quicksort\') #排序,返回排序后的索引序列 122 print("closed Main Thread") 123 endTimeStamp = datetime.now() 124 # 结果集对比 125 plt.figure(0) 126 plt.plot(normalization(base_list[index[0]]),label= basedata,linewidth=\'2\') 127 length = len(result[index[0]]) 128 begin = data[date_list[index[0]]] + \' \' + times[date_list[index[0]]] 129 end = data[date_list[index[0]] + length - 1] + \' \' + times[date_list[index[0]] + length - 1] 130 label = begin + \'~\' + end 131 plt.plot(normalization(result[index[0]]), label=label, linewidth=\'2\') 132 plt.legend(loc=\'lower right\') 133 plt.title(\'normal similarity search\') 134 plt.show() 135 print(\'run time\', (endTimeStamp-startTimeStamp).seconds, "s")
结果:


has running 100 s has running 200 s has running 300 s has running 400 s has running 500 s has running 600 s has running 700 s has running 800 s has running 900 s has running 1000 s has running 1100 s has running 1200 s has running 1300 s has running 1400 s has running 1500 s has running 1600 s has running 1700 s has running 1800 s has running 1900 s has running 2000 s has running 2100 s has running 2200 s has running 2300 s has running 2400 s has running 2500 s has running 2600 s has running 2700 s has running 2800 s has running 2900 s has running 3000 s has running 3100 s has running 3200 s has running 3300 s has running 3400 s has running 3500 s has running 3600 s has running 3700 s has running 3800 s has running 3900 s has running 4000 s has running 4100 s has running 4200 s has running 4300 s has running 4400 s has running 4500 s has running 4600 s has running 4700 s has running 4800 s has running 4900 s has running 5000 s has running 5100 s has running 5200 s has running 5300 s has running 5400 s has running 5500 s has running 5600 s has running 5700 s has running 5800 s has running 5900 s has running 6000 s has running 6100 s has running 6200 s has running 6300 s has running 6400 s has running 6500 s has running 6600 s has running 6700 s has running 6800 s has running 6900 s has running 7000 s has running 7100 s has running 7200 s has running 7300 s has running 7400 s has running 7500 s has running 7600 s has running 7700 s has running 7800 s has running 7900 s has running 8000 s has running 8100 s has running 8200 s has running 8300 s has running 8400 s has running 8500 s has running 8600 s has running 8700 s has running 8800 s has running 8900 s has running 9000 s has running 9100 s has running 9200 s has running 9300 s has running 9400 s has running 9500 s has running 9600 s has running 9700 s has running 9800 s has running 9900 s has running 10000 s has running 10100 s has running 10200 s has running 10300 s has running 10400 s has running 10500 s has running 10600 s has running 10700 s has running 10800 s has running 10900 s has running 11000 s has running 11100 s has running 11200 s has running 11300 s has running 11400 s has running 11500 s has running 11600 s has running 11700 s has running 11800 s has running 11900 s has running 12000 s has running 12100 s has running 12200 s has running 12300 s has running 12400 s has running 12500 s has running 12600 s has running 12700 s has running 12800 s has running 12900 s has running 13000 s has running 13100 s has running 13200 s has running 13300 s has running 13400 s has running 13500 s has running 13600 s has running 13700 s has running 13800 s has running 13900 s has running 14000 s has running 14100 s has running 14200 s has running 14300 s has running 14400 s result length is 1 result length is 2 has running 14500 s has running 14600 s has running 14700 s has running 14800 s result length is 3 has running 14900 s has running 15000 s result length is 4 has running 15100 s has running 15200 s has running 15300 s has running 15400 s result length is 5 has running 15500 s has running 15600 s has running 15700 s has running 15800 s has running 15900 s has running 16000 s has running 16100 s has running 16200 s result length is 6 has running 16300 s has running 16400 s has running 16500 s has running 16600 s result length is 7 result length is 8 has running 16700 s result length is 9 result length is 10 closed Main Thread
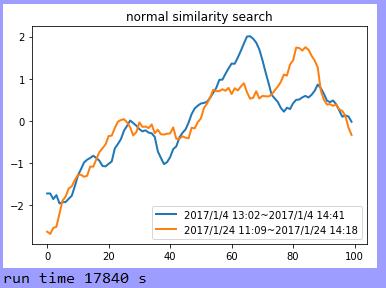
以上是关于Python基于dtw实现股票预测(多线程)的主要内容,如果未能解决你的问题,请参考以下文章