斯凯奇go walk 2 和 3 的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯凯奇go walk 2 和 3 的区别相关的知识,希望对你有一定的参考价值。
参考技术A 斯凯奇gowalk
2
和
3
的区别:
go
walk系列一直是斯凯奇的主打款式,比较受欢迎,上脚非常舒服。
go
walk
2:指2代。
go
walk
3:指3代。
外观方面3代看起来比2代精神了一点,区别就是go
walk
3是go
walk
2的升级版。
机器学习之朴素贝叶斯NB及实例
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第二
【Python】:排名第三
【算法】:排名第四
贝叶斯定理是以英国数学家贝叶斯命名,用来解决两个条件概率之间的关系问题。简单的说就是在已知P(A|B)时如何获得P(B|A)的概率。朴素贝叶斯(Naive Bayes)假设特征P(A)在特定结果P(B)下是独立的。
1.1 简述
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本文将首先介绍贝叶斯分类算法的基础——贝叶斯定理;然后通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。
1.2 贝叶斯定理
每次提到贝叶斯定理,我心中的崇敬之情都油然而生,倒不是因为这个定理多高深,而是因为它特别有用。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。条件概率表示事件B已经发生的前提下,事件A发生的概率,其基本求解公式为:
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
=\frac{P(A|B)P(B)}{P(A)}")
1.3 分类原理和流程
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,其思想基础为:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设 为一个待分类项,而每个a为x的一个特征属性。
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合 。
。
3、计算,P(y_2|x),...,P(y_n|x)") 。
。
4、如果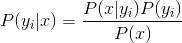 ,则
,则 。
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即,P(a_2|y_1),...,P(a_m|y_1);P(a_1|y_2),P(a_2|y_2),...,P(a_m|y_2);...;P(a_1|y_n),P(a_2|y_n),...,P(a_m|y_n)")
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
P(y_i)=P(a_1|y_i)P(a_2|y_i)...P(a_m|y_i)P(y_i)=P(y_i)\prod^m_{j=1}P(a_j|y_i)")
根据上述分析,朴素贝叶斯分类的流程可以由下图表示:
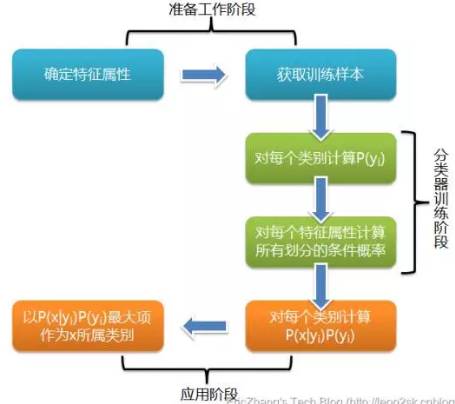
需要考虑的问题就是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
1.4 实例:检测SNS社区中不真实账号
为了简单起见,对例子中的数据做了适当的简化。对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:
a1:{a<=0.05, 0.05<a<0.2, a>=0.2}
a1:{a<=0.1, 0.1<a<0.8, a>=0.8}
a3:{a=0(不是),a=1(是)}
2、获取训练样本
使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
=8900/100000=0.89")
=110/100000=0.11")
4、计算每个类别条件下各个特征属性划分的频率
=0.2")
=0.1")
=0.2")
=0.1")
=0.2")
=0.8")
=0.9")
=0.1")
5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
招募 志愿者
广告、商业合作
请发邮件:357062955@qq.com
喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!
以上是关于斯凯奇go walk 2 和 3 的区别的主要内容,如果未能解决你的问题,请参考以下文章