day04 基本数据类型与基本运算符
Posted Dream-Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day04 基本数据类型与基本运算符相关的知识,希望对你有一定的参考价值。
【昨日回顾】
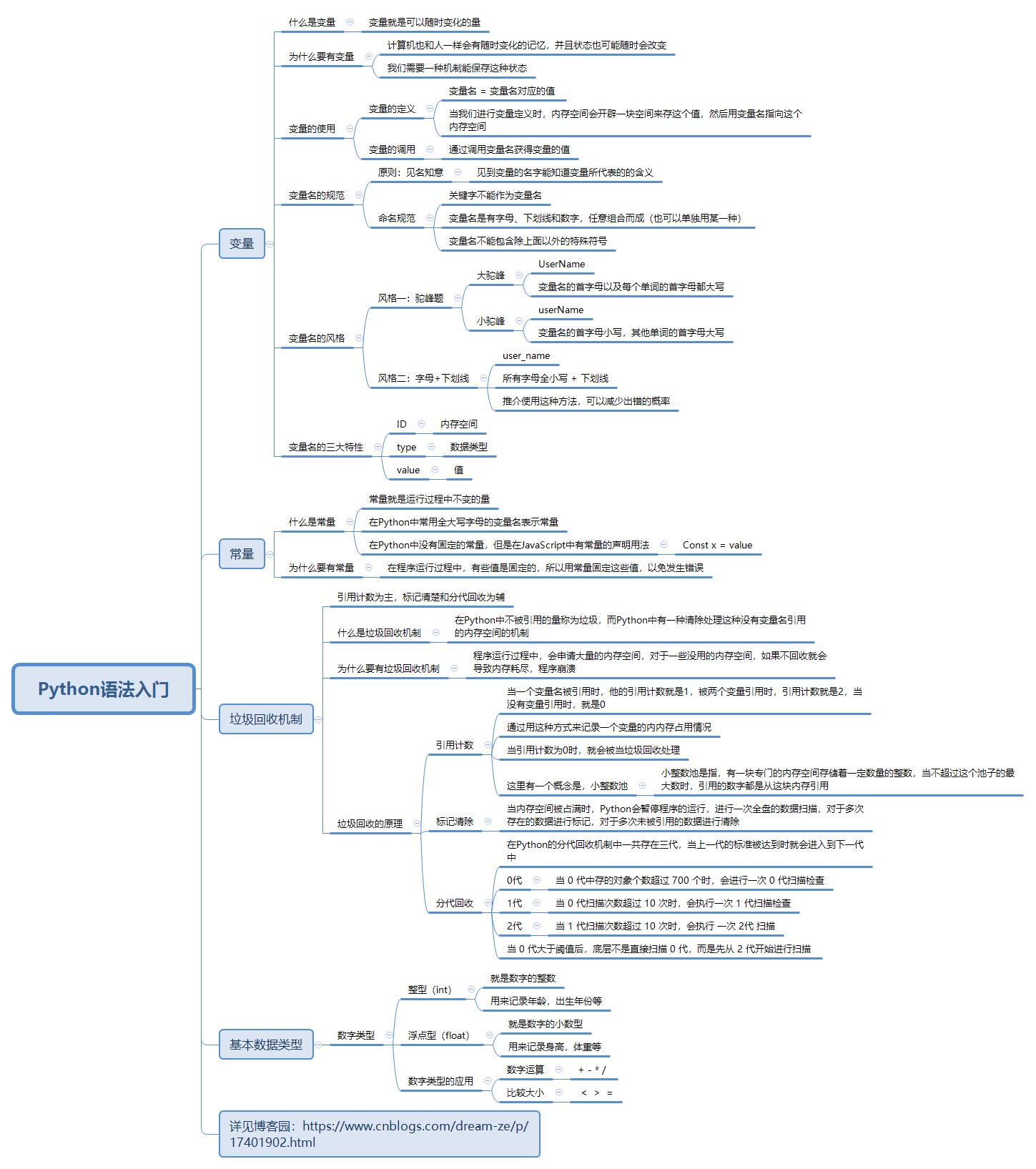
【四】基本数据类型
- 我们学习变量是为了让计算机能够像人一样去记忆事物的某种状态
- 而变量的值就是用来存储事物状态的,很明显事物的状态分成不同种类的(比如人的年龄,身高,职位,工资等等)
- 所以变量值也应该有不同的类型,例如
salary = 3.1 # 用浮点型去记录薪资
age = 18 # 用整型去记录年龄
name = \'lili\' # 用字符串类型去记录人名
【1】数字类型
(1)整形(int)
(1.1)作用
- 用来记录人的年龄,出生年份,学生人数等整数相关的状态

(1.2)定义
age=18
birthday=1990
student_count=48
(2)浮点型(float)
(2.1)作用
- 用来记录人的身高,体重,薪资等小数相关的状态

(2.2)定义
height=172.3
weight=103.5
salary=15000.89
(3)数字类型的应用
(3.1)数字运算
>>> a = 1
>>> b = 3
>>> c = a + b
>>> c
4
(3.2)比较大小
>>> x = 10
>>> y = 11
>>> x > y
False
【2】字符串(str)
(1)作用
- 用来记录人的名字,家庭住址,性别等描述性质的状态
- 用来记录描述性信息
- eg:姓名 地址 邮箱...
(2)定义方式
方式1:
name = \'kevin\'
方式2:
name = "kevin"
方式3:
name = \'\'\'kevin\'\'\' # (当左边有赋值符号和遍历名的时候,它就是字符串)
方式4:
name = """kevin""" # (当左边有赋值符号和遍历名的时候,它就是字符串)
# ps:用引号引起来的部分
-
对于变量名的值
- 用单引号、双引号、多引号,都可以定义字符串
- 本质上是没有区别的
-
但是
-
1、需要考虑引号嵌套的配对问题
msg = "My name is Tony , I\'m 18 years old!,hope your life : \'wonderful!\'" msg = \'My name is Tony , I\'m 18 years old!,hope your life : "wonderful!"\'\'\'\'注意:当有引号套用的情况下,外面是单引号里面就要是双引号,外面是双引号里面就要是单引号\'\'\'
-
2、多引号可以写多行字符串
msg = \'\'\' 天下只有两种人。比如一串葡萄到手,一种人挑最好的先吃,另一种人把最好的留到最后吃。 照例第一种人应该乐观,因为他每吃一颗都是吃剩的葡萄里最好的; 第二种人应该悲观,因为他每吃一颗都是吃剩的葡萄里最坏的。 不过事实却适得其反,缘故是第二种人还有希望,第一种人只有回忆。 \'\'\'
-
(3)使用
- 数字可以进行加减乘除等运算
- 字符串呢?
- 也可以,但只能进行"相加"和"相乘"运算。
>>> name = \'tony\'
>>> age = \'18\'
>>> name + age #相加其实就是简单的字符串拼接
\'tony18\'
>>> name * 5 #相乘就相当于将字符串相加了5次
\'tonytonytonytonytony\'
【3】列表(list)
(1)作用
-
用来存取多个相同属性的值,并且方便存取
-
如果我们需要用一个变量记录多个学生的姓名,用数字类型是无法实现,字符串类型则可以记录下来
-
比如
# 字符串类型 stu_names=’张三 李四 王五’ # 列表类型 names_list = [\'张三\', \'李四\', \'王五\']- 存的目的是为了取,此时若想取出第二个学生的姓名实现起来相当麻烦
- 而列表类型就是专门用来记录多个同种属性的值(比如同一个班级多个学生的姓名、同一个人的多个爱好等),并且存取都十分方便
(2)定义
>>> stu_names=[\'张三\',\'李四\',\'王五\']
(3)使用
- 1、列表类型是用索引来对应值,索引代表的是数据的位置,从0开始计数

>>> stu_names=[\'张三\',\'李四\',\'王五\']
>>> stu_names[0]
\'张三\'
>>> stu_names[1]
\'李四\'
>>> stu_names[2]
\'王五\'
-
2、列表可以嵌套,嵌套取值如下
l = [1, 1.1, \'kevin\', [666, 777, 888, \'tony\', [22,33, \'kevinNB\']]] # 1. kevinNB在大列表的第几个位置 l1 = l[3] # [666, 777, 888, \'tony\', [22, 33, \'kevinNB\']] # 2. kevinNB在大列表的第几个位置 l2 = l1[4] # [22, 33, \'kevinNB\'] # 3. kevinNB在大列表的第几个位置 l3 = l2[2] # kevinNB print(l3) # 整合 l4 = l[3][4][2] print(l4)
【4】字典(dict)
(1)作用
- 如果我们需要用一个变量记录多个值,但多个值是不同属性的
- 比如人的姓名、年龄、身高,用列表可以存,但列表是用索引对应值的,而索引不能明确地表示值的含义
- 这就用到字典类型,字典类型是用 key:value 形式来存储数据
- 其中key可以对value有描述性的功能,能够明确的描述详细信息
(2)定义
- 定义:大括号括起来,内部可以存放多个元素,元素与元素之间使用逗号隔开,是以K:V键值对的形式存储
- K:
- 是对V的描述性信息(一般情况是字符串)
- V:
- 真正的数据,其实相当于变量值,也是任意的数据类型
- K:
>>> person_info=\'name\':\'tony\',\'age\':18,\'height\':185.3
(3)使用
-
1、字典类型是用key来对应值,key可以对值有描述性的功能,通常为字符串类型
- 字典不能通过索引取值,只能通过字典的K取值
>>> person_info=\'name\':\'tony\',\'age\':18,\'height\':185.3 >>> person_info[\'name\'] \'tony\' >>> person_info[\'age\'] 18 >>> person_info[\'height\'] 185.3 -
2、字典可以嵌套,嵌套取值如下
info = \'username\':\'tony\', \'addr\': \'国家\':\'中国\', \'info\':[666, 999, \'编号\':466722, \'hobby\':[\'read\', \'study\', \'music\']] # 1. music在大字典里的位置 d1 = info[\'addr\'] # \'国家\': \'中国\', \'info\': [666, 999, \'编号\': 466722, \'hobby\': [\'read\', \'study\', \'music\']] # 2. music在小字典里的位置 d2 = d1[\'info\'] # [666, 999, \'编号\': 466722, \'hobby\': [\'read\', \'study\', \'music\']] # 3. music在列表里的位置 d3 = d2[2] # \'编号\': 466722, \'hobby\': [\'read\', \'study\', \'music\'] # 4. music在小字典里的位置 d4 = d3[\'hobby\'] # [\'read\', \'study\', \'music\'] # 5. music在列表里的位置 d5 = d4[2] # music print(d5) # 整合 d6 = info[\'addr\'][\'info\'][2][\'hobby\'][2] print(d6)
【5】布尔(bool)
(1)作用
- 用来记录真假的状态
- 判断是否正确
(2)定义
- 只有两种情况
- True
- 对 正确的 可行的...
- False
- 错误 不可行的
- True
>>> is_ok = True
>>> is_ok = False
- 在python中,什么是真,什么是假?
- 哪些是假的情况:
- 0,
- None,
- \'\',
- [],
- ...
- 其他都是真
- 哪些是假的情况:
(3)使用
-
布尔值的命名规范:结果可能是布尔值的情况,我们都采用 is 开头 命名
- is_right
- is_delete
-
通常用来当作判断的条件,我们将在if判断中用到它
-
在python中,所有的数据类型都可以转为布尔值
【6】元祖(tuple)
(1)作用
- 用来存取多个相同属性的值,并且方便存取
- 如果我们需要用一个变量记录多个学生的姓名,用数字类型是无法实现,字符串类型则可以记录下来
- 列表可以改变里面的值,但是元祖里面的值不能被改变
(2)定义
- 小括号括起来,内部可以存放多个元素,元素与元素之间使用逗号隔开,元素不能更改
t1 = (11, 22, 33, 44)
【7】集合(set)
(1)作用
- 集合(set)是一个无序的不重复元素序列。
(2)定义
- 可以使用大括号 或者 set() 函数创建集合
- 注意:创建一个空集合必须用 set() 而不是 ,因为 是用来创建一个空字典。
-
大括号括起来,内部可以存放多个元素,元素与元素之间逗号隔开,但是不是K:V键值对的形式
-
创建方式一
s = 11,22,33,44 -
创建方式二
set(value)
-
集合中的元素不能直接取出
【五】程序与用户交互
【1】程序与用户交互
(1)什么是与用户交互
- 用户交互就是人往计算机中input/输入数据,计算机print/输出结果
(2)为什么要与用户交互
-
为了让计算机能够像人一样与用户沟通交流
-
比如
- 过去我们去银行取钱,用户需要把帐号密码告诉柜员
- 而现在,柜员被ATM机取代
- ATM机就是一台计算机
- 所以用户同样需要将帐号密码告诉计算机
- 于是我们的程序中必须有相应的机制来控制计算机接收用户输入的内容
- 并且输出结果
(3)如何与用户交互
交互的本质就是输入、输出
(3.1)输入(input)
-
在python3中input功能会等待用户的输入
-
用户输入任何内容
-
input接受的所有数据类型都是
str类型# 输入input password = input(\'请输入你的密码:>>>\') print(password, type(password)) # input接受的所有数据类型都是str类型 # print(password == \'123\') # python中 == 比较的是数据值和数据类型 print(int(password) == 123) # python中 == 比较的是数据值和数据类型 print(password == str(123)) # python中 == 比较的是数据值和数据类型 -
然后赋值给等号左边的变量名
-
>>> username=input(\'请输入您的用户名:\')
请输入您的用户名:jack # username = "jack"
>>> password=input(\'请输入您的密码:\')
请输入您的密码:123 # password = "123"
-
1、在python2中
- 存在一个raw_input功能与python3中的input功能一模一样
-
2、在python2中
-
还存在一个input功能
-
需要用户输入一个明确的数据类型,输入什么类型就存成什么类型
>>> l=input(\'输入什么类型就存成什么类型: \') 输入什么类型就存成什么类型: [1,2,3] >>> type(l) <type \'list\'>
-
(3.2)输出(print)
>>> print(\'hello world\') # 只输出一个值
hello world
>>> print(\'first\',\'second\',\'third\') # 一次性输出多个值,值用逗号隔开
first second third
- 默认print功能有一个
end参数- 该参数的默认值为"\\n"(代表换行),可以将end参数的值改成任意其它字符
print("aaaa",end=\'\')
print("bbbb",end=\'&\')
print("cccc",end=\'@\')
#整体输出结果为:aaaabbbb&cccc@
(3.3)输出之格式化输出
-
[3.3.1] 什么是格式化输出
- 把一段字符串里面的某些内容替换掉之后再输出,就是格式化输出。
-
[3.3.2] 为什么要格式化输出
- 我们经常会输出具有某种固定格式的内容
- 比如:\'亲爱的xxx你好!你xxx月的话费是xxx,余额是xxx‘
- 我们需要做的就是将xxx替换为具体的内容。
- 我们经常会输出具有某种固定格式的内容
-
[3.3.3] 如何格式化输出
-
这就用到了占位符,如:
-
%s
-
可以接收任意类型的值
# %s称为占位符(掌握)可以为所有的数据类型占位 res = \'亲爱的%s你好!你%s月的话费是%s,余额是%s,我们需要做的就是将xxx替换为具体的内容。\' print(res % (\'kevin\', 99, 2, 99999999)) # 亲爱的kevin你好!你99月的话费是2,余额是99999999,我们需要做的就是将xxx替换为具体的内容。 print(res % (\'kevin1\', 991, 2, 100)) # 亲爱的kevin1你好!你991月的话费是2,余额是100,我们需要做的就是将xxx替换为具体的内容。 print(res % (\'kevin2\', 992, 2, 1199999)) # 亲爱的kevin2你好!你992月的话费是2,余额是1199999,我们需要做的就是将xxx替换为具体的内容。 print(res % (\'kevin3\', 993, 2, 22999999)) # 亲爱的kevin2你好!你992月的话费是2,余额是1199999,我们需要做的就是将xxx替换为具体的内容。 print(res % (\'kevin4\', 994, 2, 933999999)) # 亲爱的kevin4你好!你994月的话费是2,余额是933999999,我们需要做的就是将xxx替换为具体的内容。 res1 = \'my name is %s\' print(res1 % \'tony\') # my name is tony
-
-
%d
-
只能接收数字
# %d占位符(了解)只能给数字类型占位 # print("my name is %d" % \'kevin\') # TypeError: %d format: a number is required, not str print("金额:%08d" % 111) # 金额:00000111 print("金额:%08d" % 666666) # 金额:00666666 print("金额:%08d" % 99999999999) # 金额:99999999999
-
-
[3.3.4] 练习:接收用户输入,打印成指定格式
name = input(\'your name: \') age = input(\'your age: \') #用户输入18,会存成字符串18,无法传给%d print(\'My name is %s,my age is %s\' %(name,age)) -
[3.3.5] 练习:用户输入姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of Tony ----------- Name : Tony Age : 22 Sex : male Job : Teacher ------------- end -----------------
-
-
【六】基本运算符
参考网站(菜鸟教程):https://www.runoob.com/python/python-operators.html
【1】算数运算符
- python支持的算数运算符与数学上计算的符号使用是一致的
- 我们以x=9,y=2为例来依次介绍它们
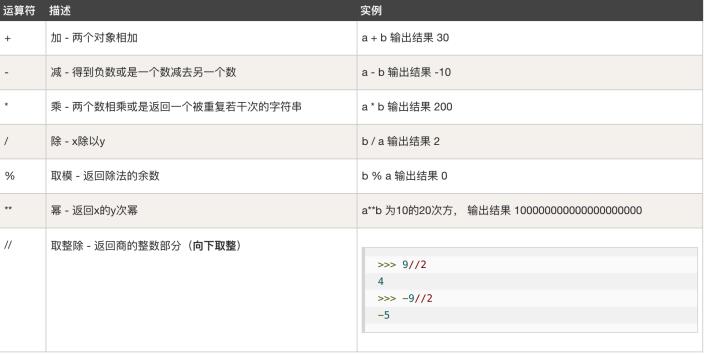
-
python中拼接字符串使用 +
s1 = \'hello\' s2 = \'world\' print(s1 + s2) # helloworld print(s1 * 10) # hellohellohellohellohellohellohellohellohellohello
【2】比较运算符
- 比较运算用来对两个值进行比较,返回的是布尔值True或False
- 我们以x=9,y=2为例来依次介绍它们
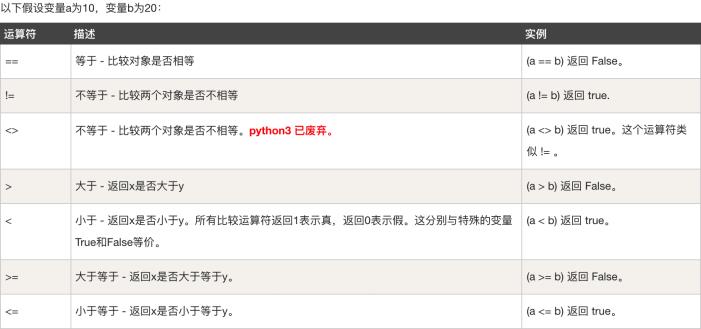
【3】赋值运算符
- python语法中除了有=号这种简单的赋值运算外
- 还支持增量赋值、链式赋值、交叉赋值、解压赋值
- 这些赋值运算符存在的意义都是为了让我们的代码看起来更加精简。
- 我们以x=9,y=2为例先来介绍一下增量赋值
(1)增量运算符

(2)链式赋值
- 如果我们想把同一个值同时赋值给多个变量名,可以这么做
>>> z=10
>>> y=z
>>> x=y
>>> x,y,z
(10, 10, 10)
- 链式赋值指的是可以用一行代码搞定这件事
>>> x=y=z=10
>>> x,y,z
(10, 10, 10)
(3)交叉赋值
- 我们定义两个变量m与n
>>> m=10
>>> n=20
- 如果我们想将m与n的值交换过来,可以这么做
>>> temp=m
>>> m=n
>>> n=temp
>>> m,n
(20, 10)
- 交叉赋值指的是一行代码可以搞定这件事
>>> m=10
>>> n=20
>>> m,n=n,m # 交叉赋值
>>> m,n
(20, 10)
(4)解压赋值
- 如果我们想把列表中的多个值取出来依次赋值给多个变量名
- 可以这么做
>>> nums=[11,22,33,44,55]
>>>
>>> a=nums[0]
>>> b=nums[1]
>>> c=nums[2]
>>> d=nums[3]
>>> e=nums[4]
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
-
左右两边的多个值进行赋值时
- 个数必须一致
names_list = [\'kevin\', \'tony\', \'tank\', \'tom\'] # ll1, ll2, ll3, ll4 = names_list # ll1, ll2, ll3, ll4 = [\'kevin\', \'tony\', \'tank\', \'tom\'] -
解压赋值指的是一行代码可以搞定这件事
>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
注意,上述解压赋值,等号左边的变量名个数必须与右面包含值的个数相同,否则会报错
-
1、变量名少了
>>> a,b=nums Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: too many values to unpack (expected 2) -
2、变量名多了
>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名 >>> a,b,c,d,e,f=nums Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: not enough values to unpack (expected 6, got 5) -
但如果我们只想取头尾的几个值,可以用*_匹配
>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名 >>> a,b,*_=nums >>> a,b (11, 22) -
可以用
*代替一个集合,将一堆数据取出来ll1, *a, ll3, ll4 = [\'kevin\', \'tony\', \'tank\',\'a\',\'b\', \'tom\'] print(ll1, a, ll4) # kevin [\'tony\', \'tank\', \'a\'] tom
ps:字符串、字典、元组、集合类型都支持解压赋值
(5)逻辑运算符
- 逻辑运算符用于连接多个条件
- 进行关联判断
- 会返回布尔值True或False

(5.1)连续多个 and
- 可以用and连接多个条件
- 会按照从左到右的顺序依次判断
- 一旦某一个条件为False
- 则无需再往右判断
- 可以立即判定最终结果就为False
- 只有在所有条件的结果都为True的情况下
- 最终结果才为True。
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # 判断完第二个条件,就立即结束,得的最终结果为False
False
(5.2)连续多个 or
- 可以用or连接多个条件
- 会按照从左到右的顺序依次判断
- 一旦某一个条件为True
- 则无需再往右判断
- 可以立即判定最终结果就为True
- 只有在所有条件的结果都为False的情况下
- 最终结果才为False
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # 判断完第一个条件,就立即结束,得的最终结果为True
True
(5.3)优先级 not>and>or
-
1、三者的优先级关系:
not>and>or- 同一优先级默认从左往右计算。
>>> 3>4 and 4>3 or 1==3 and \'x\' == \'x\' or 3 >3 False -
2、最好使用括号来区别优先级,其实意义与上面的一样
- (1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割
- (2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可
- (3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算
>>> (3>4 and 4>3) or (1==3 and \'x\' == \'x\') or 3 >3 False -
3、短路运算:
- 逻辑运算的结果一旦可以确定
- 那么就以当前处计算到的值作为最终结果返回
>>> 10 and 0 or \'\' and 0 or \'abc\' or \'egon\' == \'dsb\' and 333 or 10 > 4 我们用括号来明确一下优先级 >>> (10 and 0) or (\'\' and 0) or \'abc\' or (\'egon\' == \'dsb\' and 333) or 10 > 4 短路: 0 \'\' \'abc\' 假 假 真 返回: \'abc\' -
4、短路运算面试题:
>>> 1 or 3 1 >>> 1 and 3 3 >>> 0 and 2 and 1 0 >>> 0 and 2 or 1 1 >>> 0 and 2 or 1 or 4 1 >>> 0 or False and 1 False
(6)成员运算符

注意:虽然下述两种判断可以达到相同的效果,但我们推荐使用第二种格式,因为not in语义更加明确
>>> not \'lili\' in [\'jack\',\'tom\',\'robin\']
True
>>> \'lili\' not in [\'jack\',\'tom\',\'robin\']
True
(7)身份运算符

-
需要强调的是:
==双等号比较的是value是否相等is比较的是id是否相等
-
- id相同,内存地址必定相同,意味着type和value必定相同
- value相同type肯定相同,但id可能不同,如下
>>> x=\'Info Tony:18\' >>> y=\'Info Tony:18\' >>> id(x),id(y) # x与y的id不同,但是二者的值相同 (4327422640, 4327422256) >>> x == y # 等号比较的是value True >>> type(x),type(y) # 值相同type肯定相同 (<class \'str\'>, <class \'str\'>) >>> x is y # is比较的是id,x与y的值相等但id可以不同 False
python_day2基本数据类型
运算符
1、算数运算:

%:取模,可以用来算奇偶数
2、比较运算:

!=:不等于;<>也是,python3报错
3、赋值运算:

4、逻辑运算:

5、成员运算:

6、身份运算:
is: type(a) is str is not:type(a) is not list |
基本数据类型
1、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2、布尔值
真或假 || 1 或 0
3、字符串
字符串常用功能:
移除空白:str = " This is a string \n"
str.strip() #去除str前后的空格和换行,str == "This is a string"
str.strip(‘\n‘) #仅去掉换行,str == " This is a string "
分割:str = "alex,jack,rain"
str2 = str.split(‘,‘) #被拆分成一list:[‘alex‘, ‘jack‘, ‘rain‘]
"|".join(str2) #又被合成一string:‘alex|jack|rain‘
长度:len(str)
索引
"Hello,{name} is {what}".format(name=‘Q‘,what=‘IQ‘)
"Hello,{0} is {1}".formar(‘Q‘,‘IQ‘)
切片:跟list列表一样
判断
str.isdigit()#数字
str.isalnum()#不包含特殊字符
str.endswith(‘sth‘)
str.startswith(‘sth‘)
str.upper() #变大写
str.lower() #变小写
4、列表
创建列表:(其它语言叫数组,可以存储各种元素,包括变量,是个前闭后开区间)
name_list = [‘alex‘,‘seven‘,‘eric‘] 或 name_list = list([‘alex‘,‘seven‘,‘eric‘]) |
基本操作:
索引
name_list.insert(index,"sth") #在index位置插入sth,一次只能插一个
切片
name_list[::-1] #倒序排列
列表反转
name_list.reverse() #跟倒序一样,只是直接保存在了原列表
追加
name_list.append("last") #在列表末尾追加last
删除
name_list.remove("sth") #删除列表的sth
name_list.pop(index) #默认弹出最后一个,写几就弹几呗
del 是python的一个内置函数,可以删除任何东西
del name_list[1:2] #删除列表第二个数
del name_list #删除整个列表
长度
len(name_list)
排序
name_list.sort() #Python3不支持数字与字符串混排,单独可以,直接保存在name_list中
列表扩展
name = [1,2,3]
name_list.extend(name) #将name追加到name_list中[‘alex‘,‘seven‘,‘eric‘,1,2,3]
循环
in方法:name = [9,3,9,12,3,3,4,9,42,46,9,99,9]
| if 9 in name: num_of = name.count(9) #计算9的个数 position_of = name.index(9) #只会输出第一个9的位置索引 print(name_of,position_of) #下面把9的内容都修改成110 for i in range(name.count(9)): name[name.index(9)] = 110 |
列表的copy模块
list.copy()
>>>name = [1,2,3,[4,5,6]] >>>name1 = name.copy() >>>id(name),id(name1) (2129574779336, 2129574779144) #俩内存地址是不同的 >>> name[3][0] = 444 #修改第二层列表,二者都会变 >>> name [1, 2, 3, [444, 5, 6]] >>> name1 [1, 2, 3, [444, 5, 6]] >>> name[0] = 111 #修改第一层列表,则不会互相影响 >>> name [111, 2, 3, [444, 5, 6]] >>> name1 [1, 2, 3, [444, 5, 6]] |
python默认只copy第一层列表,其它层列表只是指向其内存地址,so第一层列表是独立的,其它层列表都是共享的!!!
python有一个copy标准库,copy.copy()的效果跟list.copy()一样,然而copy.deepcopy()就是完全克隆过来!!两列表完全独立,不存在数据共享。
5、元祖(不可变列表)
一般做统计使用
6、字典(无序且key值唯一)
sth = { 110:{‘name‘:‘zhao‘,‘age‘:‘12‘,‘tel‘:110}, 111:{‘name‘:‘qian‘,‘age‘:‘15‘,‘tel‘:111}, 112:{‘name‘:‘sun‘,‘age‘:‘11‘,‘tel‘:112} } |
| 删除值: 用全局del或者sth.pop()均可 del sth[110][‘name‘] sth[110].pop(‘tel‘) 获取value值: 如果key值存在,则以下两种获取方法均可; print(sth.get(110)) print(sth[110]) 如果key值不存在,则sth.get()会返回None值,而sth[key]则会报错!! 更新字典: sth.update(dict2) #用dict2的值来更新sth的值,如果key不存在则添加,存在则替换value值 sth.items() #需要先把字典转换成列表,耗时。。不用。。 sth.keys() #获取所有key sth.values() #获取所有value 判断key是否在字典中: sth.has_key(110)#only in python 2.x 110 in sth #python 3.x print(sth.setdefault(113,"something")) #取一个key,如果存在则打印其value值,不存在则新增k,v值(value不写,默认为None) print(dict.fromkeys([1,2,3],‘allme‘)) #key不同,value值相同;据说这里面有一个坑,但是alex不说。。 print(sth.popitem()) #随机删除,不要用 |
| 循环字典: for k,v in sth.items(): print(k,v) # 效率低,有一个dict to list的过程 ==========================效率分割线========================= for key in sth: # 效率高呀 print(key,sth[key]) |
其他
1、enumrate(枚举)
为可迭代的对象添加序号
li = [11,22,33]for k,v in enumerate(li, 1): #后面那个1,是指序号从1开始计数 print(k,v) |
2、字体颜色
red_color = ‘\033[31;1m"sth_else"\033[0m‘#字体颜色是红色 python中的单双引号没有区别 |
以上是关于day04 基本数据类型与基本运算符的主要内容,如果未能解决你的问题,请参考以下文章