Hadoop入门
Posted lionet-kk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop入门相关的知识,希望对你有一定的参考价值。
2.Hadoop入门
1.分布式和集群
分布式:多台服务器相互配合完成一件工作(工作内部,各台服务器所完成的子任务不同)
集群:多台服务器联合起来独立完成流水线式工作
举例:洗衣店洗衣服如果分为四步:放入洗衣机、晾晒衣服、熨衣服、送给客户,每步都分别由不同种类的员工来做,那么这四个员工协同完成洗衣服的工作,这四个员工可以称为一个分布式。这家洗衣店多个分布式就可以看做是一个集群。
2.Hadoop框架
Hadoop介绍
Hadoop:是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
起源:Hadoop是Apache Lucene创始人 Doug Cutting 创建的,最早起源一个Nutch项目。
Hadoop框架内容
狭义上来说:Hadoop指Apache这款开源框架,它的核心组件有:HDFS,MapReduce,YANR
广义上来说:Hadoop通常是指一个更广泛的概念——Hadoop生态圈
版本: 分为开源社区版和商业版。
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差。
商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,如: cloudera的CDH等。
Hadoop版本更新
1.x版本系列: hadoop的第二代开源版本,该版本基本已被淘汰 hadoop组成: HDFS(存储)和MapReduce(计算和资源调度)
2.x版本系列: 架构产生重大变化,引入了Yarn平台等许多新特性 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
3.x版本系列: 因为2版本的jdk1.7不更新,基于jdk1.8升级产生3版本 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
Hadoop架构详解
Hadoop架构主要由HDFS、MapReduce、YARN这三个组件组成
HDFS:分布式文件系统,主要用于解决海量数据存储问题
元数据:描述核心数据的数据
NameNode:集群的主节点,管理集群中各种数据
DataNode:集群的从节点,用于存储集群中各种数据
SecondaryNameNode:主要能用于辅助NameNode进行文件块元数据存储
MapReduce:分布式运算编程框架,解决海量数据计算
计算模式:分而治之,map负责分解,reduce负责合并,其需要的数据以及运算的结果需要用HDFS进行存储,其运行需要YARN进行资源调度以及分配
MR程序:使用Java/Python编写MR程序运行,太复杂了,则使用hive编写sql,底层自动转为Java程序运行,学习成本低
3.启动Hadoop集群
一键启动
使用CRT连接好三台虚机节点,在node1节点下操作
启动集群命令:start-all.sh
关闭集群命令:stop-all.sh
查看Java进程
node1:
[root@node1 ~]# jps
2273 DataNode
2849 NodeManager
3217 Jps
2691 ResourceManager
2122 NameNode
node2:
[root@node2 ~]# jps
2134 Jps
1975 NodeManager
1772 DataNode
1855 SecondaryNameNode
node3:
[root@node3 ~]# jps
1765 DataNode
2055 Jps
1884 NodeManager
启动历史服务
JobHistory用来记录已经完成的mapreduce运行日志,不是必须启动的
[root@node1 ~]# mapred --daemon start historyserver
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]# jps
2273 DataNode
2849 NodeManager
3313 JobHistoryServer
2691 ResourceManager
2122 NameNode
3371 Jps
Web页面打开服务
在windows下,如果没有配置映射, 浏览器中不识别node1,node2,node3同时hdfs不能上传文件 。
如何解决? 可以进入 **C:\\Windows\\System32\\drivers\\etc** 目录打开hosts文件,设置域名映射
复制以下内容添加到hosts文件末尾
#注意:要替换为自己node节点的IP地址
192.168.88.161 node1.itcast.cn node1
192.168.88.162 node2.itcast.cn node2
192.168.88.163 node3.itcast.cn node3
配置完成后,便可以在浏览器中输入以下域名访问服务
访问hdfs文件系统的url: http://node1:9870
访问yarn资源调度的url: http://node1:8088
访问历史mr计算日志: http://node1:19888
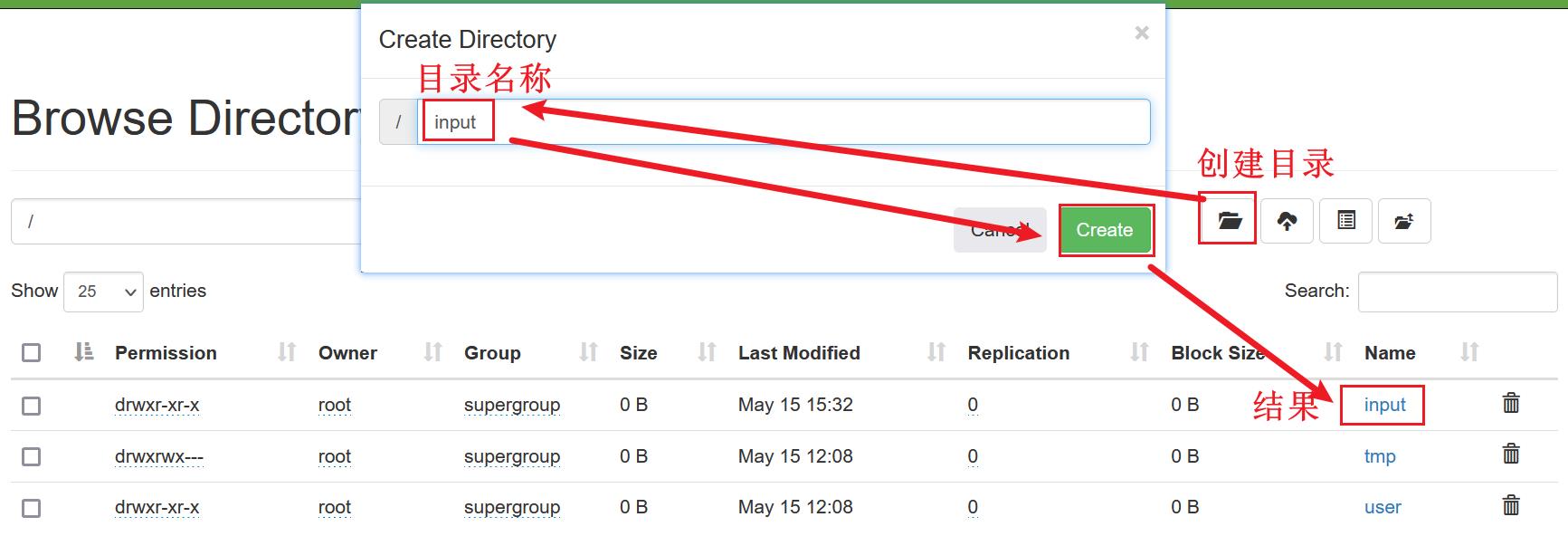
HDFS上传文件
4.官方示例
根据官方提供的示例,我们能更好的了解和认识MapReduce的计算模式,快速上手体验MapReduce,在Hadoop的安装包中,官方提供了MapReduce程序的示例examples,该示例是使用java语言编写的,被打包成为了一个jar文件。
官方示例jar路径: /export/server/hadoop-3.3.0/share/hadoop/mapreduce
圆周率练习
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi x y
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数x:用于指定map阶段运行的任务次数,并发度,举例:x=10
第三个参数y:用于指定每个map任务取样的个数,举例: x=5
示例
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
您在 /var/spool/mail/root 中有新邮件
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
...
Job Finished in 32.579 seconds
Estimated value of Pi is 3.16000000000000000000
在http://node1:8088下可以查看此进程的各种信息,包括开始时间、运行时间、状态、运行容器的个数、已分配的资源等等
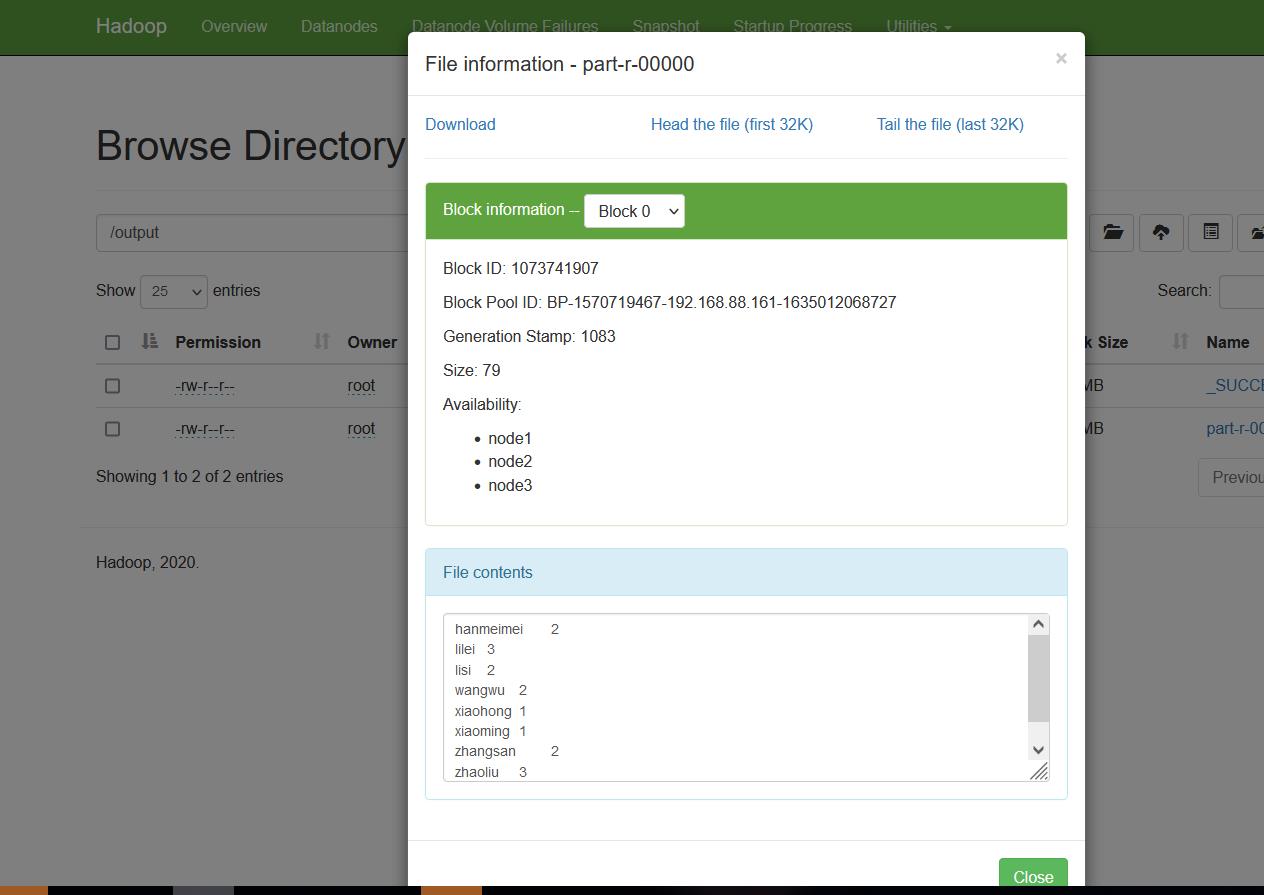
词频统计
需求:WordCount算是大数据统计分析领域的经典需求了,相当于编程语言的HelloWorld。统计文本数据中,相同单词出现的总次数。用SQL的角度来理解的话,相当于根据单词进行group by分组,相同的单词分为一组,然后每个组内进行count聚合统计。已知hdfs中word.txt文件内容如下,计算每个单词出现的次数
步骤:
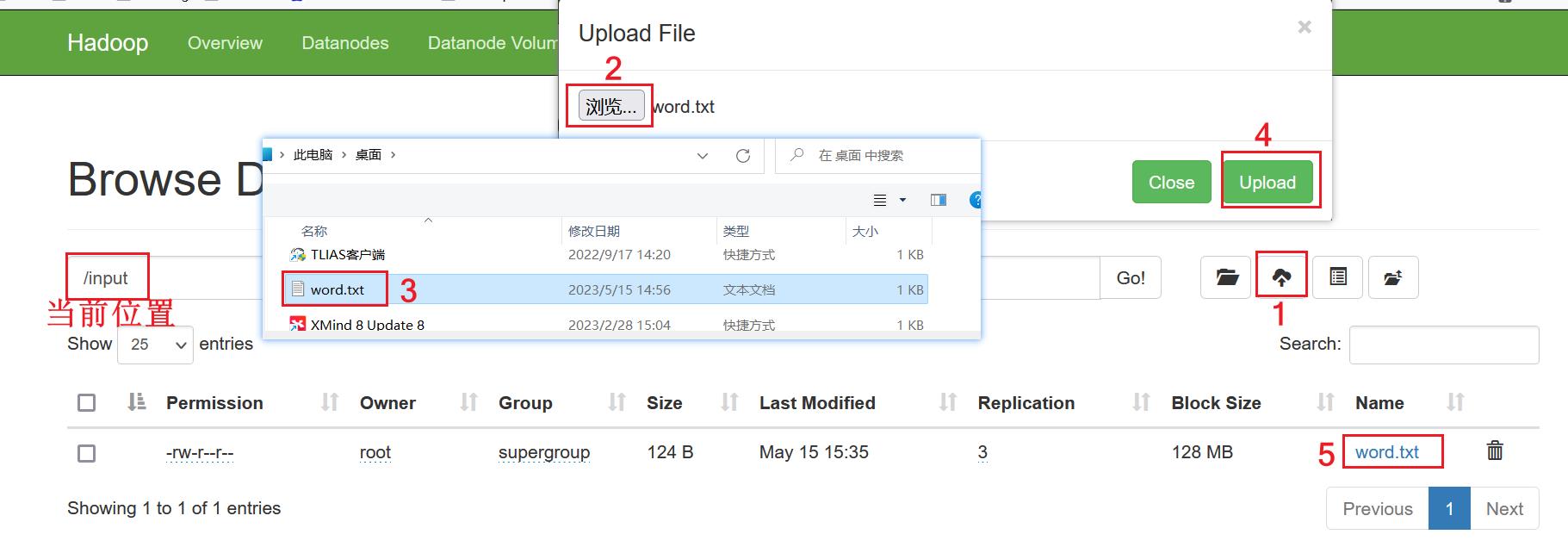
1.HDFS根目录中创建input目录,存储word.txt文件
可以在window本地提前创建word.txt文件存储,内容如下:
zhangsan lisi wangwu zhangsan
zhaoliu lisi wangwu zhaoliu
xiaohong xiaoming hanmeimei lilei
zhaoliu lilei hanmeimei lilei
之后通过HDFS上传文件,具体如下图
2.在shell命令行中执行如下命令
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
3.去HDFS中查看是否生成output目录
注意: output输出目录,在执行第2步命令后会自动生成,如果提前手动创建或者已经存在,就会报以下错误:
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://node1.itcast.cn:8020/output already exists
4.进入output目录查看part-r-00000文件,结果如下:
5.Hadoop-HDFS
特点
HDFS文件系统可以存储海量数据,但是时效性较差
HDFS文件系统具有硬件故障检测和自动快速恢复功能
HDFS文件系统为数据存储提供强大的扩展能力
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改
HDFS可以在普通廉价的机器上运行
架构
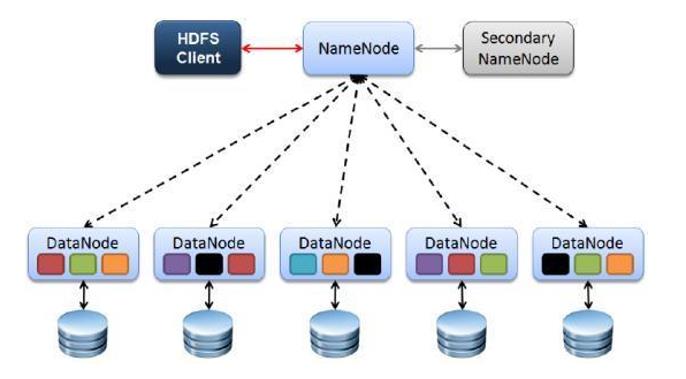
1、Client
发请求就是客户端。
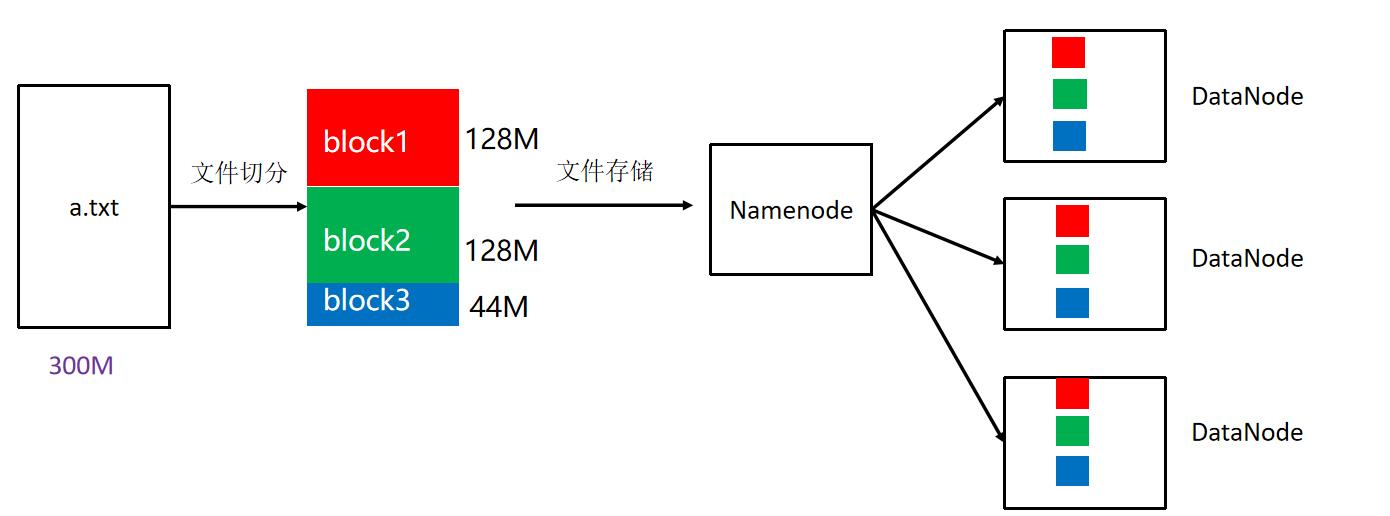
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode
就是 master,它是一个主管、管理者。
处理客户端读写请求。
管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息….)。
配置3副本备份策略。
3、DataNode
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块。
执行数据块的读/写操作。
定时向namenode汇报block信息。
4、Secondary NameNode
并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。
在紧急情况下,可辅助恢复 NameNode。
副本
block块: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。类似于分页存储管理系统。
block 块大小默认: 128M(134217728字节)
注意: 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
副本系数默认: 3个
hdfs默认文件:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
6.shell命令
hdfs下shell命令类似于Linux的shell命令,如ls,mkdir,rm等,对hdfs文件系统进行相关操作
命令格式1:hadoop fs -命令 参数
命令格式2:hdfs dfs -命令 参数
注意:hdfs的家目录默认为:/user/root 如果进行命令操作时,没有加根目录/,则默认访问的是此家目录/user/root
查看目录下的内容:hdfs dfs -ls 目录的绝对路径
创建目录:hdfs dfs -mkdir 目录的绝对路径
创建文件:hdfs dfs -touch 目录的绝对路径
移动文件或目录:hfds dfs -mv 要移动的绝对路径 目标位置的绝对路径
复制文件或目录:hdfs dfs -cp 要复制的绝对路径 目标位置的绝对路径
删除文件或目录:hdfs dfs -rm [-r] 要删除的绝对路径
查看文件的内容:hdfs dfs -cat 要查看的文件的绝对路径
查看其他shell命令:hdfs dfs --help
linux本地上传文件到hdfs中:hdfs dfs -put 要传的文件或目录的绝对路径 hdfs目标位置绝对路径
hdfs 中下载文件到Linux中:hdfs dfs -get hdfs要下载的文件或目录的绝对路径 Linux本地中目标位置绝对路径
7.Hive环境配置
配置
#打开配置文件
[root@node1 /]# vim /etc/profile
#在文件末尾添加如下内容:
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
#使文件生效
[root@node1 /]# source /etc/profile
#配置好可以拍个快照
启动Hive服务
知识点
后台启动metastore服务: nohup hive --service metastore &
后台启动hiveserver2服务: nohup hive --service hiveserver2 &
查看metastore和hiveserver2进程是否启动: jps 注意: 服务名都叫RunJar,可以通过进程编号区分
服务启动需要一定时间可以使用lsof查看: lsof -i:10000 注意: 如果无内容继续等待,如果有内容代表启动成功
演示
[root@node1 /]# nohup hive --service metastore &
[1] 5141
[root@node1 /]# nohup: 忽略输入并把输出追加到"nohup.out"
enter
[root@node1 /]# nohup hive --service hiveserver2 &
[2] 5286
[root@node1 /]# nohup: 忽略输入并把输出追加到"nohup.out"
enter
[root@node1 /]# jps
2273 DataNode
2849 NodeManager
3313 JobHistoryServer
5425 Jps
2691 ResourceManager
5141 RunJar
5286 RunJar
2122 NameNode
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 5286 root 522u IPv6 93284 0t0 TCP *:ndmp (LISTEN)
连接Hive服务
一代客户端连接命令: hive 注意: hive直接连接成功,直接可以编写sql语句
二代客户端连接命令: beeline 注意: 以后建议用二代客户端
二代客户端远程连接命令: !connect jdbc:hive2://node1:10000
注意: hive用户名是root 密码为空
二代客户端示例:
[root@node1 /]# beeline
# 先输入!connect jdbc:hive2://node1:10000连接
beeline> !connect jdbc:hive2://node1:10000
# 再输入用户名root,密码不用输入直接回车即可
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
# 输入show databases;查看表
0: jdbc:hive2://node1:10000> show databases;
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.2 seconds)
之后就可以使用sql语句进行愉快的玩耍了!
大数据hadoop入门之hadoop家族详解
大数据hadoop入门之hadoop家族详解
大数据这个词也许几年前你听着还会觉得陌生,但我相信你现在听到hadoop这个词的时候你应该都会觉得“熟悉”!越来越发现身边从事hadoop开发或者是正在学习hadoop的人变多了。作为一个hadoop入门级的新手,你会觉得哪些地方很难呢?运行环境的搭建恐怕就已经足够让新手头疼。如果每一个发行版hadoop都可以做到像大快DKHadoop那样把各种环境搭建集成到一起,一次安装搞定所有,那对于新手来说将是件多么美妙的事情!
闲话扯得稍微多了点,回归整体。这篇准备给大家hadoop新入门的朋友分享一些hadoop的基础知识——hadoop家族产品。通过对hadoop家族产品的认识,进一步帮助大家学习好hadoop!同时,也欢迎大家提出宝贵意见!
一、Hadoop定义
Hadoop是一个大家族,是一个开源的生态系统,是一个分布式运行系统,是基于Java编程语言的架构。不过它最高明的技术还是HDFS和MapReduce,使得它可以分布式处理海量数据。
二、Hadoop产品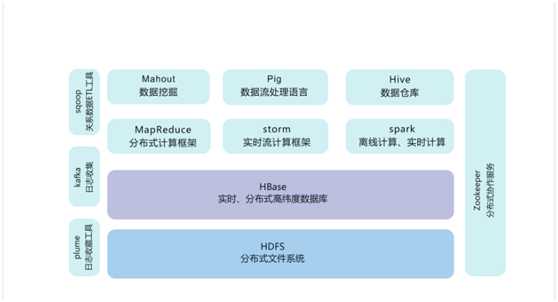
HDFS(分布式文件系统):
它与现存的文件系统不同的特性有很多,比如高度容错(即使中途出错,也能继续运行),支持多媒体数据和流媒体数据访问,高效率访问大型数据集合,数据保持严谨一致,部署成本降低,部署效率提高等,如图是HDFS的基础架构。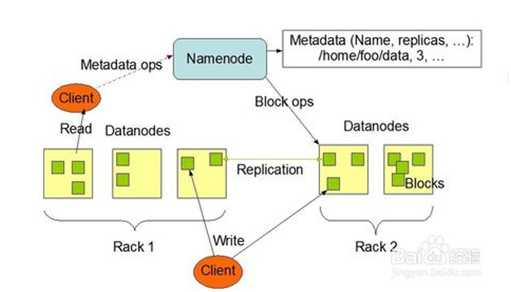
MapReduce/Spark/Storm(并行计算架构):
1、数据处理方式来说分离线计算和在线计算:
角色 描述
MapReduce MapReduce常用于离线的复杂的大数据计算
Storm Storm用于在线的实时的大数据计算,Storm的实时主要是一条一条数据处理;
Spark 可以用于离线的也可用于在线的实时的大数据计算,Spark的实时主要是处理一个个时间区域的数据,所以说Spark比较灵活。
2、数据存储位置来说分磁盘计算和内存计算:
角色 描述
MapReduce 数据存在磁盘中
Spark和Strom 数据存在内存中
Pig/Hive(Hadoop编程):
角色 描述
Pig 是一种高级编程语言,在处理半结构化数据上拥有非常高的性能,可以帮助我们缩短开发周期。
Hive 是数据分析查询工具,尤其在使用类SQL查询分析时显示出极高的性能。可以在分分钟完成ETL要一晚上才能完成的事情,这就是优势,占了先机!
HBase/Sqoop/Flume(数据导入与导出):
角色 描述
HBase 是运行在HDFS架构上的列存储数据库,并且已经与Pig/Hive很好地集成。通过Java API可以近无缝地使用HBase。
Sqoop 设计的目的是方便从传统数据库导入数据到Hadoop数据集合(HDFS/Hive)。
Flume 设计的目的是便捷地从日志文件系统直接把数据导入到Hadoop数据集合(HDFS)中。
以上这些数据转移工具都极大地方便了使用的人,提高了工作效率,把精力专注在业务分析上。
ZooKeeper/Oozie(系统管理架构):
角色 描述
ZooKeeper 是一个系统管理协调架构,用于管理分布式架构的基本配置。它提供了很多接口,使得配置管理任务简单化。
Oozie Oozie服务是用于管理工作流。用于调度不同工作流,使得每个工作都有始有终。这些架构帮助我们轻量化地管理大数据分布式计算架构。
Ambari/Whirr(系统部署管理):
角色 描述
Ambari 帮助相关人员快捷地部署搭建整个大数据分析架构,并且实时监控系统的运行状况。
Whirr Whirr的主要作用是帮助快速地进行云计算开发。
Mahout(机器学习):
Mahout旨在帮助我们快速地完成高智商的系统。其中已经实现了部分机器学习的逻辑。这个架构可以让我们快速地集成更多机器学习的智能。
以上是关于Hadoop入门的主要内容,如果未能解决你的问题,请参考以下文章