Python:解析PDF文本及表格——pdfminertabulapdfplumber 的用法及对比
Posted 丹枫无迹的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python:解析PDF文本及表格——pdfminertabulapdfplumber 的用法及对比相关的知识,希望对你有一定的参考价值。
pdf 是个异常坑爹的东西,有很多处理 pdf 的库,但是没有完美的。
一、pdfminer3k
pdfminer3k 是 pdfminer 的 python3 版本,主要用于读取 pdf 中的文本。
网上有很多 pdfminer3k 的代码示例,看过以后,只想吐槽一下,太复杂了,有违 python 的简洁。
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBox
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
path = "test.pdf"
# 用文件对象来创建一个pdf文档分析器
praser = PDFParser(open(path, \'rb\'))
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages():
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象,里面存放着这个 page 解析出的各种对象
# 包括 LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等
for x in layout:
if isinstance(x, LTTextBox):
print(x.get_text().strip())
pdfminer 对于表格的处理非常的不友好,能提取出文字,但是没有格式:
pdf表格截图:
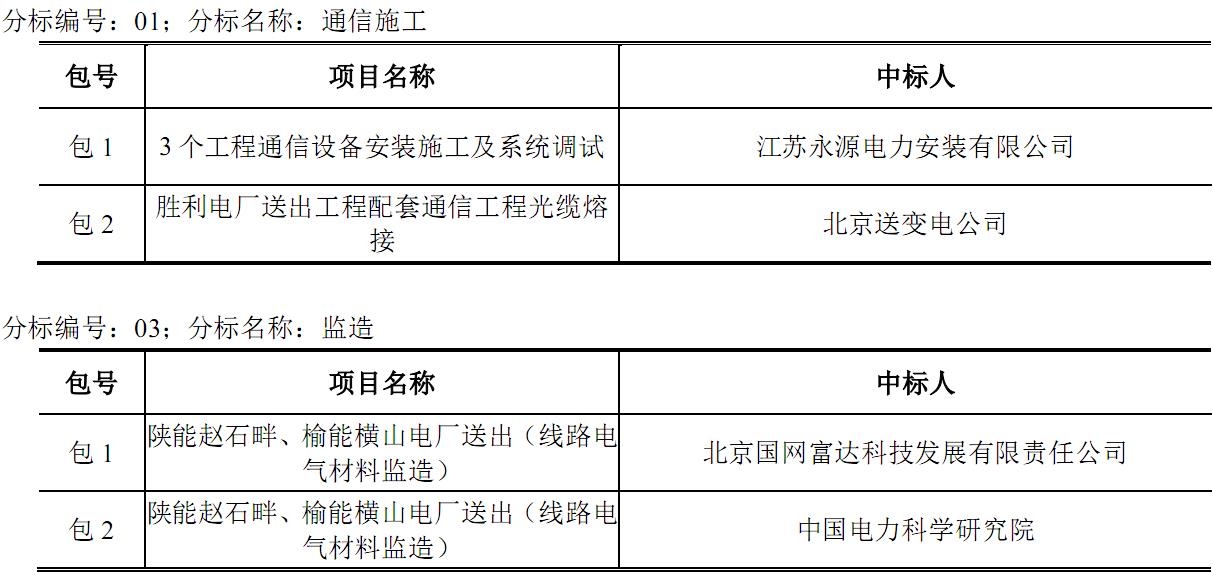
代码运行结果:

想把这个结果还原成表格可不容易,加的规则太多必然导致通用性的下降。
二、tabula-py
tabula 是专门用来提取PDF表格数据的,同时支持PDF导出为CSV、Excel格式,但是这工具是用 java 写的,依赖 java7/8。tabula-py 就是对它做了一层 python 的封装,所以也依赖 java7/8。
代码很简单:
import tabula
path = \'test.pdf\'
df = tabula.read_pdf(path, encoding=\'gbk\', pages=\'all\')
for indexs in df.index:
print(df.loc[indexs].values)
# tabula.convert_into(path, os.path.splitext(path)[0]+\'.csv\', pages=\'all\')
虽然号称是专业处理 pdf 中的表格的,但实际效果也不咋地。还是 pdfminer 中使用的 pdf,运行结果如下:

这结果真的很尴尬啊,表头识别就错了,还有 pdf 中有两张表,我没发现怎么区分表。
三、pdfplumber
pdfplumber 是按页来处理 pdf 的,可以获得页面的所有文字,并且提供的单独的方法用于提取表格。
import pdfplumber
path = \'test.pdf\'
pdf = pdfplumber.open(path)
for page in pdf.pages:
# 获取当前页面的全部文本信息,包括表格中的文字
# print(page.extract_text())
for table in page.extract_tables():
# print(table)
for row in table:
print(row)
print(\'---------- 分割线 ----------\')
pdf.close()
得到的 table 是个 string 类型的二维数组,这里为了跟 tabula 比较,按行输出显示。

可以看到,跟 tabula 相比,首先是可以区分表格,其次,准确率也提高了很多,表头的识别完全正确。对于表格中有换行的,识别还不是很正确,但至少列的划分没问题,所以还是能处理的。
import pdfplumber
import re
path = \'test1.pdf\'
pdf = pdfplumber.open(path)
for page in pdf.pages:
print(page.extract_text())
for pdf_table in page.extract_tables():
table = []
cells = []
for row in pdf_table:
if not any(row):
# 如果一行全为空,则视为一条记录结束
if any(cells):
table.append(cells)
cells = []
elif all(row):
# 如果一行全不为空,则本条为新行,上一条结束
if any(cells):
table.append(cells)
cells = []
table.append(row)
else:
if len(cells) == 0:
cells = row
else:
for i in range(len(row)):
if row[i] is not None:
cells[i] = row[i] if cells[i] is None else cells[i] + row[i]
for row in table:
print([re.sub(\'\\s+\', \'\', cell) if cell is not None else None for cell in row])
print(\'---------- 分割线 ----------\')
pdf.close()
经过处理后,运行得到结果:

这结果已经完全正确了,而用 tabula,即便是经过处理也是无法得到这样的结果的。当然对于不同的 pdf,可能需要不同的处理,实际情况还是要自己分析。
pdfplumber 也有处理不准确的时候,主要表现在缺列:
我找了另一个 pdf,表格部分截图如下:
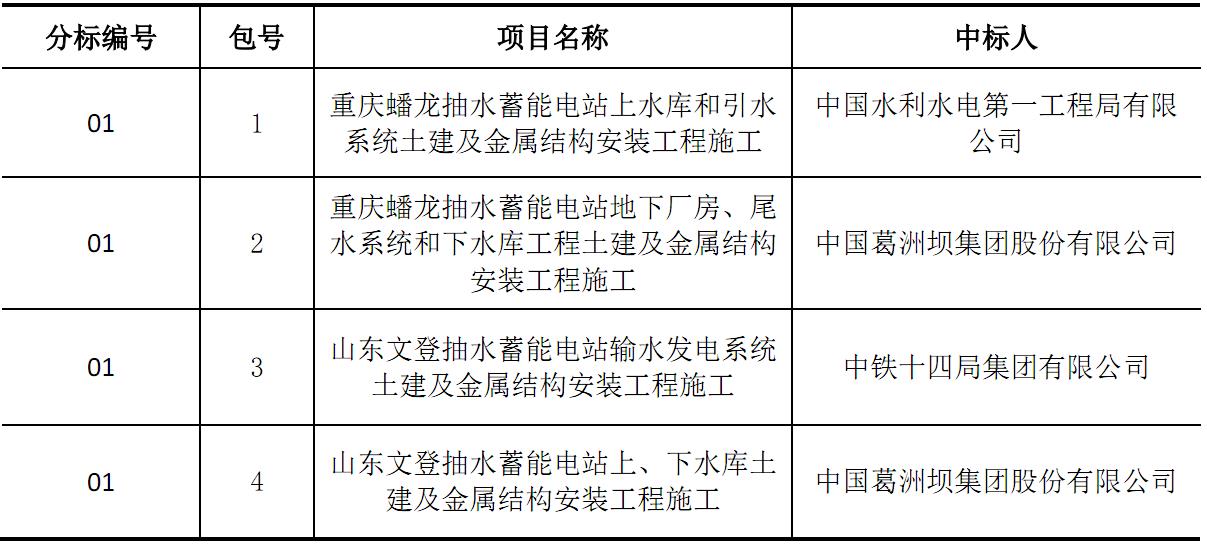
解析结果如下:

4列变成了两列,另外,如果表格有合并单元格的情况,也会有这种问题,我挑这个表格展示是因为比较特殊,没有合并单元格也缺列了。这应该跟 pdf 生成的时候有关。
但其实数据是获取完整的,并没有丢,只是被认为是非表格了。输出 page.extract_text() 如下:

然后,我又用 tabula 试了下,结果如下:

列是齐了,但是,表头呢???
pdfplumber 还提供了图形Debug功能,可以获得PDF页面的截图,并且用方框框起识别到的文字或表格,帮助判断PDF的识别情况,并且进行配置的调整。要使用这个功能,还需要安装ImageMagick。因为没有用到,所以暂时没有去细究。
四、后记
我们在做爬虫的时候,难免会遇到 pdf 需要解析,主要还是针对文本和表格的数据提取。而 python 处理 pdf 的库实在是太多太多了,比如还有 pypdf2,网上资料也比较多,但是我试了,读出来是乱码,没有仔细的读源码所以这个问题也没有解决。
而我对比较常用的3个库比较后觉得,还是 pdfplumber 比较好用,对表格的支持最好。
相关博文推荐:
Python:读取 .doc、.docx 两种 Word 文件简述及“Word 未能引发事件”错误
以上是关于Python:解析PDF文本及表格——pdfminertabulapdfplumber 的用法及对比的主要内容,如果未能解决你的问题,请参考以下文章