raid5需要几块硬盘
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了raid5需要几块硬盘相关的知识,希望对你有一定的参考价值。
参考技术A一块。
Raid5磁阵列至少使用3块硬盘(也可以更多),因为当有数据写入硬盘的时候,按照1块硬盘的方式就是直接写入这块硬盘的磁道,如果是RAID5的话这次数据写入会根据算法分成3部分,然后写入这3块硬盘,写入的同时还会在这3块硬盘上写入校验信息,当读取写入的数据的时候会分别从3块硬盘上读取数据内容,再通过检验信息进行校验。
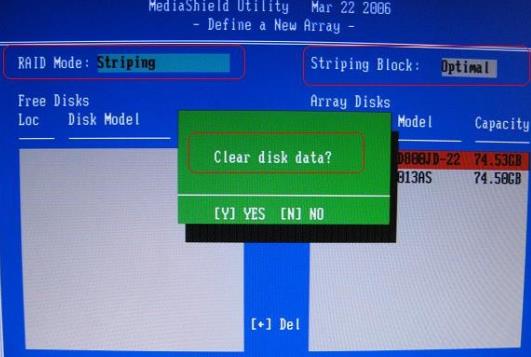
注意事项
注意Clear Configuration选项,删除RAID信息后,会将原来在RAID中的储存的所有信息一并删除。
一般做RAID5即可,RAID5有数据冗余,如果坏只一块硬盘,更换损坏硬盘即可,RAID5可以经过其他的硬盘的冗余数据将损坏硬盘的数据修复。
正确配置以上信息后就可以看到这个界面,这里有一个0%的读条,等待到100%后,点击HOME键。
4.GlusterFS 常见故障处理
一般硬盘也要备用几块,因为随着发展,可能这些型号的硬盘不好买到了,一般的事故不会在开始一两年出,在硬件老化的时候出故障的频率高。
4.1 硬盘故障
如果底层做了 RAID 配置,有硬件故障,直接更换硬盘,会自动同步数据。
如果没有做 RAID,处理方法如下:
正常节点上执行 gluster volume status,记录故障节点 uuid
执行:getfattr -d -m ‘.*’ /brick 记录 trusted.gluster.volume-id 及 trusted.gfid
以下为故障模拟及修复过程:
在 VMware Workstation 上移除 mystorage1 主机的第三块硬盘(对应 sdc /storage/brick2),相当于硬盘故障
# 系统提示如下: Message from [email protected] at Jul 30 08:41:46 ... storage-brick2[5893]: [2016-07-30 00:41:46.729896] M [MSGID: 113075] [posix-helpers.c:1844:posix_health_check_thread_proc] 0-gv2-posix: health-check failed, going down Message from [email protected] at Jul 30 08:42:16 ... storage-brick2[5893]: [2016-07-30 00:42:16.730518] M [MSGID: 113075] [posix-helpers.c:1850:posix_health_check_thread_proc] 0-gv2-posix: still alive! -> SIGTERM # 查看卷状态,mystorage1:/storage/brick2 不在线了,不过这是分布式复制卷,还可以访问另外 brick 上的数据 [[email protected] ~]# gluster volume status gv2 Status of volume: gv2 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick mystorage1:/storage/brick2 N/A N/A N N/A
在 VMware Workstation 上新增 mystorage1 一块硬盘,相当于更换了新硬盘,下面先格式挂载新硬盘:
# mkfs.xfs -f /dev/sdc # mkdir -p /storage/brick2 # mount -a # df -h # 新硬盘挂载后目录为空 [[email protected] ~]# ll /storage/brick2 total 0
开始手动配置新增硬盘的 gluster 参数
# 在 mystorage2 是获取 glusterfs 相关参数: [[email protected] tmp]# getfattr -d -m ‘.*‘ /storage/brick2 getfattr: Removing leading ‘/‘ from absolute path names # file: storage/brick2 trusted.gfid=0sAAAAAAAAAAAAAAAAAAAAAQ== trusted.glusterfs.dht=0sAAAAAQAAAAAAAAAAf////g== trusted.glusterfs.dht.commithash="3168624641" trusted.glusterfs.quota.dirty=0sMAA= trusted.glusterfs.quota.size.1=0sAAAAAATiAAAAAAAAAAAAAwAAAAAAAAAE trusted.glusterfs.volume-id=0sEZKGliY6THqhVVEVrykiHw== # 在 mystorage1 上执行配置 glusterfs 参数和上述一样 setfattr -n trusted.gfid -v 0sAAAAAAAAAAAAAAAAAAAAAQ== /storage/brick2 setfattr -n trusted.glusterfs.dht -v 0sAAAAAQAAAAAAAAAAf////g== /storage/brick2 setfattr -n trusted.glusterfs.dht.commithash -v "3168624641" /storage/brick2 setfattr -n trusted.glusterfs.quota.dirty -v 0sMAA= /storage/brick2 setfattr -n trusted.glusterfs.quota.size.1 -v 0sAAAAAATiAAAAAAAAAAAAAwAAAAAAAAAE /storage/brick2 setfattr -n trusted.glusterfs.volume-id -v 0sEZKGliY6THqhVVEVrykiHw== /storage/brick2 [[email protected] ~]# /etc/init.d/glusterd restart Starting glusterd: [ OK ] [[email protected] ~]# gluster volume heal gv2 info Brick mystorage1:/storage/brick2 Status: Connected Number of entries: 0 Brick mystorage2:/storage/brick2 /data Status: Connected Number of entries: 1 # 显示一个条目在修复,自动修复完成后会为 0 Brick mystorage3:/storage/brick1 Status: Connected Number of entries: 0 Brick mystorage4:/storage/brick1 Status: Connected Number of entries: 0 # 自动修复同步完成后,查看新硬盘的数据同步过来了 [[email protected] ~]# ll /storage/brick2 total 40012 -rw-r--r-- 2 root root 20480000 Jul 30 02:41 20M.file -rw-r--r-- 2 root root 20480000 Jul 30 03:13 20M.file1 drwxr-xr-x 2 root root 21 Jul 30 09:14 data
4.2 一台主机故障
一台节点故障的情况包含以下情况:
- 物理故障
- 同时有多块硬盘故障,造成数据丢失
- 系统损坏不可修复
解决方法:
找一台完全一样的机器,至少要保证硬盘数量和大小一致,安装系统,配置和故障机同样的 IP,安装 gluster 软件,
保证配置一样,在其他健康节点上执行命令 gluster peer status,查看故障服务器的 uuid
[[email protected] ~]# gluster peer status Number of Peers: 3 Hostname: mystorage3 Uuid: 36e4c45c-466f-47b0-b829-dcd4a69ca2e7 State: Peer in Cluster (Connected) Hostname: mystorage4 Uuid: c607f6c2-bdcb-4768-bc82-4bc2243b1b7a State: Peer in Cluster (Connected) Hostname: mystorage1 Uuid: 6e6a84af-ac7a-44eb-85c9-50f1f46acef1 State: Peer in Cluster (Disconnected)
修改新加机器的 /var/lib/glusterd/glusterd.info 和 故障机器一样
[[email protected] ~]# cat /var/lib/glusterd/glusterd.info UUID=6e6a84af-ac7a-44eb-85c9-50f1f46acef1 operating-version=30712
在信任存储池中任意节点执行
# gluster volume heal gv2 full
就会自动开始同步,但在同步的时候会影响整个系统的性能。
可以查看状态
# gluster volume heal gv2 info
以上是关于raid5需要几块硬盘的主要内容,如果未能解决你的问题,请参考以下文章