《Python机器学习kaggle案例》-- 网易云课堂
Posted learnfromnow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python机器学习kaggle案例》-- 网易云课堂相关的知识,希望对你有一定的参考价值。
https://study.163.com/course/courseMain.htm?courseId=1003551009
LinearRegression
# -*- coding: utf-8 -*- """ Created on Sat Dec 1 09:24:27 2018 @author: zh """ import pandas as pd import numpy as np titanic = pd.read_csv(‘train.csv‘) titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median()) titanic.loc[titanic[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 titanic.loc[titanic[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 titanic[‘Embarked‘] = titanic[‘Embarked‘].replace(‘nan‘, np.nan).fillna(‘S‘) titanic.loc[titanic[‘Embarked‘] == ‘S‘, ‘Embarked‘] = 0 titanic.loc[titanic[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 titanic.loc[titanic[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2 from sklearn.linear_model import LinearRegression from sklearn.cross_validation import KFold predictors = [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘] alg = LinearRegression() kf = KFold(titanic.shape[0], n_folds=3, random_state=1) predictions = [] for train, test in kf: train_predictors = (titanic[predictors].iloc[train, :]) train_target = titanic[‘Survived‘].iloc[train] alg.fit(train_predictors, train_target) test_predictions = alg.predict(titanic[predictors].iloc[test, :]) predictions.append(test_predictions) predictions = np.concatenate(predictions, axis=0) predictions[predictions > 0.5] = 1 predictions[predictions <= 0.5] = 0 accuracy = sum(predictions == titanic[‘Survived‘])/len(predictions) #accuracy = 0.7833894500561167
LogisticRegression
# -*- coding: utf-8 -*- """ Created on Sat Dec 1 09:34:55 2018 @author: zh """ import pandas as pd import numpy as np titanic = pd.read_csv(‘train.csv‘) titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median()) titanic.loc[titanic[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 titanic.loc[titanic[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 titanic[‘Embarked‘] = titanic[‘Embarked‘].replace(‘nan‘, np.nan).fillna(‘S‘) titanic.loc[titanic[‘Embarked‘] == ‘S‘, ‘Embarked‘] = 0 titanic.loc[titanic[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 titanic.loc[titanic[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2 predictors = [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘] from sklearn import cross_validation from sklearn.linear_model import LogisticRegression alg = LogisticRegression(random_state=1) scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic[‘Survived‘], cv=3) accuracy = scores.mean() #accuracy = 0.7878787878787877
RandomForestClassifier
# -*- coding: utf-8 -*- """ Created on Sat Dec 1 09:37:31 2018 @author: zh """ import pandas as pd import numpy as np titanic = pd.read_csv(‘train.csv‘) titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median()) titanic.loc[titanic[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 titanic.loc[titanic[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 titanic[‘Embarked‘] = titanic[‘Embarked‘].replace(‘nan‘, np.nan).fillna(‘S‘) titanic.loc[titanic[‘Embarked‘] == ‘S‘, ‘Embarked‘] = 0 titanic.loc[titanic[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 titanic.loc[titanic[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2 predictors = [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘] from sklearn import cross_validation from sklearn.ensemble import RandomForestClassifier predictors = [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘] alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1) kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic[‘Survived‘], cv=kf) accuracy = scores.mean() #accuracy = 0.7856341189674523 alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2) kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic[‘Survived‘], cv=kf) accuracy = scores.mean() #accuracy = 0.8159371492704826 max_acc = 0 for n_estimators in range(1,60,10): for min_samples_split in range(2,10): for min_samples_leaf in range(1,10): alg = RandomForestClassifier(random_state=1, n_estimators=n_estimators, min_samples_split=min_samples_split, min_samples_leaf=min_samples_leaf) kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic[‘Survived‘], cv=kf) accuracy = scores.mean() if accuracy>max_acc: print(n_estimators,min_samples_split,min_samples_leaf) max_acc = accuracy print(max_acc) #max_acc = 0.8316498316498316
feature_selection
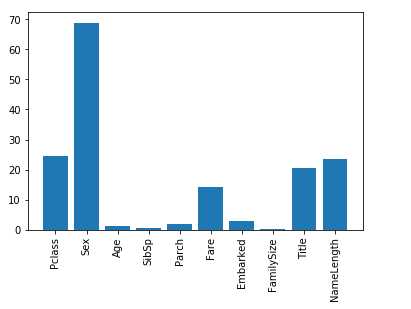
# -*- coding: utf-8 -*- """ Created on Sat Dec 1 09:52:38 2018 @author: zh """ import pandas as pd import numpy as np titanic = pd.read_csv(‘train.csv‘) titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median()) titanic.loc[titanic[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 titanic.loc[titanic[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 titanic[‘Embarked‘] = titanic[‘Embarked‘].replace(‘nan‘, np.nan).fillna(‘S‘) titanic.loc[titanic[‘Embarked‘] == ‘S‘, ‘Embarked‘] = 0 titanic.loc[titanic[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 titanic.loc[titanic[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2 titanic[‘FamilySize‘] = titanic[‘SibSp‘] + titanic[‘Parch‘] titanic[‘NameLength‘] = titanic[‘Name‘].apply(lambda x: len(x)) import re def get_title(name): title_search = re.search(‘ ([A-Za-z]+).‘, name) if title_search: return title_search.group(1) return ‘‘ titles = titanic[‘Name‘].apply(get_title) #pd.value_counts(titles) title_mapping = {‘Mr‘: 1, ‘Miss‘: 2, ‘Mrs‘: 3, ‘Master‘: 4, ‘Dr‘: 5, ‘Rev‘: 6, ‘Col‘: 7, ‘Major‘: 8, ‘Mlle‘: 9, ‘Capt‘: 10, ‘Ms‘: 11, ‘Jonkheer‘: 12, ‘Don‘:13, ‘Sir‘:14, ‘Countess‘:15, ‘Lady‘:16, ‘Mme‘:17} for k,v in title_mapping.items(): titles[titles==k]=v #pd.value_counts(titles) titanic[‘Title‘] = titles import numpy as np from sklearn.feature_selection import SelectKBest, f_classif import matplotlib.pyplot as plt predictors = [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘, ‘FamilySize‘, ‘Title‘, ‘NameLength‘] selector = SelectKBest(f_classif, k=5) selector.fit(titanic[predictors], titanic[‘Survived‘]) scores = -np.log10(selector.pvalues_) plt.bar(range(len(predictors)), scores) plt.xticks(range(len(predictors)), predictors, rotation=‘vertical‘) plt.show() from sklearn import cross_validation from sklearn.ensemble import RandomForestClassifier predictors = [‘Pclass‘, ‘Sex‘, ‘Fare‘, ‘Title‘] alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2) kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic[‘Survived‘], cv=kf) accuracy = scores.mean() #accuracy=0.8114478114478114
GradientBoostingClassifier
# -*- coding: utf-8 -*- """ Created on Sat Dec 1 09:52:38 2018 @author: zh """ import pandas as pd import numpy as np titanic = pd.read_csv(‘train.csv‘) titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median()) titanic.loc[titanic[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 titanic.loc[titanic[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 titanic[‘Embarked‘] = titanic[‘Embarked‘].replace(‘nan‘, np.nan).fillna(‘S‘) titanic.loc[titanic[‘Embarked‘] == ‘S‘, ‘Embarked‘] = 0 titanic.loc[titanic[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 titanic.loc[titanic[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2 titanic[‘FamilySize‘] = titanic[‘SibSp‘] + titanic[‘Parch‘] titanic[‘NameLength‘] = titanic[‘Name‘].apply(lambda x: len(x)) import re def get_title(name): title_search = re.search(‘ ([A-Za-z]+).‘, name) if title_search: return title_search.group(1) return ‘‘ titles = titanic[‘Name‘].apply(get_title) #pd.value_counts(titles) title_mapping = {‘Mr‘: 1, ‘Miss‘: 2, ‘Mrs‘: 3, ‘Master‘: 4, ‘Dr‘: 5, ‘Rev‘: 6, ‘Col‘: 7, ‘Major‘: 8, ‘Mlle‘: 9, ‘Capt‘: 10, ‘Ms‘: 11, ‘Jonkheer‘: 12, ‘Don‘:13, ‘Sir‘:14, ‘Countess‘:15, ‘Lady‘:16, ‘Mme‘:17} for k,v in title_mapping.items(): titles[titles==k]=v #pd.value_counts(titles) titanic[‘Title‘] = titles from sklearn.ensemble import GradientBoostingClassifier from sklearn.linear_model import LogisticRegression from sklearn.cross_validation import KFold algorithms = [ [GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘, ‘Title‘]], [LogisticRegression(random_state=1), [‘Pclass‘, ‘Sex‘, ‘Age‘, ‘SibSp‘, ‘Parch‘, ‘Fare‘, ‘Embarked‘, ‘Title‘]] ] kf = KFold(titanic.shape[0], n_folds=3, random_state=1) predictions = [] for train, test in kf: train_target = titanic[‘Survived‘].iloc[train] full_test_predictions = [] for alg, predictors in algorithms: alg.fit(titanic[predictors].iloc[train, :], train_target) test_predictions = alg.predict_proba(titanic[predictors].iloc[test, :].astype(float))[:,1] full_test_predictions.append(test_predictions) test_predictions = (full_test_predictions[0]*3 + full_test_predictions[1])/4 test_predictions[test_predictions <= 0.5] = 0 test_predictions[test_predictions > 0.5] = 1 predictions.append(test_predictions) predictions = np.concatenate(predictions, axis=0) accuracy = sum(predictions == titanic[‘Survived‘])/len(predictions) #accuracy=0.8204264870931538
以上是关于《Python机器学习kaggle案例》-- 网易云课堂的主要内容,如果未能解决你的问题,请参考以下文章
Python机器学习及实战kaggle从零到竞赛pdf电子版下载
PYTHON机器学习及实践_从零开始通往KAGGLE竞赛之路pdf
高端实战 Python数据分析与机器学习实战 Numpy/Pandas/Matplotlib等常用库
PYTHON机器学习及实践 从零开始通往KAGGLE竞赛之路pdf