Python基础之(基本数据类型及运算)
Posted Crazyjump
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础之(基本数据类型及运算)相关的知识,希望对你有一定的参考价值。
一、运算
1.1、算数运算
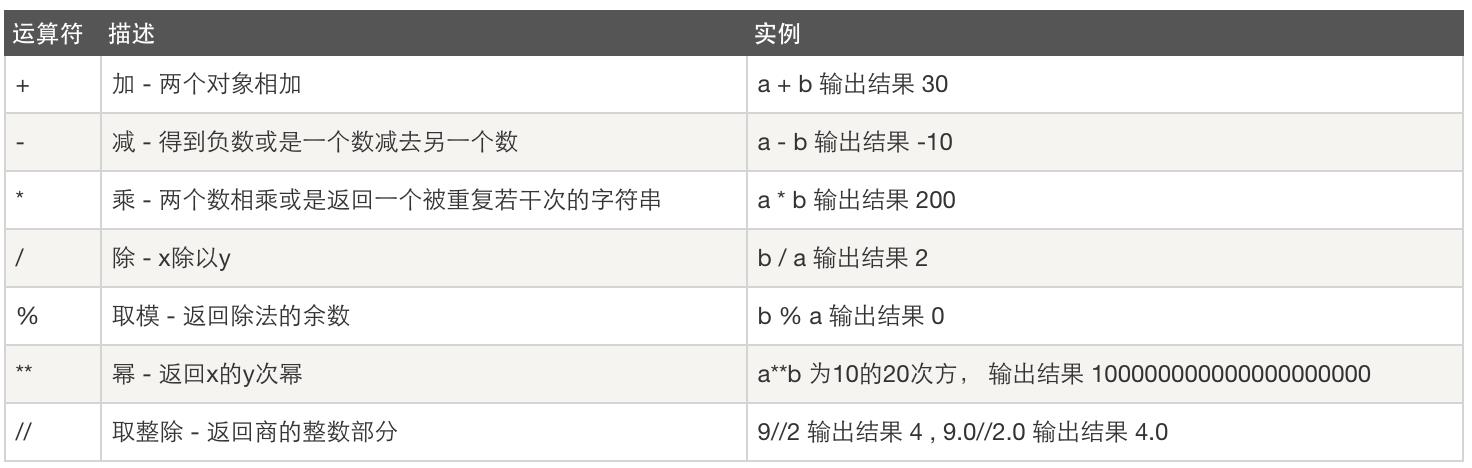
1.2、比较运算:

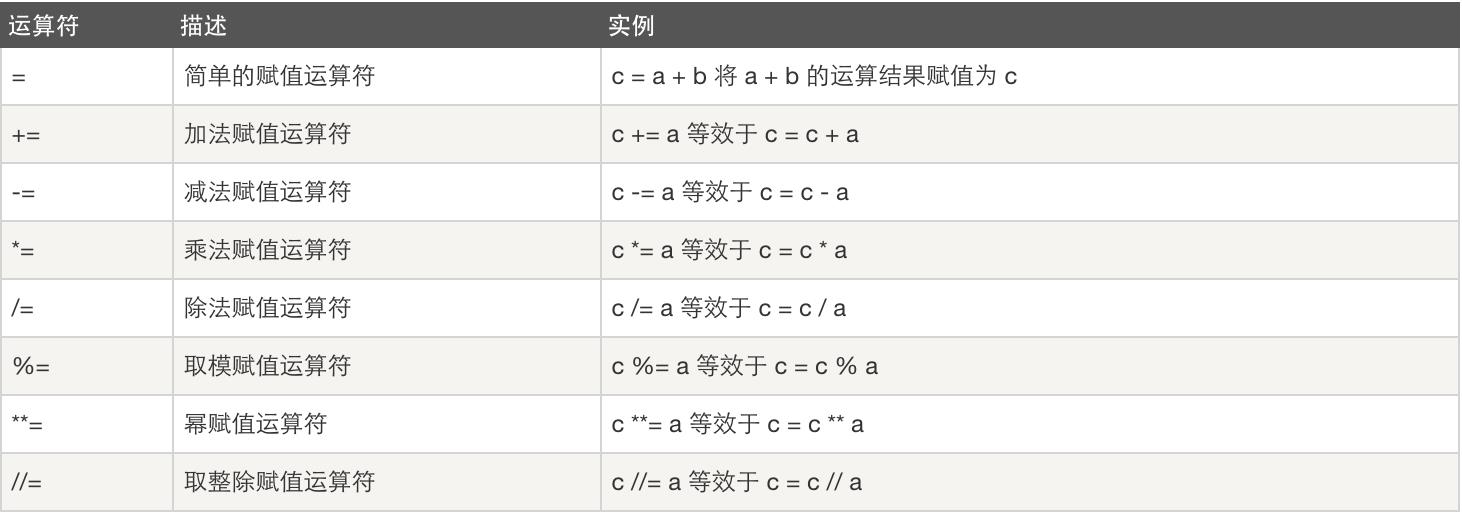
1.3、赋值运算:
1.4、逻辑运算:

1.5、成员运算:

针对逻辑运算的进一步研究:
1、在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2、 x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
3、Python运算符优先级,以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 \'AND\' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
二、基本数据类型
2.1、数字,int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
"hello world"
在Python中,加了引号的字符都被认为是字符串
2.3.1、索引:
a = \'ABCDEFGHIJK\' print(a[1]) print(a[3]) print(a[5]) print(a[7])
执行结果:
2.3.2、切片,切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串
a = \'ABCDEFGHIJK\' print(a[1:3]) print(a[0:5]) print(a[0:]) #默认从开始到最后 print(a[0:-1]) # -1 是列表中最后一个元素的索引,但是取不到 print(a[0:5:2]) #加步长 print(a[5:0:-2]) #反向加步长
执行结果:

2.3.3、字符串常用方法:
最常用的为:join(字符串拼接)\\spilt(切割)\\find(查找)\\strip(去空格)\\upper、lower(大小写转换)\\encode、decode(编码、解码)
a="abcABC"
#公共方法len(a),type(a)
a.capitalize() #首字母大写
a.upper() #转换大写
a.lower() #转换小写
a.swapcase() #大小写转换
a.casefold() #转换小写
a.title() #转换成标题
a.center(20,"*")#设置宽度,并居中,20为总长度,*为空白处填充
a.ljust(20,"*") #左边
a.rjust(20,"*") #右边
a.zfill(20) #默认使用0填充,长度20
a.expandtabs() #补tab键
a.count("xx",star,end) #计数出现次数,star开始位置,end结束位置
a.strip() #去全部空格、换行
a.lstrip("xx") #去除左边 xx
a.lstrip() #去左边空格
a.rstrip() #去右边空格
a.partition("s") #字符串按照第一个s进行分割,分三份 (包含分割元素s)
a.split("s") #a.split("s",2) 按照s进行分割 ,2为分割次数 (不包含分割元素s)
a.splitlens() #按换行符分割
a.find("ex",start=None, end=None) #找到第一个对应字符串的索引,默认是找整体,也可单独指定判断位置 (找不到返回-1)
(a.index()与find相同,但找不到报错 )
a.endswith("x") #以判断x结尾
a.startswith("x",start=None, end=None)#判断以x开头,默认是找整体,也可单独指定判断位置
a.isalnum() #判断字符串中包含数字或字符
a.isalpha()#判断是否是字符
a.isdeciml() #判断是否是数字 (10进制数字)
a.isdigit()#判断是否是数字,支持特殊形式
a.isdentifier() #判断字母、数字、下划线
a.islower()#判断是否小写
a.isupper()#判断是否是大写
a.isnumeric()#判断是否是数字 支持特殊字符(中文)
a.isprintable() #判断是否包含不可显示的字符如:\\t \\n
a.isspace() #判断是否全部 是空格
a.istitle() #判断是否是标题
a.replace("xx","oo") #xx替换oo
a.join(xxx) #字符串拼接,a作为拼接符,重新拼接xxx (" ".join(xx) "xx".join(dd))
a.format(name="xxxx") #替换name
a.format_map
a.encode() #编码 str转换bytes
a.decode() #解码 获得字符串类型对象
a=["name","age","job","addr"]
2.4.2、增加
li = ["a","b","c"]
li.append("d") #增加到末尾
print(li)
li.insert(0,"aa") #按索引位置增加
print(li)
li.extend([\'q,w,e\']) #迭代增加
print(li)
li.extend(\'w\')
li.extend(\'p,l,m\')
print(li)
执行结果:
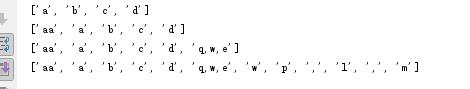
2.4.3、删除
li = ["a","b","c"] l1 = li.pop(1) #按照位置去删除,有返回值,默认删除最后一个值 print(l1) print(li) del li[1:3] #按照位置去删除,也可切片删除没有返回值。 print(li) li.remove(\'a\') #按照元素去删除 print(li)
执行结果:

2.4.4、改
li = ["a","b","c","d"] li[1] = \'dfasdfas\' print(li) li[1:3] = [\'b1\',\'c1\'] print(li)
执行结果:

2.4.5、查
切片去查,或者循环去查,与str的切片、索引相同
2.4.6 其他补充:
li = [] li.reverse() #将当前列表反转 li.sort() #排序 默认从小到大 li.sort(reverse=True) #从大到小 li.copy() #浅拷贝 li.count(xxx) #计算元素xxx出现的次数 li.index(xx) #根据元素值获取其索引位置 li.clear() #清空列表
dict = {"k1":"v1","k2":"v2"}
2.5.1、增加
dic = {"k1":"v1","k2":"v2"}
dic[\'li\'] = ["a","b","c"]
dic.setdefault(\'k\',\'v\') #在字典中添加键值对,如果只有键那对应的值是none,但是如果原字典中存在设置的键值对,则他不会更改或者覆盖。
print(dic)

2.5.2 、删除
dic = {"name":"crazyjump","age":18,"job":"民工"}
dic_pop = dic.pop("a",\'无key默认返回值\') # pop根据key删除键值对,并返回对应的值,如果没有key则返回默认返回值
print(dic_pop)
print(dic)
del dic["name"] # 没有返回值。
print(dic)
dic_pop1 = dic.popitem() # 随机删除字典中的某个键值对,将删除的键值对以元祖的形式返回
print(dic_pop1)
print(dic)
dic_clear = dic.clear() # 清空字典
print(dic,dic_clear) # {} None
执行结果:

2.5.3、改
dic = {"name":"crazyjump","age":18,"job":"民工"}
dic1 = {"age":20,"k":"v"}
dic.update(dic1) # 将dic1所有的键值对覆盖添加(相同的覆盖,没有的添加)到dic中
print(dic)
执行结果:
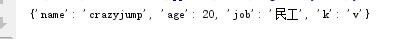
2.5.4、查
dic = {"name":"crazyjump","age":18,"job":"民工"}
value = dic["name"]
print(value)
print(dic.get("n")) #key值不存在返回None
print(dic.get("s",12 )) #值不存在,返回定义的12
dic.setdefault("x","z") #不存在就新增,存在获取当前值
print(dic.setdefault("name","z"))
print(dic)
执行结果:

2.5.5、字典的循环
dic = {"name": "crazyjump", "age": 18, "job": "民工"}
for k, v in dic.items():
print(k, v)
for k in dic.items():
print(k)
for k in dic.keys():
print(k)
for v in dic.values():
print(v)
for k in dic:
print(k)
执行结果:
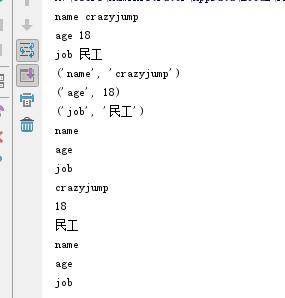
2.5.6、补充(可迭代对象)
dic = {"name":"crazyjump","age":18,"job":"民工"}
l = dic.items()
print(l)
k = dic.keys()
print(k)
v = dic.values()
print(v)
执行结果:

tu=(11,22,33,"aaa")
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
2.7.1、创建集合:
set1 = set({1,2,\'xxx\'})
set2 = {1,2,\'xxx\'}
2.7.2、增加
set1={"a","b",12,"c"}
set1.add("d") #增加
set1.update(\'A\') #迭代增加
print(set1)
set1.update(\'哈哈\')
print(set1)
set1.update([1,2,3])
print(set1)

2.7.3、删
set1={"a","b",12,"c"}
set1.pop() #删除任意一个
set1.remove(12) #删除指定xx,指定的元素不存在会报错
set1.discard("xx") #删除指定xx ,指定的元素不存在不会报错
print(set1)
set1.clear() #清空集合
print(set1)
执行结果:
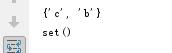
补充:集合查询使用循环即可
2.7.4、集合的其他操作
2.7.4.1、交集 (& 或者 intersection)
set1 = {1,7,8,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2)
print(set1.intersection(set2))
执行结果:

2.7.4.2、并集(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2)
print(set2.union(set1))
执行结果:

2.7.4.3、差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2)
print(set1.difference(set2)) #set独有的
执行结果:

2.7.4.4、反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
执行结果:

2.7.4.5、子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
2.7.4.6、frozenset不可变集合,让集合变成不可变类型。
s = frozenset(\'barry\')
print(s,type(s)) # frozenset({\'a\', \'y\', \'b\', \'r\'}) <class \'frozenset\'>
三、数据类型总结
3.1、数字:不可变,直接访问
3.2、字符串:不可变,顺序访问
3.3、列表:可变、有序、顺序访问
3.4、字典:可变、无序、key值访问
3.5、元组:不可变、有序、顺序访问
3.6、布尔值:不可变
3.7、集合:无序、不重复
补充
一、格式化输出:
1.1、%s
name = input(\'你的姓名:\') age = input(\'你的年龄:\') job = input(\'你的工作:\') info = "欢迎 %s,你的年龄是:%s ,你的工作是:%s "%(name,age,job) print(info)
执行结果:

%s就是代表字符串占位符,除此之外,还有%d是数字占位符,%f是浮点数, 如果把上面的age后面的换成%d,就代表你必须只能输入数字,否则就会报错 (另%3==3%%)
1.2、srt.format()
a = "{},{}".format("hello","world")
# 默认顺序
b = "{1},{0},{1}".format("hello","world")
#指定顺序
c = "{name},{age}".format(name="crazyjump",age=12)
print("a:",a)
print("b:",b)
print("c:",c)
执行结果:

二、for 循环(用户按照顺序循环可迭代对象的内容):
msg = "crazyjump"
for item in msg:
print(item)
data = [1,2,3,4]
for item in msg:
print(iterm)
三、enumrate为可迭代的对象添加序号
li = [\'a\',\'b\',\'c\',\'d\',\'e\']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1): #索引默认从0开始,可改成1开始
print(index,name)
执行结果:
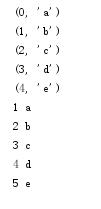
四、range 指定范围,生成指定数字。
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
五、深浅拷贝
5.1、浅拷贝 (id() 对象的内存地址)
li = ["a", "b", [\'crazy\', \'jump\']] l1 = li.copy() print(li, id(li)) print(l1, id(l1)) li[1] = "c" print(l1, id(l1)) print(li, id(li)) li[2][0] = \'DB\' print(l1, id(l1[2])) print(li, id(li[2]))
执行结果:
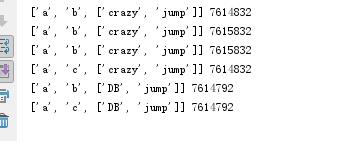
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
5.2、深拷贝
import copy l1 = ["a",[\'crazy\',\'jump\']] l2 = copy.deepcopy(l1) print(l1,id(l1)) print(l2,id(l2)) l1[0] = 222 print(l1,id(l1)) print(l2,id(l2)) l1[1][0]="db" print(l1,id(l1[1])) print(l2,id(l2[1]))
执行结果:
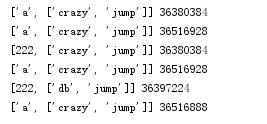
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变
以上是关于Python基础之(基本数据类型及运算)的主要内容,如果未能解决你的问题,请参考以下文章