python简单入门
Posted 少年与python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python简单入门相关的知识,希望对你有一定的参考价值。
一. 初识python.
1. 认识计算机
CPU(大脑) 3GHZ + 内存(DDR4) + 主板 + 电源(心脏)+ 显示器 + 键盘 +鼠标+ 显卡 + 硬盘 80MB/s
操作系统
windows 家用
linux 服务器
macOS 家用+服务器
计算机是一个高度集成的电子电路
高低电平. 二进制
二进制没有2 -> 0 1
八进制没有8 -> 0-7
十进制没有10 -> 0-9
十六进制没有16 -> 0-9 A-F
显卡
1. NAVID 看型号。
2. AMD 图形处理
2. python历史
python是一门弱类型解释型高级编程语言
编译型, 把写好的程序编译成计算机认识的二进制
优点:一次编译到处运行。 运行效率高, 开发效率低 0.001s
解释型,
缺点:运行慢 0.01s
优点:开发效率高. 简单
3. python的版本
2.x 老版本已经不再更新,2020年已将淘汰
3.x 学习用这个
4. 安装
网址:python.org
选择:3.6.5 mac选择macOS 64-bit installer
安装:

5. 编辑器的选择
1. 所有的文本编辑器都可以编写代码。记事本,Editplus,sublime, pycharm(收费)
2. 可以在命令行写代码.
6. 第一个python程序
python程序有两种编写方式:
1. 进入cmd控制台. 输入python进入编辑模式. 这时候我们可以直接编写python程序
2. 也可以在.py文件中编写python代码. 通过python命令来执行python代码
7. 变量
概念: 把程序运行过程中产生的中间值保存在内存. 方便后面使用.
命名规范:
1. 数字, 字母, 下划线组成
2. 不能数字开头, 更不能是纯数字
3. 不能用关键字
4. 不要用中文
5. 要有意义
6. 不要太长
7. 区分大小写
8. 驼峰或者下划线命名
数据类型:
1. int 整数 +-*/ % // **
2. str 字符串 \', ", \'\'\', """ 括起来的内容 +拼接 (用"+"连接的两端必须是字符串),*重复("*"后面必须跟的是数字),
3. bool 布尔 True, False
4.换行:"\\n"表示转移字符,换行. 三个单引号或者三个双引号中的字符串内回车即可换行
5.类型转换
int(str) # 字符串转换成整数
str(int) # 整数转换成字符串
8. 常量
本质就是变量. 所有字母都大写
9. 用户交互
变量 = input(提示语)
所有的输入的内容都是字符串
int(变量) 把变量转化成数字
10. if条件判断
1.
if 条件:
if语句块
执行流程:判断条件是否为真. 如果真. 执行if语句块
2.
if 条件:
if语句块
else:
else语句块
执行流程:判断条件是否为真. 如果真. 执行if语句块 否则执行else语句块
3.
if 条件1:
if-1
elif 条件2:
if-2
elif 条件3:
if-3
....
else:
else语句块
执行流程:
判断条件1是否成立, 如果成立执行if-1
否则如果条件2成立, 执行if-2
否则如果条件3成立, 执行if-3
....
否则执行else语句块
4. 嵌套
if 条件:
if 条件:
..
else:
if 条件:
...
11. while循环
while 条件:
循环体(break, continue)
能够让循环退出: 1. break 2. 改变条件
continue 停止当前本次循环,继续执行下一循环
break 彻底的干掉一个循环
二.运算符和编码
1. 格式化输出
%s就是代表字符串的占位符,可以代替所有
%d,是数字占位符,只能代替数字
name = input("请输入你的名字:")
address = input("你来自哪里:")
hobby = input("你喜欢什么:")
#比较繁琐的方式
print("我叫"+name+",我来自"+address+",我喜欢"+hobby)
#通用的方式
print("我叫%s,我来自%s,我喜欢%s" % (name,address,hobby))
# python的新版本的方式,简单
print(f"我叫{name},我来自{address},我喜欢{hobby}")
print("我叫%s,我已经度过了人生的30%%" % "好人") #如果占位时字符串中有%,需要用%%来表示
2. 运算符 and or not (难点)
1.算数运算符
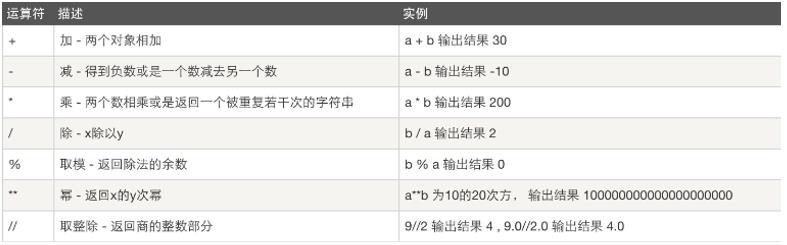
2. 比较运算符

3.赋值运算符
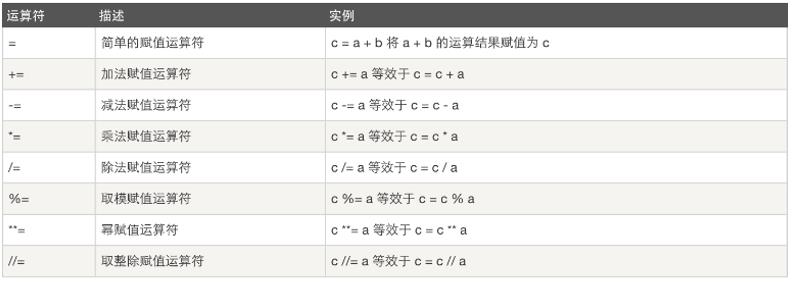
4.逻辑运算符

运算顺序: ()=> not => and =>or
当出现 X or Y 时,判断X是否为0,如果X是0,则输出Y,否则返回X
当出现 X and Y 时,判断X是否为0,如果X是0,则输出X,否则输出Y
True相当于非0 , False相当于0
补充:in和not in
可以判断xxx字符串是否出现在xxxxx字符串中
content = input("请输入你的评论")
if "苍老师" in content or \'邱老师\' in content:
print(\'你输入的内容不合法\')
else:
print("评论成功")
3. 初识编码 gbk unicode utf-8
1. ascii 8bit 1byte(字节) 256个码位 只用到了7bit, 用到了前128个 最前面的一位是0
2. 中国人自己对计算机编码进行统计. 自己设计. 对ascii进行扩展 ANSI 16bit -> 清华同方 -> gbk
GBK 放的是中文编码. 16bit 2byte 兼容ascii
3. 对所有编码进行统一. unicode. 万国码. 32bit. 4byte. 够用了但是很浪费
4. utf-8 可变长度的unicode
英文: 1byte
欧洲文字: 2byte
中文: 3byte
字节(byte)
1byte = 8bit
1kb = 1024byte
1mb = 1024kb
1gb = 1024mb
1tb = 1024gb
1pb = 1024tb
三.字符, 列表和元组
1. 基本数据类型概况
1, int 整数
2. str 字符串
3. bool 布尔值
4. list 列表. 一般存放大量的数据 ["门神xxxx", "风扇哥xxxx", 元素]
5. tuple 元组. 只读列表, 只能看啥也不能干. (元素, 元素)
6. dict 字典. {"风扇哥":"王伟哲", "wlh": "王力宏"}
7. set 集合 {"风扇哥", "wlh"}. 不重复
8. bytes 一堆字节. 最小数据单元
2. int类型的相关操作.
数字没办法执行其他操作. 操作只有+-*/, //, %, **
8bit => 1byte
bit_length() 二进制长度
3. bool类型的操作. 基本类型转换的问题
bool类型没有操作.
类型转换
结论一: 想把xxx转化成yy类型. yy(xxx)
结论二: 能够表示False的数据: 0, "", [], {}, set(), tuple(), None, False
4. str 认识字符串(重点, 多)
字符: 单一的文字符号
字符按照固定的顺序连成串
被\' 或者" 或者\'\'\' 或者"""括起来的内容
索引 编号, 顺序
从0开始
切片

s[start:end:step]
start:开始
end: 结束 取不到
step: 步长, 控制方向. 每xx个取一个

一大波操作.
字符串是不可变的数据类型. 不论如何操作.对原来的字符串是不会有影响的
1, upper() 转换成大写. 忽略大小写
2, strip() 去掉左右两端的空白 空格, \\t \\n. 所有用户输入的内容都要去空白
3, replace(old, new) 把old替换成new
4, split() 字符串切割
5, startswith() 判断是否以xxx开头
6, find() 查找, 找不到返回-1
7, isdigit() 判断是否是数字组成
8, len() 求长度
for循环遍历字符串
for 变量 in 可迭代对象:
循环体
for c in s: # c: charactor(字符) s: string
print(c)
5. 什么是列表
定义: 能装对象的对象
在python中使用[]来描述列表, 内部元素用逗号隔开. 对数据类型没有要求
列表存在索引和切片. 和字符串是一样的.
6. 相关的增删改查操作(重点)
添加:
1. append() 追加
2. insert(位置, 元素) 插入指定元素到指定位置
删除:
1. pop(index) 根据索引删除
2. remove(元素) 根据元素删除
修改:
索引修改
lst[索引] = 元素
查询:
for循环.
7. 列表的嵌套
多个列表互相嵌套
8. 列表的其他操作
1. count() 计数
2. sort() 排序,升序 ; sort(reverse = True)降序
3. reverse() 翻转
4. len() 求长度
9. 什么是元组
能装对象的对象. 不可变. 一旦确认好. 不可更改
只读列表
可以迭代
10. 元组的嵌套
和列表一样.都可以互相嵌套.
元组的不可变: 指向不变
元组不可改,列表可以改
tu = ruple() 空元组,固定写法
当元组中只有一个元素时 tu = (1,) 要加","
tu = (1) # 不是元组,<class,\'int\'>
tu = (1,) # 是元组,<class,\'tuple\'>
元组也是可迭代的,可以使用for循环
关于不可变, 注意: 这里元组的不可变的意思是子元素不可变. 而子元素内部的子元素是可以变, 这取决于子元素是否是可变对象.
11. range(重点, 难点)
数数
range() 可迭代对象
range(参数) [0, 参数)
range(参数1,参数2) [参数1, 参数2)
range(参数1,参数2,step) [参数1,参数2) 每隔step取一个
# 重点
for i in range(len(lst)):
i 索引
lst[i] 元素
print(i, lst[i])
四. 字典和集合
1. 什么是字典
字典是以key:value的形式来保存数据
用{}表示. 存储的是key:value
2. 字典的增删改查(重点)
1. 添加
dic[新key] = 值
setdefault()
2. 删除
pop(key)
3. 修改
dic[老key] = 值
update() 跟新字典
4. 查询
dic[key]
get(key, 值)
setdefault(key, value)
5. 遍历,字典是一个可迭代对象
3. 字典的相关操作
1. keys() 获取到所有的键
2. values() 获取到所有的值
3. items() 拿到所有的键值对
4. 字典的嵌套
字典的嵌套. 字典套字典
5. 集合(不重要). 去重复
集合中的元素是不重复的. 必须是可哈希的(不可变), 字典中的key
空集合:set()
空元组:tuple()
空列表:list()
非空集合: {123}集合, 集合其实就是不存value的字典
六.小数据池
1. 小数据池, id()
小数据池针对的是: int, str, bool
在py文件中几乎所有的字符串都会缓存.
id() 查看变量的内存地址
2. is和==的区别
is 比较的是内存地址
== 比较的是内容
当两个变量指向同一个对象的时候. is是True, ==也是True
3. 编码
1. ascii. 有: 数字, 字母, 特殊字符. 8bit 1byte 128 最前面是0
2. gbk. 包含: ascii, 中文(主要), 日文, 韩文, 繁体文字. 16bit, 2byte.
3. unicode. 包含gbk,ascii,big5... 32bit, 4byte
4. utf-8. 可变长度的unicode.
1. 英文: 8bit,1byte
2. 欧洲文字: 16bit 2byte
3. 中文: 24bit 3byte
不同的编码之间不能随意转换. 中国人gbk和德国人utf-8骂 想要沟通必须通过英文(unicode)(媒介)
在python3中. 默认的编码是unicode,我们的字符串就是unicode
在python2中. 默认的编码是ASCII. Cpython.c语言的默认编码是ASCII
unicode弊端:在存储和传输的时候. 是很浪费的
在存储和传输的时候不能直接使用unicode. 必须要对字符串进行编码. 编码成bytes类型
bytes: 字节形式的字符串
1. encode(编码格式) 编码
2. decode(编码格式) 解码
bytes是一种另类的字符串表示形式
"哈哈哈" => \\xee\\xab\\x13\\xee\\xab\\x13\\xee\\xab\\x13
七. join,fromkeys和深浅拷贝
1. join,fromkeys
join()
"*".join("马虎疼") # 马*虎*疼 把传递进去的参数进行迭代. 获取到的每个元素和前面的*进行拼接. 得到的是字符串
split() 切割. 切割的结果是列表
列表和字典: 都不能在循环的时候直接删除
把要删除的内容记录在新列表中然后循环这个新列表. 删除列表(字典)
fromkeys()
坑1: 返回新字典. 不会更改老字典
坑2: 当value是可变的数据类型. 各个key共享同一个可变的数据类型. 其中一个被改变了. 其他都跟着变
2. 深浅拷贝(重点, 难点)
1. = 没有创建新对象, 只是把内存地址进行了复制
2. 浅拷贝 lst.copy() 只拷贝第一层.
3. 深拷贝
import copy
copy.deepcopy() 会把对象内部的所有内容进行拷贝
八. 文件操作
1. 文件操作
open 打开
f = open(文件路径, mode="模式", encoding="编码格式") 最最底层操作的就是bytes
打开一个文件的时候获取到的是一个文件句柄.
绝对路径
从磁盘根目录开始寻找
相对路径
相对于当前程序所在的文件夹
../ 上一层文件
文件夹/ 进入xxx文件夹
2. mode:
打开文件的方式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默认使用的是r(只读)模式
r: 读取,只读.
读取文件的相关操作
1. read()
默认: 读取文件内容(全部)
read(n) 读取n个字符
2. readline() 读取一行
3. readlines() 读取全部. 返回列表
(最重要)4. for line in f: 每次读取一行内容
w:
写入. 只写
创建文件
会清空文件
a:
也可以创建文件
追加写
r+: 对于文件而言. 应该有的操作就两个:读, 写
读写操作
w+:
写读操作
a+:
追加写读
所有带b的表示直接操作的是bytes, 当处理非文本文件的时候.
rb
wb
ab: 断点续传
r+b
w+b
a+b
深坑请注意: 在r+模式下. 如果读取了内容. 不论读取内容多少. 光标显示的是多少. 再写入 或者操作文件的时候都是在结尾进行的操作.
3. 文件操作中关于文件句柄的相关操作
seek() 移动光标
f.seek(0) 移动到开头(最多)
f.seek(0, 2) 移动到末尾
seek:两个参数
1. 表示偏移量
2. 从xxx开始偏移, 默认0, 开头 1, 当前位置 2, 末尾
tell:
返回光标所在的位置
4. 文件修改, 实际操作(重点)

九. 初识函数
1. 什么是函数?
f(x) = x + 1
y = x + 1
函数是对功能或者动作的封装
2. 函数的语法和定义
def 函数名():
函数体
调用:
函数名()
3. 关于函数的返回值
return : 返回
1. 当程序没写过return, 不返回任何结果. 如果你非要接收. 接受到的是None
2. 当函数写return 值, 有一个返回值.
3. 当函数写了return 值1, 值2, 值3.... 返回多个结果. 多个结果打包成元组
4. 当程序执行到return, 函数结束执行
4. 函数的参数(部分)
小括号是什么, 小括号表示调用, 传参
什么是参数: 参数是给函数传递的信息
1.形参: 在函数声明的位置写的变量
1. 位置参数
2. 默认值
3. 动态传参 *, **
2.实参: 在函数调用的时候给函数传递的具体的值
1. 位置参数
2. 关键字参数
3. 混合: 位置, 关键字
3.传参: 把实参给形参的过程
4. 动态传参(重点) *, **
*, ** :
形参: 聚合
位置参数* -> 元组
关键字** -> 字典
实参: 打散
列表, 字符串, 元素 -> *
字典 -> **
形参顺序(重点):
位置, *args, 默认值, **kwargs
无敌传参
def func(*args, **kwargs): arguments参数 keyword-arguments关键字参数
pass
十.函数的进阶
1. 作用域和名称空间
名称空间: (用来存放名字(变量, 函数名, 类名, 引入的模块名)的)
1. 全局名称空间: 我们在py文件中自己写的变量, 函数.....
2. 内置名称空间: 我们python解释器提供好的一些内置内容(print, input....)
3. 局部名称空间: 在我们执行函数的时候.会产生一个局部名称空间. 放的是: 函数内部的内容(变量, 函数,类...)
名称空间可能会有无数个, 局部名称空间而言. 相对是独立的.一般互不干扰
作用域:
1. 全局作用域: 内置+全局
2. 局部作用域: 局部
globals() 查看全局作用域
locals() 查看当前作用域
2. 函数的嵌套
在函数中声明函数
在内部函数中使用变量的时候, 查找顺序: 先找自己 -> 上一层 -> 上一层..全局 -> 内置
3. nonlocal和global关键字(重点)
global: 在局部引入全局变量
nonlocal: 在局部...内层函数引入外层离他最近的那个变量.
十一. 第一类对象 闭包 迭代器
1.第一类对象-> 函数名 -> 变量名
函数对象对象可以像变量一样进行赋值
还可以作为列表的元素进行使用
可以作为返回值返回
可以作为参数进行传递
2.闭包 -> 函数的嵌套
内层函数对外层函数中的变量的使用
好处:
1. 保护变量不被侵害
2. 让一个变量常驻内存
如何通过代码查看一个闭包
__closure__: 有东西就是闭包. 没东西就不是闭包
3.迭代器 -> 固定的思路. for循环
一个数据类型中包含了__iter__函数表示这个数据是可迭代的
dir(数据): 返回这个数据可以执行的所有操作
判断迭代器和可迭代对象的方案(野路子)
__iter__ 可迭代的
__iter__ __next__ 迭代器
判断迭代器和可迭代对象的方案(官方)
from collections import Iterable, Iterator
isinstance(对象, Iterable) 是否是可迭代的
isinstance(对象, Iterator) 是否是迭代器
模拟for循环
lst= []
# 拿迭代器
it = lst.__iter__()
while 1:
try:
it.__next__()
except StopIteration:
break
特征:
1. 省内存(生成器)
2. 惰性机制
3. 只能向前. 不能后退
作用:统一了各种数据类型的遍历
十二. 生成器和各种推导式
1. 生成器
本质就是迭代器.
一个一个的创建对象
创建生成器的方式:
1. 生成器函数
2. 通过生成器表达式来获取生成器
3. 类型转换(看不到)
2. 生成器函数 (重点)
生成器函数中包含 yield , 返回数据和return差不多.
return会立即结束这个函数的执行
yield 可以分段的执行一个函数
生成器函数在执行的时候返回生成器. 而不是直接执行此函数
能向下执行的两个条件:
__next__() :执行到下一个yield
send() :执行到下一个yield, 给上一个yield位置传值
所有的生成器都是迭代器都可以直接使用for循环
都可以使用list()函数来获取到生成器内所有的数据
生成器中记录的是代码而不是函数的运行
def func():
print("我的天哪 ")
yield "宝宝"
gen = func() # 创建生成器. 此时运行会把生成器函数中的代码记录在内存
当执行到__next__(), 运行此空间中的代码, 运行到yield结束.
优点: 节省内存, 生成器本身就是代码. 几乎不占用内存
特点: 惰性机制, 只能向前. 不能反复
3. 各种推导式 (诡异)
列表推导式 [结果 for循环 if]
字典推导式 {结果(k:v) for循环 if}
集合推导式 {结果(k) for循环 if}
4. 生成器表达式 (重点)
(结果 for循环 if)
以上是关于python简单入门的主要内容,如果未能解决你的问题,请参考以下文章