[Python数据挖掘]第2章Python数据分析简介
Posted 进击的小猴子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python数据挖掘]第2章Python数据分析简介相关的知识,希望对你有一定的参考价值。
《Python数据分析与挖掘实战》的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得
1、Python数据结构

2、Numpy数组
import numpy as np #一般以np作为numpy的别名
a = np.array([2, 0, 1, 5]) #创建数组 print(a) #输出数组 print(a[:3]) #引用前三个数字(切片) print(a.min()) #输出a的最小值 a.sort() #将a的元素从小到大排序,此操作直接修改a,因此这时候a为[0, 1, 2, 5] b= np.array([[1, 2, 3], [4, 5, 6]]) #创建二维数组 print(b*b) #输出数组的平方阵,即[[1, 4, 9], [16, 25, 36]]
[2 0 1 5] [2 0 1] 0 [[ 1 4 9] [16 25 36]]
3、Scipy矩阵
from scipy.optimize import fsolve #导入求解方程组的函数 from scipy import integrate #导入积分函数 def f(x): #定义要求解的方程组 x1 = x[0] x2 = x[1] return [2*x1 - x2**2 - 1, x1**2 - x2 -2] result = fsolve(f, [1,1]) #输入初值[1, 1]并求解 print(result) #输出结果,为array([ 1.91963957, 1.68501606]) #数值积分 def g(x): #定义被积函数 return (1-x**2)**0.5 pi_2, err = integrate.quad(g, -1, 1) #积分结果和误差 print(pi_2 * 2) #由微积分知识知道积分结果为圆周率pi的一半
[ 1.91963957 1.68501606] 3.141592653589797
4、Matplotlib可视化
import numpy as np import matplotlib.pyplot as plt #导入Matplotlib x = np.linspace(0, 10, 1000) #作图的变量自变量 y = np.sin(x) + 1 #因变量y z = np.cos(x**2) + 1 #因变量z plt.figure(figsize = (8, 4)) #设置图像大小 plt.plot(x,y,label = \'$\\sin x+1$\', color = \'red\', linewidth = 2) #作图,设置标签、线条颜色、线条大小 plt.plot(x, z, \'b--\', label = \'$\\cos x^2+1$\') #作图,设置标签、线条类型 plt.xlabel(\'Time(s) \') # x轴名称 plt.ylabel(\'Volt\') # y轴名称 plt.title(\'A Simple Example\') #标题 plt.ylim(0, 2.2) #显示的y轴范围 plt.legend() #显示图例 plt.show() #显示作图结果


5、Pandas数据分析和探索
Pandas基本数据结构是Series和DataFrame
s = pd.Series([1,2,3], index=[\'a\', \'b\', \'c\']) #创建一个序列s d = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns = [\'a\', \'b\', \'c\']) #创建一个表 d2 = pd.DataFrame(s) #也可以用已有的序列来创建表格
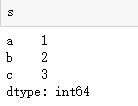


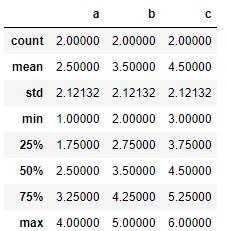
#读取文件,注意文件的存储路径不能带有中文,否则读取可能出错。 pd.read_excel(\'data.xls\') #读取Excel文件,创建DataFrame。 pd.read_csv(\'data.csv\', encoding = \'utf-8\') #读取文本格式的数据,一般用encoding指定编码。 #d.head() #预览前5行数据 d.describe() #数据基本统计量
6、Keras神经网络
构建一个MLP(多层感知器), 无法运行,需要适配相应的数据
from keras.models import Sequential from keras.layers.core import Dense,Dropout,Activation from keras.optimizers import SGD model=Sequential() #模型初始化 model.add(Dense(64,input_dim=20)) #添加输入层(20节点)、第一隐藏层(64节点)的连接 model.add(Activation(\'tanh\')) #第一隐藏层用tanh作为激活函数 model.add(Dropout(0.5)) #使用Dropout防止过拟合 model.add(Dense(64,input_dim=64, init=\'uniform\')) #添加第一隐藏层(64节点)、第二隐藏层(64节点)的连接 model.add(Activation(\'tanh\')) #第二隐藏层用tanh作为激活函数 model.add(Dropout(0.5)) model.add(Dense(1,input_dim=64)) #添加第二隐藏层(64节点)、输出层(1节点)的连接 model.add(Activation(\'sigmoid\')) #输出层用sigmoid作为激活函数 sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) #定义求解算法 model.compile(loss=\'mean_squared_error\', optimizer=sgd) #编译生成模型,损失函数为mean_squared_error model.fit(X_train, y_train, nb_epoch=20, batch_size=16) #训练模型 score=model.evaluate(X_test,y_test,batch_size=16) #测试模型
以上是关于[Python数据挖掘]第2章Python数据分析简介的主要内容,如果未能解决你的问题,请参考以下文章