SpringBoot-0.0.1-SNAPSHOT.jar中没有主清单属性
Posted 热爱学习的好孩子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBoot-0.0.1-SNAPSHOT.jar中没有主清单属性相关的知识,希望对你有一定的参考价值。
Maven 工程 java -jar 时提示 xxx-SNAPSHOT.jar 中没有主清单属性
issue
启动 jar 包命令:
java -jar xxx.jar
 .
.
SpringBoot-0.0.1-SNAPSHOT.jar 中没有主清单属性
resolve
<skip> 标签的问题❗❗❗
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.rnny</groupId>
<artifactId>SpringBoot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringBoot</name>
<description>SpringBoot</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>8</source>
<target>8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>$spring-boot.version</version>
<configuration>
<mainClass>com.rnny.Application</mainClass>
<!--
issue:SpringBoot-0.0.1-SNAPSHOT.jar 中没有主清单属性
resolve:① 注释掉,或者 ② 将 skip 值改为 false
-->
<!--<skip>true</skip>-->
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
扩展知识
maven plugin 中 configuration 的 skip 标签
<skip>true</skip>:
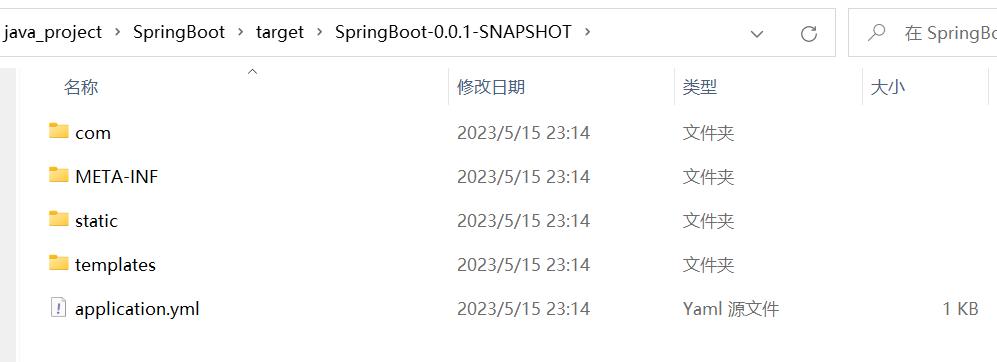 .
.
<skip>false</skip>:
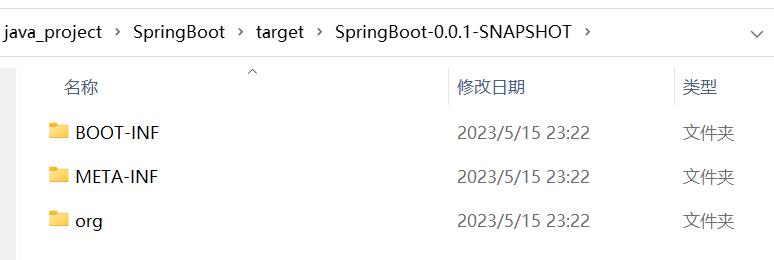 .
.
Kafka 消息丢失与消费精确一次性
消息丢失的场景
如果Kafka Producer使用“发后即忘”的方式发送消息,即调用producer.send(msg)方法来发送消息,方法会立即返回,但此时并不能说明消息已经发送成功。消息发送方式详见初次邂逅Kafka生产者。
如果在消息过程中发生了网络抖动,那么消息就会丢失;或发送的消息本身不符合要求,如大小超过Broker端的承受能力等(消息太大的情况在生产中实际遇到过,最后通过在发送前将消息分包,再依次发送,解决了该问题)。
解决该问题的方法就是:Producer要使用带回调通知的方法发送消息,即producer.send(msg, callback)。回调方法callback可以告诉我们消息是否真的提交成功了,一旦出现消息发送失败的情况,可以使用代码进行容错及补救。
例如:网络抖动导致的消息丢失,可以使Producer重试;消息不合格,则将消息格式进行调整,再发送。Producer使用带回调的消息发送API,可以及时发现消息是否发送失败并作相应处理。
消费者丢失数据
Consumer端丢失数据主要体现在:拉取了消息,并提交了消费位移,但是在消息处理结束之前突然发生了宕机等故障。消费者重生后,会从之前已提交的位移的下一个位置重新开始消费,之前未处理完成的消息不会再次处理,即相当于消费者丢失了消息。
解决Consumer端丢失消息的方法也很简单:将位移提交的时机改为消息处理完成后,确认消费完成了一批消息再提交相应的位移。这样做,即使处理消息的过程中发生了异常,由于没有提交位移,下次消费时还会从上次的位移处重新拉取消息,不会发生消息丢失的情况。
具体的实现方法为,Consumer在消费消息时,关闭自动提交位移,由应用程序手动提交位移。
Broker端丢失数据
Broker端丢失数据主要有以下几种情况:
原来的Broker宕机了,却选举了一个落后Leader太多的Broker成为新的Leader,那么落后的这些消息就都丢失了,可以禁止这些“unclean”的Broker竞选成为Leader;
Kafka使用页缓存机制,将消息写入页缓存而非直接持久化至磁盘,将刷盘工作交由操作系统来调度,以此来保证高效率和高吞吐量。如果某一部分消息还在内存页中,未持久化至磁盘,此时Broker宕机,重启后则这部分消息丢失,使用多副本机制可以避免Broker端丢失消息;
避免消息丢失的最佳实践
不使用producer.send(msg),而使用带回调的producer.send(msg, callback)方法;
设置acks = all。acks参数是Producer的一个参数,代表了对消息“已提交”的定义。如果设置成all,则表示所有的Broker副本都要接收到消息,才算消息“已提交”,是最高等级的“已提交”标准;
设置retries为一个较大的值,retries表示Producer发送消息失败后的重试次数,如果发生了网络抖动等瞬时故障,可以通过重试机制重新发送消息,避免消息丢失;
设置unclean.leader.election.enable = false。这是一个Broker端参数,表示哪些Broker有资格竞选为分区的Leader。如果一个落后Leader太多的Follower所在Broker成为了新的Leader,则必然会导致消息的丢失,故将该参数设置为false,即不允许这种情况的发生;
设置replication.factor >= 3。Broker端参数,表示每个分区的副本数大于等于3,使用冗余的机制来防止消息丢失;
设置min.insync.replicas > 1。Broker端参数,控制的是消息至少被写入多少个副本蔡栓是“已提交”,将该参数设置成大于1可以提升消息持久性;
确保replication.factor > min.insync.replicas。若两者相等,则如果有一个副本挂了,整个分区就无法正常工作了。推荐设置为:replication.factor = min.insync.replicas + 1;
确保消息消费完再提交位移,将Consumer端参数enable.auto.commit设置为fasle,关闭位移自动提交,使用手动提交位移的形式。
精确一次消费
目前Kafka默认提供的消息可靠机制是“至少一次”,即消息不会丢失。上一节中我们知道,Producer如果发送消息失败,则可以通过重试解决,若Broker端的应答未成功发送给Producer(如网络抖动),Producer此时也会进行重试,再次发送原来的消息。这就是Kafka默认提供消息至少一次性的原因,不过这可能会导致消息重复发送。
如果需要保证消息消费的“最多一次”,那么禁止Producer的重试即可。但是写入失败的消息如果不重试则会永远丢失。是否有其他方法来保证消息的发送既不丢失,也不重复消费?或者说即使Producer重复发送了某些消息,Broker端也能够自动去重。
Kafka实际上通过两种机制来确保消息消费的精确一次:
幂等性(Idempotence)
事务(Transaction)
幂等性
所谓的幂等,简单说就是对接口的多次调用所产生的结果和调用一次是一致的。在Kafka中,Producer默认不是幂等性的,Kafka于0.11.0.0版本引入该特性。设置参数enable.idempotence为true即可指定Producer的幂等性。开启幂等生产者后,Kafka会自动进行消息的去重发送。为了实现生产者的幂等性,Kafka引入了producer id(后简称PID)和序列号(sequence number)两个概念。
生产者实例在被创建的时候,会分配一个PID,这个PID对用户完全透明。对于每个PID,消息发送到的每一个分区都有对应的序列号,这些序列号从0开始单调递增。生产者每发送一条消息就会将**<PID, 分区>**对应的序列号值加1。
Broker端在内存中为每一对<PID, 分区>维护一个序列号SN_old。针对生产者发送来的每一条消息,对其序列号SN_new进行判断,并作相应处理。
只有SN_new比SN_old大1时,即SN_new = SN_old + 1时,broker才会接受这条消息;
SN_new < SN_old + 1,说明消息被重复写入,broker直接丢弃该条消息;
SN_new > SN_old + 1,说明中间有数据尚未写入,出现了消息乱序,可能存在消息丢失的现象,对应的生产者会抛出OutOfOrderSequenceException。
注意:序列号针对<PID, 分区>,这意味着幂等生产者只能保证单个主题的单一分区内消息不重复;其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性,这里的会话即可以理解为:Producer进程的一次运行。当重启了Producer进程之后,则幂等性保证就失效了。
事务
幂等性并不能跨多个分区运作,而Kafka事务则可以弥补这个缺陷。Kafka从0.11版本开始提供了对事务的支持,主要在read committed隔离级别。它能保证多条消息原子性地写入到目标分区,同时也能宝恒Consumer只能看到事务成功提交的消息。
Producer端配置
事务型Producer能保证消息原子性地写入多个分区。批量的消息要么全部写入成功,要么全部失败。并且,事务型Producer在重启后,Kafka依然保证它们发送消息的精确一次处理。开启事务型Producer的配置如下:
和幂等性Producer一样,开启enable.idempotence = true。
设置Producer端参数transcational.id。最好为其设置一个有意义的名字。
设置了事务型的Producer可以调用一些事务API,如下:initTransaction、beginTransaction、commitTransaction和abortTransaction,分别对应事务的初始化、事务开启、事务提交和事务终止。
producer.initTransactions(); try { producer.beginTransaction(); producer.send(record1); producer.send(record2); producer.commitTransaction(); } catch (KafkaExecption e) { producer.abortTransaction(); }
上述代码中,事务型Producer可以保证record1和record2要么全部提交成功,要么全部写入失败。实际上,即使写入失败,Kafka也会将它们写入到底层的日志中,也就是说Consumer还是会看到这些消息,具体Consumer端读取事务型Producer发送的消息需要另行配置。
Consumer端配置
读取事务型Producer发送的消息时,Consumer端的isolation.level参数表征着事务的隔离级别,即决定了Consumer以怎样的级别去读取消息。该参数有以下两个取值: read_uncommitted:默认值,表面Consumer能够读到Kafka写入的任何消息,不论事务型Producer是否正常提交了事务。显然,如果启用了事务型的Producer,则Consumer端参数就不要使用该值,否则事务是无效的。 read_committed:表面Consumer只会读取事务型Producer成功提交的事务中写入的消息,同时,非事务型Producer写入的所有消息对Consumer也是可见的。
总结
Kafka所提供的消息精确一次消费的手段有两个:幂等性Producer和事务型Producer。 幂等性Producer只能保证单会话、单分区上的消息幂等性; 事务型Producer可以保证跨分区、跨会话间的幂等性; 事务型Producer功能更为强大,但是同时,其效率也会比较低下。
本文来源于:
以上是关于SpringBoot-0.0.1-SNAPSHOT.jar中没有主清单属性的主要内容,如果未能解决你的问题,请参考以下文章