Python数据挖掘课程九.回归模型LinearRegression简单分析氧化物数据
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据挖掘课程九.回归模型LinearRegression简单分析氧化物数据相关的知识,希望对你有一定的参考价值。
这篇文章主要介绍三个知识点,也是我《数据挖掘与分析》课程讲课的内容。同时主要参考学生的课程提交作业内容进行讲述,包括:
1.回归模型及基础知识;
2.UCI数据集;
3.回归模型简单数据分析。
该系列github完整代码地址,欢迎点Star,谢谢!支持Python3.x~
- https://github.com/eastmountyxz/Python-for-Data-Mining
前文推荐:
【Python数据挖掘课程】一.安装Python及爬虫入门介绍
【Python数据挖掘课程】二.Kmeans聚类数据分析及Anaconda介绍
【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化
【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析
【Python数据挖掘课程】五.线性回归知识及预测糖尿病实例
【Python数据挖掘课程】六.Numpy、Pandas和Matplotlib包基础知识
【Python数据挖掘课程】七.PCA降维操作及subplot子图绘制
【Python数据挖掘课程】八.关联规则挖掘及Apriori实现购物推荐
希望这篇文章对你有所帮助,尤其是刚刚接触数据挖掘以及大数据的同学,这些基础知识真的非常重要。如果文章中存在不足或错误的地方,还请海涵~
感谢ZJ学生提供的数据集与作品相关报告,学生确实还是学到了些东西。
授课知识强推第五节课内容:五.线性回归知识及预测糖尿病实例
一. 算法简介-回归模型
1.初识回归
“子女的身高趋向于高于父母的身高的平均值,但一般不会超过父母的身高。”
-- 《遗传的身高向平均数方向的回归》
回归(Regression)这一概念最早由英国生物统计学家高尔顿和他的学生皮尔逊在研究父母亲和子女的身高遗传特性时提出。如今,我们做回归分析时所讨论的“回归”和这种趋势中效应已经没有任何瓜葛了,它只是指源于高尔顿工作的那样——用一个或多个自变量来预测因变量的数学方法。
在一个回归模型中,我们需要关注或预测的变量叫做因变量(响应变量或结果变量),我们选取的用来解释因变量变化的变量叫做自变量(解释变量或预测变量)。
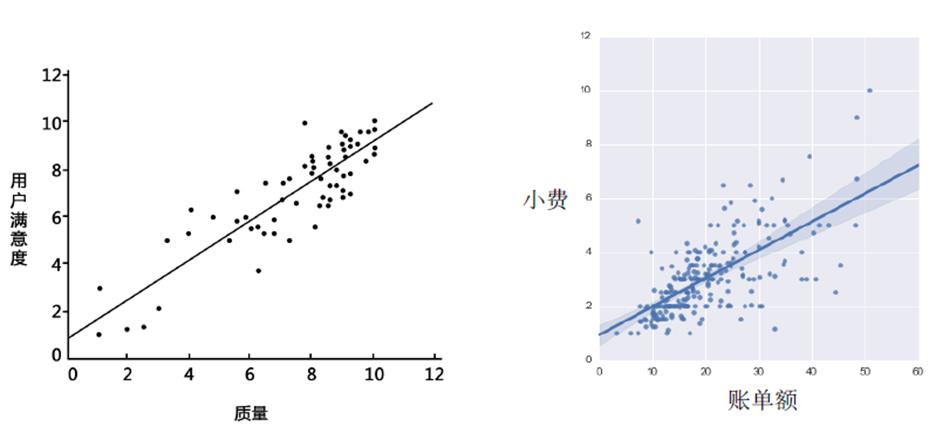
回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。
分类算法用于离散型分布预测,如KNN、决策树、朴素贝叶斯、adaboost、SVM、Logistic回归都是分类算法;回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
回归的目的就是建立一个回归方程用来预测目标值,回归的求解就是求这个回归方程的回归系数。预测的方法即回归系数乘以输入值再全部相加就得到了预测值。
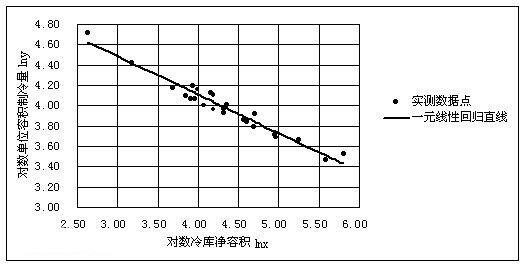
以上是关于Python数据挖掘课程九.回归模型LinearRegression简单分析氧化物数据的主要内容,如果未能解决你的问题,请参考以下文章