问鼎CodeXGLUE榜单,华为云UniXcoder-VESO-v1算法取得突破
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了问鼎CodeXGLUE榜单,华为云UniXcoder-VESO-v1算法取得突破相关的知识,希望对你有一定的参考价值。
摘要:华为云PaaS技术创新团队基于UniXcoder模型,在公开测试数据集(CodeXGLUE)上的代码搜索任务评测结果上取得突破,在CodeXGLUE榜单上排名中第一。
本文分享自华为云社区《代码语义搜索算法哪家强?华为云UniXcoder-VESO-v1算法取得突破,问鼎CodeXGLUE榜单第一名》,作者:华为云软件分析Lab 。
按照查询语句的类型,代码搜索可以分为代码关键字搜索和代码语义搜索。代码关键字搜索主要通过索引代码实体(如类、方法、变量等),查询定位代码实体的定义及引用;代码语义搜索的目标是支持开发人员基于自然语言方式来描述代码特性,从而进行相关代码的推荐与搜索。在开发人员编程过程中帮助其查找最佳代码示例实践和库使用示例,从而开发者可以通过功能描述搜索到代码。
目前,大多数代码搜索引擎仅支持代码关键字搜索,这需要开发者了解他们正在搜索的代码,例如类名、函数名、API调用等等,这具有很大的局限性。多数用户通常通过搜索代码示例来指导他们完成特定的编码任务,他们更倾向于使用自然语言来描述待编码实现的功能,从而借鉴开源社区中已存在的相关代码片段。代码语义搜索可以支持开发人员在不知道类或函数名称的情况下使用自然语言方式来描述所需的代码功能。借助于语言模型及不同自然语言之间的映射关系,开发者甚至可以基于中文描述搜索出包含英文功能描述的代码片段。
随着语言大模型(Large Language Model, LLM)技术的发展,一系列语言大模型(如BERT [1]、XLNet [2]、GPT [3]、RoBERTa [4]等)在自然语言处理任务上取得了巨大的成功,为源代码处理任务提供了技术基础。这些模型已经应用于代码摘要和代码语义搜索,打败了以前的最先进方法。语义搜索背后的想法是将语料库中的所有条目,无论是句子、段落还是文档,都编码到向量空间中。在搜索时,查询被编码到相同的向量空间中,并找到语料库中最近的向量。这些条目应与查询具有高度的语义重叠。代码语义搜索使用编码大模型将查询及代码片段编码成向量,使得语义相关或相近的代码片段和查询在向量空间内落在相近的位置。如下图所示:
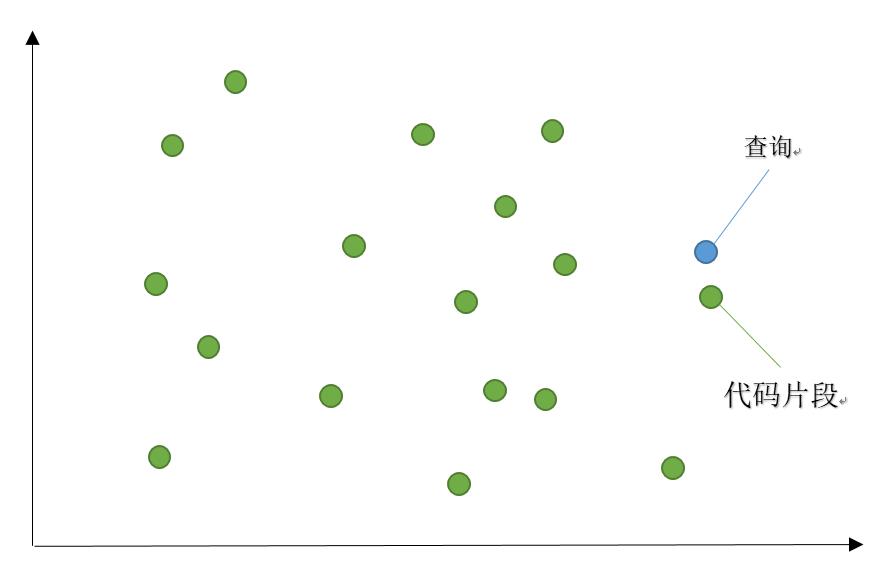
有很多算法使用不同的编码器对代码片段和查询进行编码,最新和最有希望的研究集中在通用编码器和解码器上,这些编码器和解码器使用相同的神经网络来编码所有编程语言代码片段和文本。
Salza等人 [5]基于原始BERT[1]模型,用多种编程语言代码预训练一个新的BERT模型,并用两个编码器(一个处理自然语言,另一个处理代码片段)精调该模型,首先证明了处理自然语言的基于Transformer架构的模型可以被直接应用到代码搜索任务中。
CodeBERT [6]是在自然语言和编程语言序列数据上进行训练的大型语言模型之一,它在代码搜索方面表现较为出色。此外,还发展演化出RoBERTa [4]、TreeBERT [7]、GraphCodeBERT [8]、UniXcoder [9]等在代码搜索方面表现出色的自然语言与编程语言结合训练的模型。
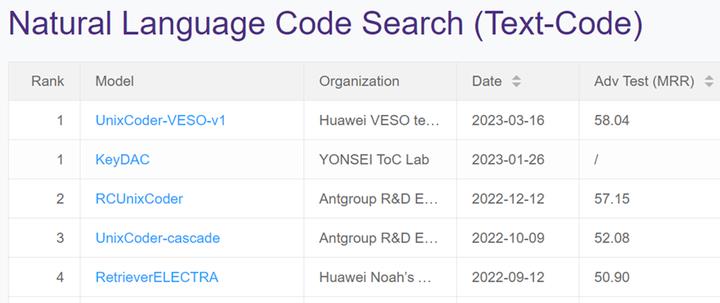
华为云PaaS技术创新团队基于UniXcoder模型,通过混淆代码片段、增加海量开源代码作为训练集、提高批尺寸等精调方法,实现了UniXcoder-VESO-v1算法,该算法在公开测试数据集(CodeXGLUE [10])上的代码搜索任务评测结果上取得突破:平均倒数排序值(MRR)达到0.58,CodeXGLUE榜单上排名中第一(如下图所示: UniXcoder-VESO-v1, 详见https://microsoft.github.io/CodeXGLUE/)。 我们将持续推进该工作的技术创新与突破,会选择合适方式披露内部技术细节,如感兴趣,欢迎持续关注我们的订阅号文章。
文章来自:PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!(详情欢迎联系 mayuchi1@huawei.com;guodongshuo@huawei.com)
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
参考文献
- [1]. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1) 2019: 4171-4186
- [2]. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, Quoc V. Le: XLNet: Generalized Autoregressive Pretraining for Language Understanding. NeurIPS 2019: 5754-5764
- [3]. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei: Language Models are Few-Shot Learners. NeurIPS 2020
- [4]. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov: RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
- [5]. Pasquale Salza, Christoph Schwizer, Jian Gu, Harald C. Gall: On the Effectiveness of Transfer Learning for Code Search. IEEE Trans. Software Eng. 49(4): 1804-1822 (2023)
- [6]. Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, Ming Zhou: CodeBERT: A Pre-Trained Model for Programming and Natural Languages. EMNLP (Findings) 2020: 1536-1547
- [7]. Xue Jiang, Zhuoran Zheng, Chen Lyu, Liang Li, Lei Lyu: TreeBERT: A tree-based pre-trained model for programming language. UAI 2021: 54-63
- [8]. Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin B. Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, Ming Zhou: GraphCodeBERT: Pre-training Code Representations with Data Flow. ICLR 2021
- [9]. Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, Jian Yin: UniXcoder: Unified Cross-Modal Pre-training for Code Representation. ACL (1) 2022: 7212-7225
- [10]. https://microsoft.github.io/CodeXGLUE/
世界第一!华为云EI问鼎国际图像识别领域“世界杯




WebVision 竞赛由苏黎世联邦理工(ETH)、Google Research、卡耐基梅隆大学(CMU)等共同组织,是目前图像识别领域最权威的竞赛之一,被业界誉为人工智能“世界杯”, 接棒曾经推动计算机物体分类准确率超过人类的ImageNet 竞赛。
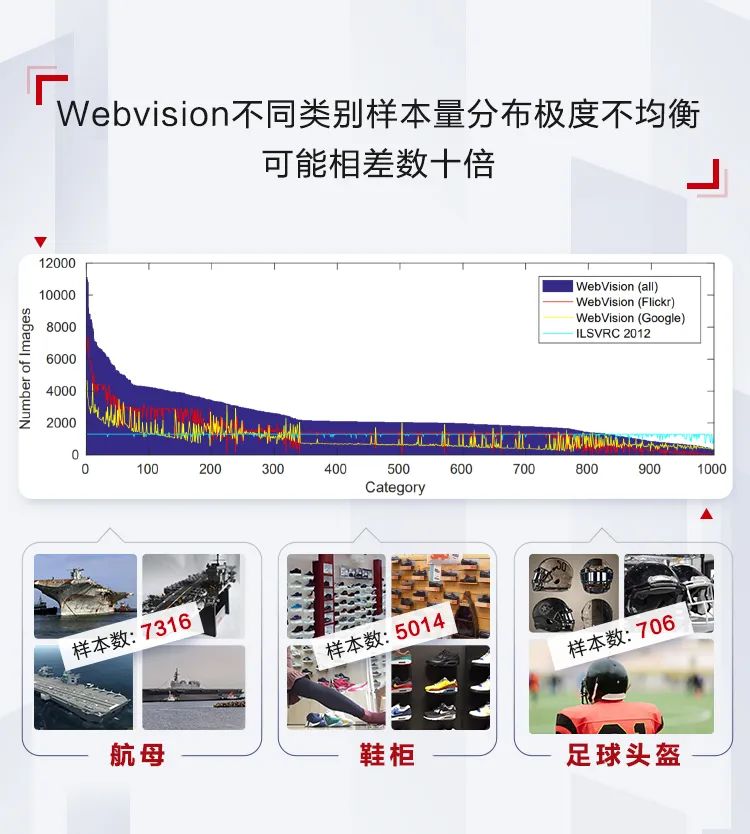
竞赛中,参赛选手通过AI模型将1600万+张图片精准分类到5000个类目中,其所用数据集直接从互联网爬取,没有经过人工标注,因此数据中含有很多噪音,且数据类别的数量存在着极大不平衡。
此项竞赛相较于 ImageNet,WebVision 难度提高许多,同时也更加贴近于实际应用中的场景。
WebVision竞赛展示了另外一种可能性:基于弱监督学习,深度学习可以不再以人工标注数据为基础,人工智能有望真正摆脱“人工”。

华为云EI在本次比赛中运用的图像识别技术,可广泛用于通用物品识别、图像/视频标签等领域。
近十年来计算机视觉取得的进展离不开大量人工标注的数据集,但由于人工标注需要较高的成本,几乎不太可能构建包罗万象的超级数据集。

互联网上存在几乎取之不尽的无标注图像数据,利用这些数据的周边文本等信息作为带噪声的弱标注数据进行学习,能够在很大程度上降低图像识别对人工标注的依赖。
华为云EI在视觉研究领域有着丰富的技术积累,在6月14日-19日举办的CVPR2020(国际计算机视觉和模式识别大会)中,华为贡献论文34 篇,涵盖迁移学习、半监督学习、网络架构搜索、模型算子优化、知识蒸馏、对抗样本生成等前沿领域。
2019年,基于华为云图像识别能力,在上海天文台与国际组织SKA(平方公里阵列射电望远镜) 合作的项目中,科学家们仅用10.02 秒即完成了对 20 万颗星体的识别,同时可以准确地对某一类星体进行定位,而传统方式完成如此大量的星体识别工作需要 169 天时间。

目前,华为云EI内容审核、人脸识别、图像搜索、视频分析等服务已经成功应用于互联网、媒资、园区、物流、工业等行业。
-END-

点击“阅读原文”,立即了解华为云
以上是关于问鼎CodeXGLUE榜单,华为云UniXcoder-VESO-v1算法取得突破的主要内容,如果未能解决你的问题,请参考以下文章
容联云AI科学院研发先进KBQA能力,问鼎大规模中文知识图谱问答权威性测评
网易云信获计算机视觉国际权威赛事冠军,超分辨率技术性能问鼎全球
容联云AI问鼎“千言数据集—实体链指评测“,持续打造知识语义计算能力