python之Beautiful Soup库
Posted Fate0729
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之Beautiful Soup库相关的知识,希望对你有一定的参考价值。
1、简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
2、环境安装
Beautiful Soup 3 目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 from bs4 import BeautifulSoup 。所以这里我们用的版本是 Beautiful Soup 4.3.2 (简称BS4)。
1、快速安装
|
1
|
pip install beautifulsoup4 |
2、如果想安装最新的版本,请直接下载安装包来手动安装,也是十分方便的方法
1、Beautiful Soup3.2.1
https://pypi.python.org/pypi/BeautifulSoup/3.2.1
2、Beautiful Soup4.3.2
https://pypi.python.org/pypi/beautifulsoup4/
下载完成之后解压
运行下面的命令即可完成安装
python setup.py install
3、然后需要安装 lxml
pip install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
pip install html5lib
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
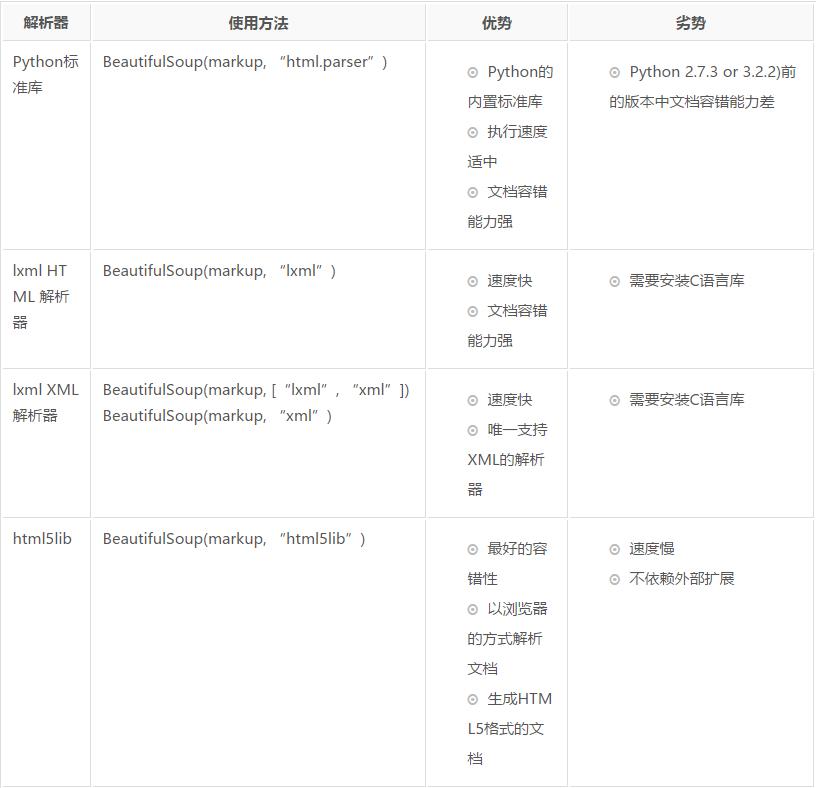
3. 使用方法
最佳方法参考官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
以下内容测试css和xpath分别提取文本和属性的区别,方便后续查看
from scrapy.selector import Selector from scrapy.http import HtmlResponse from bs4 import BeautifulSoup as bs body = \'\'\'<html> <head> <base href=\'http://example.com/\' /> <title id="txt">Example website</title> </head> <body> <div id=\'images\'> <a href=\'image1.html\'>Name: My image 1 <br /><img src=\'image1_thumb.jpg\' /></a> <a href=\'image2.html\'>Name: My image 2 <br /><img src=\'image2_thumb.jpg\' /></a> <a href=\'image3.html\'>Name: My image 3 <br /><img src=\'image3_thumb.jpg\' /></a> <a href=\'image4.html\'>Name: My image 4 <br /><img src=\'image4_thumb.jpg\' /></a> <a href=\'image5.html\'>Name: My image 5 <br /><img src=\'image5_thumb.jpg\' /></a>"div text"</div> <div>helloworld test</div> </body> </html>\'\'\' soup = bs(body, "lxml") print("css获取属性:",soup.select("div")[0].attrs["id"]) print("xpath获取属性:",Selector(text=body).xpath("//div/@id").extract()[0]) print("css获取文本:", soup.select("title[id=\'txt\']")[0].string) print("xpath获取文本:",Selector(text=body).xpath("//title[@id=\'txt\']/text()").extract()[0])
以上是关于python之Beautiful Soup库的主要内容,如果未能解决你的问题,请参考以下文章