读SQL进阶教程笔记16_SQL优化让SQL飞起来
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记16_SQL优化让SQL飞起来相关的知识,希望对你有一定的参考价值。
1. 查询速度慢并不只是因为SQL语句本身,还可能是因为内存分配不佳、文件结构不合理等其他原因
1.1. 都是为了减少对硬盘的访问
2. 不同代码能够得出相同结果
2.1. 从理论上来说,得到相同结果的不同代码应该有相同的性能
2.2. 遗憾的是,查询优化器生成的执行计划很大程度上要受到代码外部结构的影响
2.3. 如果想优化查询性能,必须知道如何写代码才能使优化器的执行效率更高
3. 使用高效的查询
3.1. 参数是子查询时,使用EXISTS代替IN
3.1.1. IN谓词却有成为性能优化的瓶颈的危险
3.1.1.1. 当IN的参数是子查询时,数据库首先会执行子查询,然后将结果存储在一张临时的工作表里(内联视图),然后扫描整个视图
3.1.1.2. 从代码的可读性上来看,IN要比EXISTS好
3.1.2. 示例
3.1.2.1.
--慢
SELECT *
FROM Class_A
WHERE id IN (SELECT id
FROM Class_B);
--快
SELECT *
FROM Class_A A
WHERE EXISTS
(SELECT *
FROM Class_B B
WHERE A.id = B.id);
3.1.2.1.1. 如果连接列(id)上建立了索引,那么查询Class_B时不用查实际的表,只需查索引就可以了
3.1.2.1.2. 如果使用EXISTS,那么只要查到一行数据满足条件就会终止查询,不用像使用IN时一样扫描全表
3.1.2.1.2.1. 在这一点上NOT EXISTS也一样
3.1.2.1.3. 使用EXISTS的话,数据库不会生成临时的工作表
3.2. 参数是子查询时,使用连接代替IN
3.2.1. 示例
3.2.1.1. --使用连接代替IN
SELECT A.id, A.name
FROM Class_A A INNER JOIN Class_B B
ON A.id = B.id;
3.2.1.1.1. 至少能用到一张表的“id”列上的索引
3.2.1.1.2. 没有了子查询,所以数据库也不会生成中间表
3.2.1.1.3. 如果没有索引,那么与连接相比,可能EXISTS会略胜一筹
4. 避免排序
4.1. 在SQL语言中,用户不能显式地命令数据库进行排序操作
4.2. 对用户隐藏这样的操作正是SQL的设计思想
4.3. 在数据库内部频繁地进行着暗中的排序
4.3.1. 会进行排序的代表性的运算
4.3.1.1. GROUP BY子句
4.3.1.2. ORDER BY子句
4.3.1.3. 聚合函数(SUM、COUNT、AVG、MAX、MIN)
4.3.1.4. DISTINCT
4.3.1.5. 集合运算符(UNION、INTERSECT、EXCEPT)
4.3.1.6. 窗口函数(RANK、ROW_NUMBER等)
4.4. 灵活使用集合运算符的ALL可选项
4.4.1. 如果不在乎结果中是否有重复数据,或者事先知道不会有重复数据,请使用UNION ALL代替UNION
4.4.2. 加上ALL可选项是优化性能的一个非常有效的手段
4.4.3. 对于INTERSECT和EXCEPT也是一样的,加上ALL可选项后就不会进行排序了
4.5. 使用EXISTS代替DISTINCT
4.5.1. 为了排除重复数据,DISTINCT也会进行排序
4.5.1.1.
SELECT I.item_no
FROM Items I INNER JOIN SalesHistory SH
ON I. item_no = SH. item_no;
4.5.1.2.
SELECT DISTINCT I.item_no
FROM Items I INNER JOIN SalesHistory SH
ON I. item_no = SH. item_no;
4.5.1.3.
SELECT item_no
FROM Items I
WHERE EXISTS
(SELECT *
FROM SalesHistory SH
WHERE I.item_no = SH.item_no);
4.6. 在极值函数中使用索引(MAX/MIN)
4.6.1. 使用这两个函数时都会进行排序
4.6.1.1. --这样写需要扫描全表
SELECT MAX(item)
FROM Items;
4.6.2. 如果参数字段上建有索引,则只需要扫描索引,不需要扫描整张表
4.6.2.1. --这样写能用到索引
SELECT MAX(item_no)
FROM Items;
4.6.3. 对于联合索引,只要查询条件是联合索引的第一个字段,索引就是有效的
4.6.4. 这种方法并不是去掉了排序这一过程,而是优化了排序前的查找速度,从而减弱排序对整体性能的影响
4.7. 能写在WHERE子句里的条件不要写在HAVING子句里
4.7.1. --聚合后使用HAVING子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING sale_date = \'2007-10-01\';
4.7.2. --聚合前使用WHERE子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory
WHERE sale_date = \'2007-10-01\'
GROUP BY sale_date;
4.7.2.1. 在使用GROUP BY子句聚合时会进行排序,如果事先通过WHERE子句筛选出一部分行,就能够减轻排序的负担
4.7.2.2. 第二个是在WHERE子句的条件里可以使用索引。HAVING子句是针对聚合后生成的视图进行筛选的,但是很多时候聚合后的视图都没有继承原表的索引结构
4.8. 在GROUP BY子句和ORDER BY子句中使用索引
4.8.1. 通过指定带索引的列作为GROUP BY和ORDER BY的列,可以实现高速查询
4.8.2. 在一些数据库中,如果操作对象的列上建立的是唯一索引,那么排序过程本身都会被省略掉
5. 真正用到索引!
5.1. 在索引字段上进行运算
5.1.1.
SELECT *
FROM SomeTable
WHERE col_1 * 1.1 > 100;
5.2. 把运算的表达式放到查询条件的右侧,就能用到索引了
5.2.1. WHERE col_1 > 100 / 1.1
5.3. 在查询条件的左侧使用函数时,也不能用到索引
5.3.1.
SELECT *
FROM SomeTable
WHERE SUBSTR(col_1, 1, 1) = \'a\';
5.4. 如果无法避免在左侧进行运算,那么使用函数索引也是一种办法
5.5. 使用索引时,条件表达式的左侧应该是原始字段
5.6. 使用IS NULL谓词
5.6.1. 索引字段是不存在NULL的,所以指定IS NULL和IS NOT NULL的话会使得索引无法使用,进而导致查询性能低下
5.6.1.1.
SELECT *
FROM SomeTable
WHERE col_1 IS NULL;
5.6.1.2. --IS NOT NULL的代替方案
SELECT *
FROM SomeTable
WHERE col_1 > 0;
5.6.1.2.1. 如果要选择“非NULL的行”,正确的做法还是使用IS NOT NULL
5.7. 使用否定形式
5.7.1. 否定形式不能用到索引
5.7.1.1. <>
5.7.1.2. ! =
5.7.1.3. NOT IN
5.8. 使用OR
5.8.1. 在col_1和col_2上分别建立了不同的索引,或者建立了(col_1, col_2)这样的联合索引时,如果使用OR连接条件,那么要么用不到索引,要么用到了但是效率比AND要差很多
5.8.2. 如果无论如何都要使用OR,那么有一种办法是位图索引。但是这种索引的话更新数据时的性能开销会增大
5.9. 使用联合索引时,列的顺序错误
5.9.1. 假设存在这样顺序的一个联合索引“col_1, col_2, col_3”
5.9.2.
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 AND col_3 = 500;
○ SELECT * FROM SomeTable WHERE col_1 = 10 AND col_2 = 100 ;
× SELECT * FROM SomeTable WHERE col_1 = 10 AND col_3 = 500 ;
× SELECT * FROM SomeTable WHERE col_2 = 100 AND col_3 = 500 ;
× SELECT * FROM SomeTable WHERE col_2 = 100 AND col_1 = 10 ;
5.9.3. 联合索引中的第一列(col_1)必须写在查询条件的开头,而且索引中列的顺序不能颠倒
5.9.4. 有些数据库里顺序颠倒后也能使用索引,但是性能还是比顺序正确时差一些
5.9.5. 如果无法保证查询条件里列的顺序与索引一致,可以考虑将联合索引拆分为多个索引
5.10. 使用LIKE谓词进行后方一致或中间一致的匹配
5.10.1. 只有前方一致的匹配才能用到索引
5.10.2.
× SELECT * FROM SomeTable WHERE col_1 LIKE \'%a\';
× SELECT * FROM SomeTable WHERE col_1 LIKE \'%a%\';
○ SELECT * FROM SomeTable WHERE col_1 LIKE \'a%\';
5.11. 进行默认的类型转换
5.11.1. 默认的类型转换不仅会增加额外的性能开销,还会导致索引不可用
5.11.2. 在需要类型转换时显式地进行类型转换
6. 减少中间表
6.1. 子查询的结果会被看成一张新表,这张新表与原始表一样,可以通过代码进行操作
6.2. 灵活使用HAVING子句
6.2.1. 对聚合结果指定筛选条件时不需要专门生成中间表
6.2.2.
SELECT sale_date, MAX(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;
6.2.3. HAVING子句和聚合操作是同时执行的,所以比起生成中间表后再执行的WHERE子句,效率会更高一些,而且代码看起来也更简洁
6.3. 需要对多个字段使用IN谓词时,将它们汇总到一处
6.3.1.
SELECT id, state, city
FROM Addresses1 A1
WHERE state IN (SELECT state
FROM Addresses2 A2
WHERE A1.id = A2.id)
AND city IN (SELECT city
FROM Addresses2 A2
WHERE A1.id = A2.id);
6.3.2.
SELECT *
FROM Addresses1 A1
WHERE id || state || city
IN (SELECT id || state|| city
FROM Addresses2 A2);
6.3.2.1. 子查询不用考虑关联性,而且只执行一次就可以
6.3.3.
SELECT *
FROM Addresses1 A1
WHERE (id, state, city)
IN (SELECT id, state, city
FROM Addresses2 A2);
6.3.3.1. 不用担心连接字段时出现的类型转换问题
6.3.3.2. 不会对字段进行加工,因此可以使用索引
6.4. 先进行连接再进行聚合
6.4.1. 连接和聚合同时使用时,先进行连接操作可以避免产生中间表
6.4.1.1. 连接做的是“乘法运算”
6.4.1.2. 连接表双方是一对一、一对多的关系时,连接运算后数据的行数不会增加
6.5. 合理地使用视图
6.5.1. 特别是视图的定义语句中包含以下运算的时候,SQL会非常低效,执行速度也会变得非常慢
6.5.1.1. 聚合函数(AVG、COUNT、SUM、MIN、MAX)
6.5.1.2. 集合运算符(UNION、INTERSECT、EXCEPT等)
6.5.2. 物化视图(materialized view)等技术。当视图的定义变得复杂时,可以考虑使用一下
读SQL进阶教程笔记06_外连接

1. SQL的弱点
1.1. SQL语句的执行结果转换为想要的格式
-
1.1.1. 格式转换
-
1.1.2. SQL语言本来就不是为了这个目的而出现的
-
1.1.3. SQL终究也只是主要用于查询数据的语言而已
1.2. 生成报表的功能
- 1.2.1. 窗口函数
1.3. SQL不是用来生成报表的语言,所以不建议用它来进行格式转换
- 1.3.1. 必要时考虑用外连接或CASE表达式来解决问题
2. 制作交叉表(行→列)
2.1. 示例
- 2.1.1.
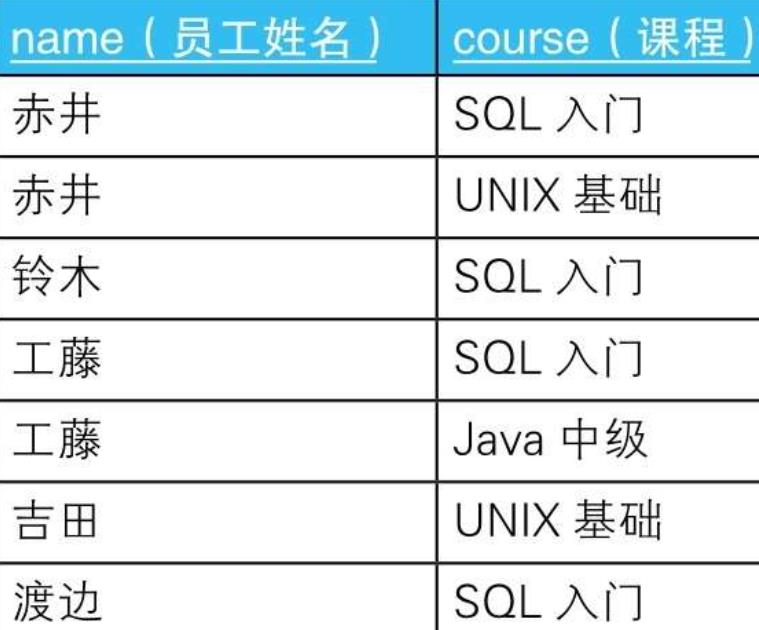
- 2.1.1.1. --水平展开求交叉表(1):使用外连接
SELECT C0.name,
CASE WHEN C1.name IS NOT NULL THEN\'○\'ELSE NULL END AS "SQL入门",
CASE WHEN C2.name IS NOT NULL THEN\'○\'ELSE NULL END AS "UNIX基础",
CASE WHEN C3.name IS NOT NULL THEN\'○\'ELSE NULL END AS "Java中级"
FROM (SELECT DISTINCT name FROM Courses) C0 --这里的C0是侧栏
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'SQL入门’) C1
ON C0.name = C1.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'UNIX基础’) C2
ON C0.name = C2.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'Java中级’) C3
ON C0.name = C3.name;
-
2.1.1.2. 一般情况下,外连接都可以用标量子查询替代
2.1.1.2.1. 需要增加或者减少课程时,只修改SELECT子句即可,代码修改起来比较简单
2.1.1.2.2. 利于应对需求变更,对于需要动态生成SQL的系统也是很有好处的
2.1.1.2.3. 性能不太好
-
2.1.1.3. --水平展开(2):使用标量子查询
SELECT C0.name,
(SELECT \'○\'
FROM Courses C1
WHERE course = \'SQL入门’
AND C1.name = C0.name) AS "SQL入门",
(SELECT \'○\'
FROM Courses C2
WHERE course = \'UNIX基础’
AND C2.name = C0.name) AS "UNIX基础",
(SELECT \'○\'
FROM Courses C3
WHERE course = \'Java中级’
AND C3.name = C0.name) AS "Java中级"
FROM (SELECT DISTINCT name FROM Courses) C0; --这里的C0是表侧栏
-
2.1.1.4. 嵌套使用CASE表达式
2.1.1.4.1. CASE表达式可以写在SELECT子句里的聚合函数内部,也可以写在聚合函数外部
2.1.1.4.2. 其实在SELECT子句里,聚合函数的执行结果也是标量值,因此可以像常量和普通列一样使用
2.1.1.4.3. 和标量子查询的做法一样简洁,也能灵活地应对需求变更
-
2.1.1.5. --水平展开(3):嵌套使用CASE表达式
SELECT name,
CASE WHEN SUM(CASE WHEN course = \'SQL入门’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "SQL入门",
CASE WHEN SUM(CASE WHEN course = \'UNIX基础’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "UNIX基础",
CASE WHEN SUM(CASE WHEN course = \'Java中级’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "Java中级"
FROM Courses
GROUP BY name;
3. 汇总重复项于一列(列→行)
3.1. 示例
- 3.1.1.
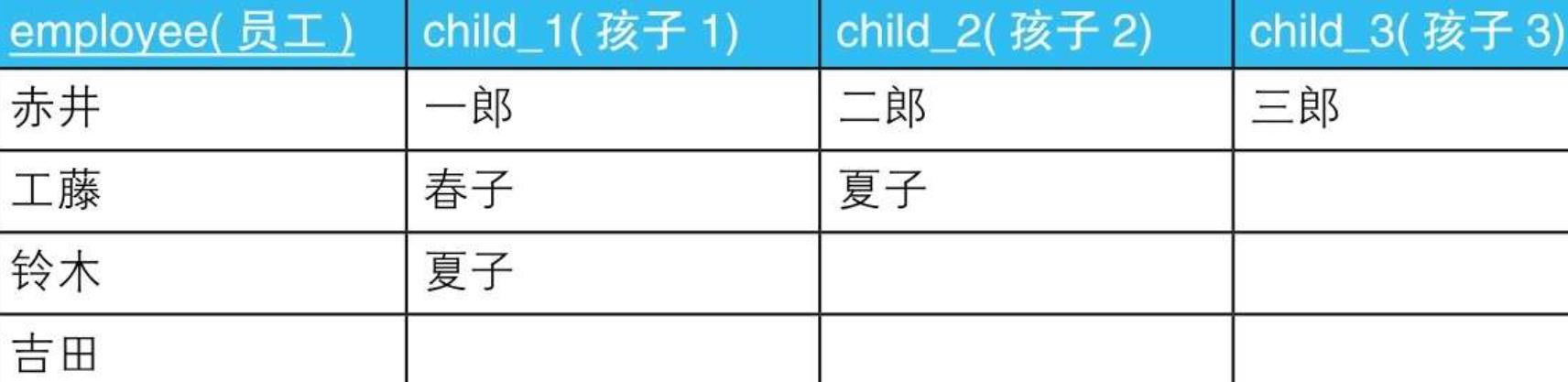
- 3.1.1.1. --列数据转换成行数据:使用UNION ALL
SELECT employee, child_1 AS child FROM Personnel
UNION ALL
SELECT employee, child_2 AS child FROM Personnel
UNION ALL
SELECT employee, child_3 AS child FROM Personnel;
- 3.1.1.2. 视图
CREATE VIEW Children(child)
AS SELECT child_1 FROM Personnel
UNION
SELECT child_2 FROM Personnel
UNION
SELECT child_3 FROM Personnel;
child
-----
一郎
二郎
三郎
春子
夏子
3.1.1.2.1. --获取员工子女列表的SQL语句(没有孩子的员工也要输出)
SELECT EMP.employee, CHILDREN.child
FROM Personnel EMP
LEFT OUTER JOIN Children
ON CHILDREN.child IN (EMP.child_1, EMP.child_2, EMP.child_3);
4. 制作嵌套式表侧栏
4.1. 示例
- 4.1.1.


- 4.1.2.
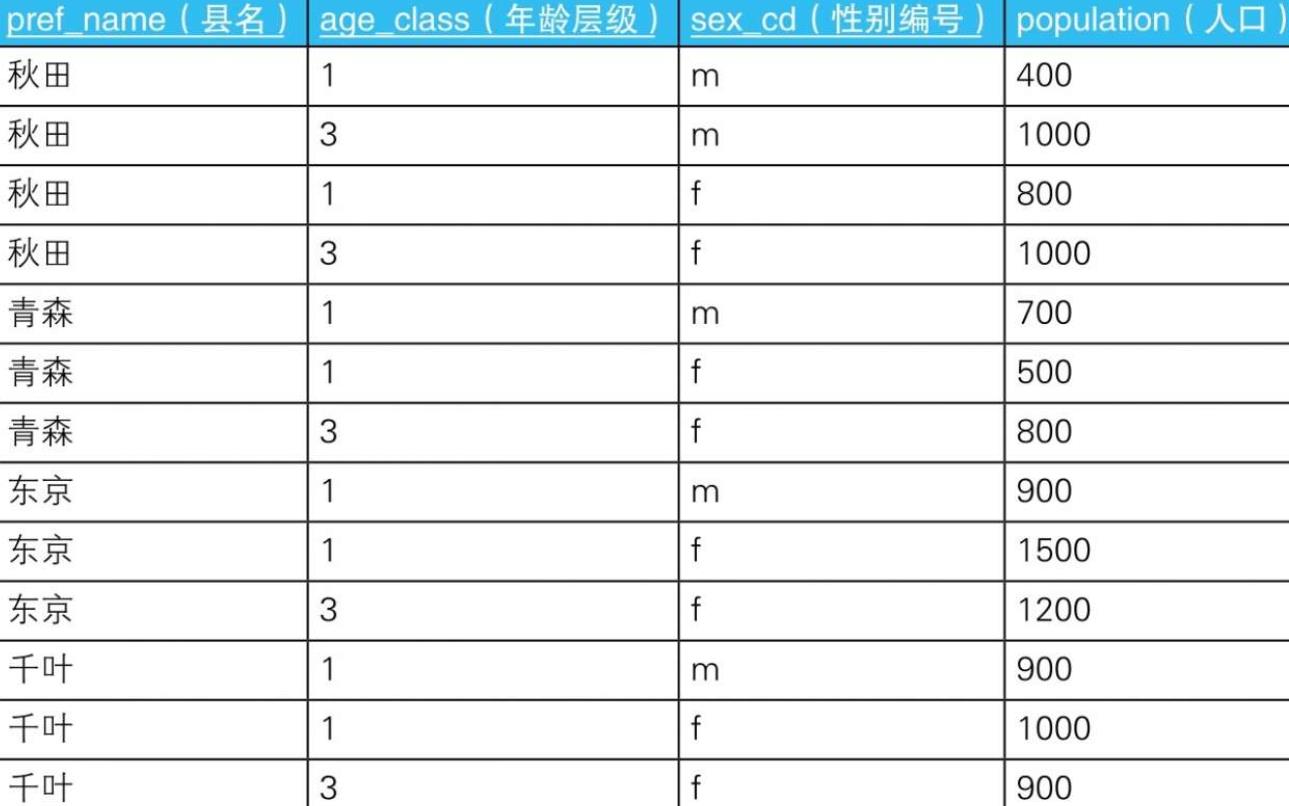
-
4.1.3. 结果
- 4.1.3.1.
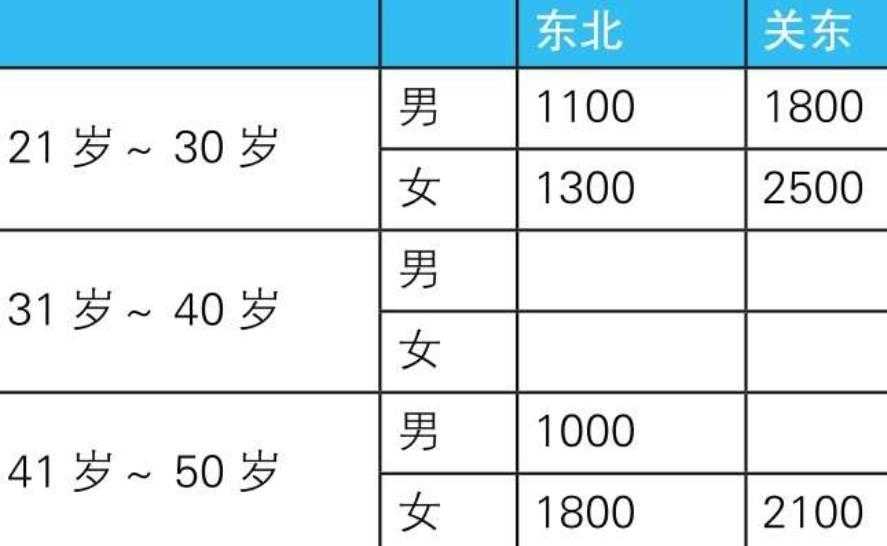
- 4.1.4. --使用外连接生成嵌套式表侧栏:错误的SQL语句
SELECT MASTER1.age_class AS age_class,
MASTER2.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
RIGHT OUTER JOIN TblAge MASTER1--外连接1:和年龄层级主表进行外连接
ON MASTER1.age_class = DATA.age_class
RIGHT OUTER JOIN TblSex MASTER2--外连接2:和性别主表进行外连接
ON MASTER2.sex_cd = DATA.sex_cd;
- 4.1.4.1. --停在第1个外连接处时:结果里包含年龄层级为2的数据
SELECT MASTER1.age_class AS age_class,
DATA.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
RIGHT OUTER JOIN TblAge MASTER1
ON MASTER1.age_class = DATA.age_class;
-
4.1.5. 如果不允许进行两次外连接,那么调整成一次就可以了
-
4.1.6. 对于不支持CROSS JOIN语句的数据库,可以像FROM TblAge,TblSex这样不指定连接条件,把需要连接的表写在一起,其效果与交叉连接一样
-
4.1.7. 如果先生成主表的笛卡儿积再进行连接,很容易就可以完成
-
4.1.8. --使用外连接生成嵌套式表侧栏:正确的SQL语句
SELECT MASTER.age_class AS age_class,
MASTER.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd
FROM TblAge CROSS JOIN TblSex ) MASTER --使用交叉连接生成两张主表的笛卡儿积
LEFT OUTER JOIN
(SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
ON MASTER.age_class = DATA.age_class
AND MASTER.sex_cd = DATA.sex_cd;
5. 作为乘法运算的连接
5.1. 示例
- 5.1.1.
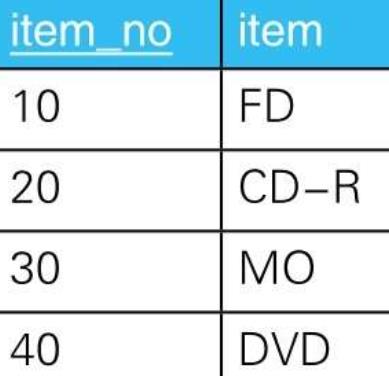
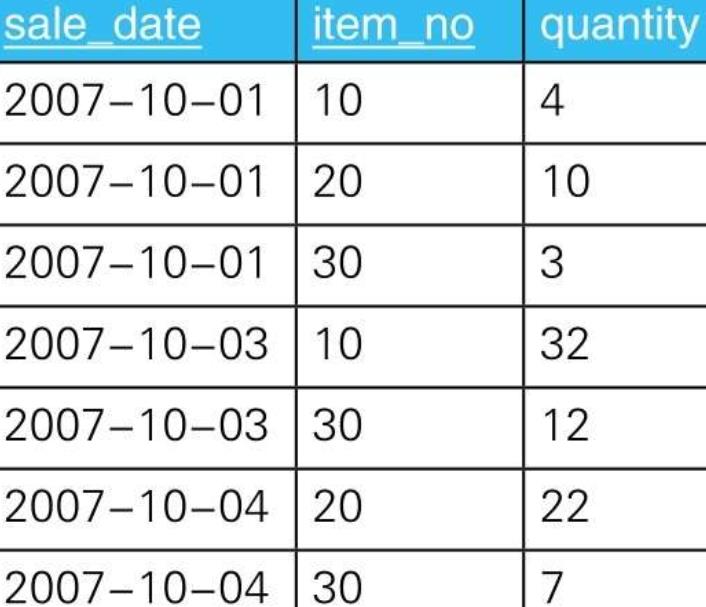
- 5.1.2. --解答(1):通过在连接前聚合来创建一对一的关系
SELECT I.item_no, SH.total_qty
FROM Items I LEFT OUTER JOIN
(SELECT item_no, SUM(quantity) AS total_qty
FROM SalesHistory
GROUP BY item_no) SH
ON I.item_no = SH.item_no;
-
5.1.2.1. 以商品编号为主键的临时视图
-
5.1.2.2. 无法利用索引优化查询
-
5.1.3. --解答(2):先进行一对多的连接再聚合
SELECT I.item_no, SUM(SH.quantity) AS total_qty
FROM Items I LEFT OUTER JOIN SalesHistory SH
ON I.item_no = SH.item_no 一对多的连接
GROUP BY I.item_no;
-
5.1.3.1. 代码更简洁
-
5.1.3.2. 没有使用临时视图,所以性能也会有所改善
5.2. 从行数来看,表连接可以看成乘法。因此,当表之间是一对多的关系时,连接后行数不会增加
6. 全外连接
6.1. FULL OUTER JOIN
6.2. 相当于求集合的和(UNION,也称并集)
- 6.2.1. 内连接相当于求集合的积(INTERSECT,也称交集)
6.3. 示例
- 6.3.1. --全外连接保留全部信息
SELECT COALESCE(A.id, B.id) AS id,
A.name AS A_name,
B.name AS B_name
FROM Class_A A FULL OUTER JOIN Class_B B
ON A.id = B.id;
- 6.3.1.1. --数据库不支持全外连接时的替代方案
SELECT A.id AS id, A.name, B.name
FROM Class_A A LEFT OUTER JOIN Class_B B
ON A.id = B.id
UNION
SELECT B.id AS id, A.name, B.name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id;
6.3.1.1.1. 分别进行左外连接和右外连接,再把两个结果通过UNION合并起来
6.4. COALESCE是SQL的标准函数
- 6.4.1. 可以接受多个参数,功能是返回第一个非NULL的参数
6.5. 外连接的思想和集合运算很像,使用外连接可以实现各种集合运算
7. 用外连接求差集:B-A
7.1. 示例
- 7.1.1.
SELECT B.id AS id, B.name AS B_name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL;
7.2. 可以作为NOT IN和NOT EXISTS之外的另一种解法
7.3. 可能是差集运算中效率最高的
8. 用全外连接求异或集
8.1. SQL没有定义求异或集的运算符
8.2. 用集合运算符
-
8.2.1. (A UNION B) EXCEPT (A INTERSECT B)
-
8.2.2. (A EXCEPT B) UNION (B EXCEPT A)
-
8.2.3. 性能开销大
8.3. 示例
- 8.3.1.
SELECT COALESCE(A.id, B.id) AS id,
COALESCE(A.name , B.name ) AS name
FROM Class_A A FULL OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL
OR B.name IS NULL;
9. 用外连接进行关系除法
9.1. 示例
- 9.1.1. --用外连接进行关系除法运算:差集的应用
SELECT DISTINCT shop
FROM ShopItems SI1
WHERE NOT EXISTS
(SELECT I.item
FROM Items I LEFT OUTER JOIN ShopItems SI2
ON I.item = SI2.item
AND SI1.shop = SI2.shop
WHERE SI2.item IS NULL) ;
以上是关于读SQL进阶教程笔记16_SQL优化让SQL飞起来的主要内容,如果未能解决你的问题,请参考以下文章