监听容器中的文件系统事件
Posted 公众号:abin在路上
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了监听容器中的文件系统事件相关的知识,希望对你有一定的参考价值。
 inotify,fanotify,setns基本概念和示例,最终实现通过 fanotify 监听容器中的文件系统事件。
inotify,fanotify,setns基本概念和示例,最终实现通过 fanotify 监听容器中的文件系统事件。
基本概念
Linux 文件系统事件监听:应用层的进程操作目录或文件时,会触发 system call,此时,内核中的 notification 子系统把该进程对文件的操作事件上报给应用层的监听进程(称为 listerner)。
dnotify:2001 年的 kernel 2.4 版本引入,只能监控 directory,采用的是 signal 机制来向 listener 发送通知,可以传递的信息很有限。
inotify:2005 年在 kernel 2.6.13 中亮相,除了可以监控目录,还可以监听普通文件,inotify 摈弃了 signal 机制,通过 event queue 向 listener 上传事件信息。
fanotify:kernel 2.6.36 引入,fanotify 的出现解决了已有实现只能 notify 的问题,允许 listener 介入并改变文件事件的行为,实现从“监听”到“监控”的跨越。
本文主要介绍如何通过 inotify 和 fanotify 监听容器中的文件系统事件。
Inotify
基本介绍
inotify(inode[1] notify)是 Linux 内核中的一个子系统,由 John McCutchan[2] 创建,用于监视文件系统事件。它可以在文件或目录发生变化时通知应用程序,例如,监听文件的创建、修改或删除事件。inotify 可以用于自动更新文件系统视图、重新加载配置文件,记录文件改变历史等场景。
Inotify 的工作流程如下:
-
用户通过系统调用(如:write、read)操作文件;
-
内核将文件系统事件保存到 fsnotify_group 的事件队列中;
-
唤醒等待 inotify 的进程(listener);
-
进程通过 fd 从内核队列读取 inotify 事件。
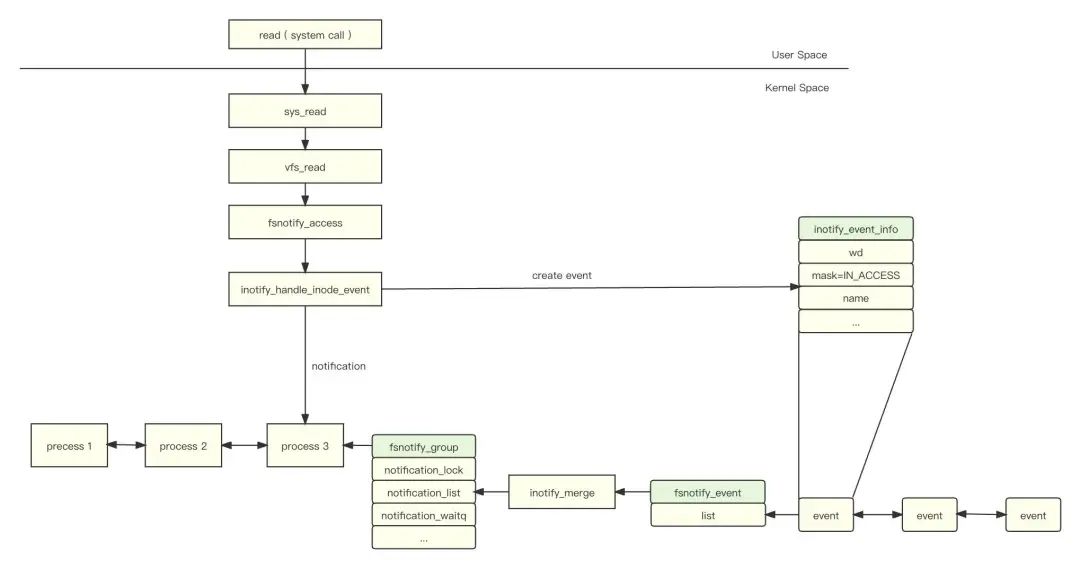
其中,inotify_event_info 的定义如下:
struct inotify_event_info
struct fsnotify_event fse;
u32 mask; /* Watch mask. */
int wd; /* Watch descriptor. */
u32 sync_cookie; /* Cookie to synchronize two events. */
int name_len; /* Name. */
char name[]; /* Length (including NULs) of name. */
;
mask 标记具体的文件操作事件。
API 介绍
Inotify 可以用来监听单个文件,也可以用来监听目录。当监听的是目录时,inotify 除了生成目录的事件,还会生成目录中文件的事件。
“
注意:当使用 inotify 监听目录时,并不会递归监听子目录中的文件,如果需要得到这些事件,需要手动指定监听这些文件。对于很大的目录树,这个过程将花费大量时间。
参考:inotify.7[3]
- inotify_init(void)
初始化 inotify 实例,返回文件描述符,用于内核向用户态程序传输监听到的 inotify 事件。函数声明为:
int inotify_init(void);
内核同时提供了int inotify_init1(int flags),flags 的可选值如下:
IN_NONBLOCK
读取文件描述符时不会被阻塞,即使没有数据可用也是如此。
如果没有数据可用,则读操作将立即返回0,而不是等待数据可用。
IN_CLOEXEC
如果在程序运行时打开了一个文件描述符,并且在调用execve()时没有将其关闭,
那么在新程序中仍然可以使用该文件描述符。
设置IN_CLOEXEC标志后,可以确保在调用execve()时关闭文件描述符,避免在新程序中使用。
可以通过 OR 指定多个flag,当flags=0等价于int inotify_init(void)。
- inotify_add_watch
添加需要监听的目录或文件(watch list),可以添加新的路径,也可以是已经添加过的路径。fd 是inotify_init返回的文件描述符,mask 指定需要监听的事件类型,通过 OR 指定多个事件。返回值是当前路径的wd(watch descriptor),可用于移除对该路径的监听。
函数声明为:
#include <sys/inotify.h>
int inotify_add_watch(int fd, const char *pathname, uint32_t mask);
Inotify 支持监听的事件包括:
/* Supported events suitable for MASK parameter of INOTIFY_ADD_WATCH. */
#define IN_ACCESS 0x00000001 /* File was accessed. */
#define IN_MODIFY 0x00000002 /* File was modified. */
#define IN_ATTRIB 0x00000004 /* Metadata changed. */
#define IN_CLOSE_WRITE 0x00000008 /* Writtable file was closed. */
#define IN_CLOSE_NOWRITE 0x00000010 /* Unwrittable file closed. */
#define IN_CLOSE (IN_CLOSE_WRITE | IN_CLOSE_NOWRITE) /* Close. */
#define IN_OPEN 0x00000020 /* File was opened. */
#define IN_MOVED_FROM 0x00000040 /* File was moved from X. */
#define IN_MOVED_TO 0x00000080 /* File was moved to Y. */
#define IN_MOVE (IN_MOVED_FROM | IN_MOVED_TO) /* Moves. */
#define IN_CREATE 0x00000100 /* Subfile was created. */
#define IN_DELETE 0x00000200 /* Subfile was deleted. */
#define IN_DELETE_SELF 0x00000400 /* Self was deleted. */
#define IN_MOVE_SELF 0x00000800 /* Self was moved. */
- inotify_rm_watch
移除被监听的路径。fd 是inotify_init返回的文件描述符,wd 是inotify_add_watch返回的监听文件描述符。
函数声明为:
#include <sys/inotify.h>
int inotify_rm_watch(int fd, int wd);
实例
以下是基于 Rust 语言实现的实例:
use nix::
poll::poll, PollFd, PollFlags,
sys::inotify::AddWatchFlags, InitFlags, Inotify, InotifyEvent,
;
use signal_hook::consts::SIGTERM, low_level::pipe;
use std::os::unix::net::UnixStream;
use std::env, io, os::fd::AsRawFd, path::PathBuf;
fn main() -> io::Result<()>
let args: Vec<String> = env::args().collect();
if args.len() < 2
eprintln!("Usage: <path>", args[0]);
std::process::exit(1);
let path = PathBuf::from(&args[1]);
// 初始化 inotify,得到 fd
let inotify_fd = Inotify::init(InitFlags::empty())?;
// 添加被监听的目录或文件,指定需要监听的事件
let wd = inotify_fd.add_watch(
&path,
AddWatchFlags::IN_ACCESS | AddWatchFlags::IN_OPEN | AddWatchFlags::IN_CREATE,
)?;
let (read, write) = UnixStream::pair()?;
// 注册用于处理信号的 pipe
if let Err(e) = pipe::register(SIGTERM, write)
println!("failed to set SIGTERM signal handler e:?");
let mut fds = [
PollFd::new(inotify_fd.as_raw_fd(), PollFlags::POLLIN),
PollFd::new(read.as_raw_fd(), PollFlags::POLLIN),
];
loop
match poll(&mut fds, -1)
Ok(polled_num) =>
if polled_num <= 0
eprintln!("polled_num <= 0!");
break;
if let Some(flag) = fds[0].revents()
if flag.contains(PollFlags::POLLIN)
// 得到 inotify 事件,进行处理
let events = inotify_fd.read_events()?;
for event in events
handle_event(event)?;
if let Some(flag) = fds[1].revents()
if flag.contains(PollFlags::POLLIN)
println!("received SIGTERM signal");
break;
Err(e) =>
if e == nix::Error::EINTR
continue;
eprintln!("Poll error :?", e);
break;
inotify_fd.rm_watch(wd)?;
Ok(())
fn handle_event(event: InotifyEvent) -> io::Result<()>
let file_name = match event.name
Some(name) => name,
None => return Ok(()),
;
let event_mask = event.mask;
let kind = if event_mask.contains(AddWatchFlags::IN_ISDIR)
"directory"
else
"file"
;
println!(
" was :?.",
kind,
file_name.to_string_lossy(),
event_mask
);
Ok(())
编译&测试:
cargo build
./target/debug/inotify test
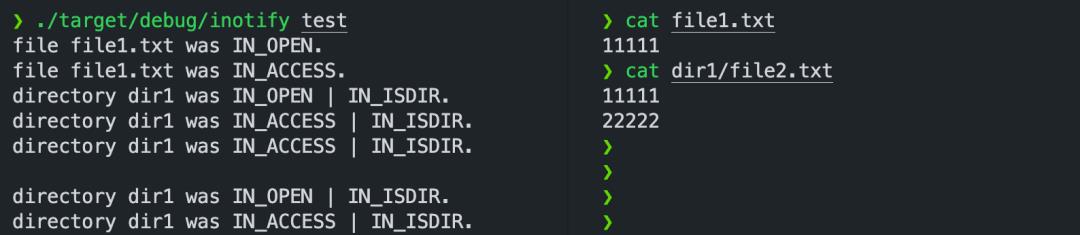
可以看到,inotify 不会递归监听二级目录下的文件dir1/file2.txt。
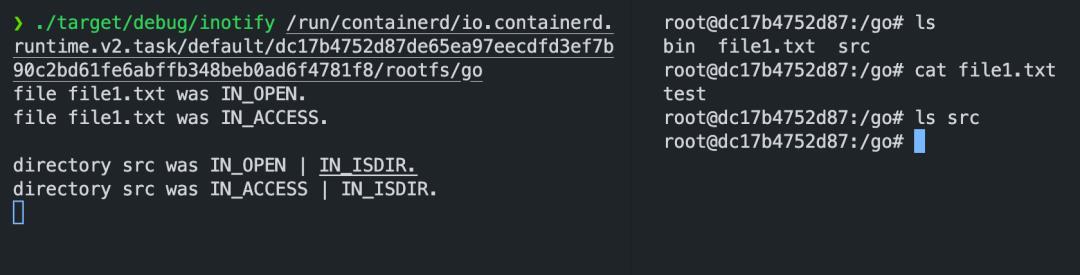
经测试,Inotify 可以直接监听容器 rootfs 下的目录:
nerdctl run --rm -it golang
./target/debug/inotify /run/containerd/io.containerd.runtime.v2.task/default/CONTAINERD_ID/rootfs
Fanotify
基本介绍
Inotify 能够监听目录和文件的事件,但这种 notifiation 机制也存在局限:inotify 只能通知用户态进程触发了哪些文件系统事件,而无法进行干预,典型的应用场景是杀毒软件。
Fanotify[4] 的出现就是为了解决这个问题,同时允许递归监听目录下的子目录和文件。
Fanotify 的工作流程如下:
-
用户通过系统调用(如:write、read)操作文件;
-
内核将文件系统事件发送到 fsnotify_group 的事件队列中;
-
唤醒等待 fanotify 事件的进程(listener);
-
进程通过 fd 从内核队列读取 fanotify 事件;
-
如果是 FAN_OPEN_PERM 和 FAN_ACCESS_PERM 监听类型,进程需要通过 write 把许可信息(允许 or 拒绝)写回内核;
-
内核根据许可信息决定是否继续完成该文件系统事件。
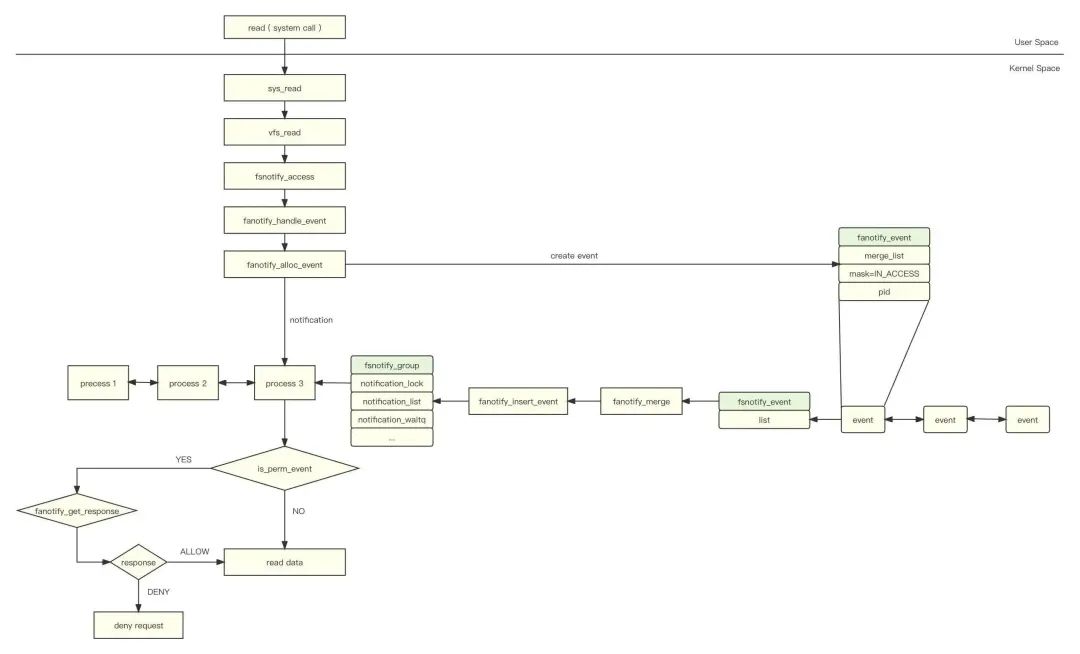
fanotify_event 的定义如下:
struct fanotify_event
struct fsnotify_event fse;
struct hlist_node merge_list; /* List for hashed merge */
u32 mask;
struct
unsigned int type : FANOTIFY_EVENT_TYPE_BITS;
unsigned int hash : FANOTIFY_EVENT_HASH_BITS;
;
struct pid *pid;
;
fsnotify_group 的定义参考:linux/fsnotify_backend.h#L185[5]
API 介绍
- fanotify_init()
初始化 fanotify 事件组,返回该事件组的文件描述符,用于内核向用户态程序传输 fanotify 事件,同时接收来自用户态进程的许可信息。函数声明为:
#include <fcntl.h> /* Definition of O_* constants */
#include <sys/fanotify.h>
int fanotify_init(unsigned int flags, unsigned int event_f_flags);
flags 定义了事件通知的类型和文件描述符的行为,可选值有:
/* These are NOT bitwise flags. Both bits are used together. */
#define FAN_CLASS_NOTIF 0x00000000
#define FAN_CLASS_CONTENT 0x00000004
#define FAN_CLASS_PRE_CONTENT 0x00000008
/* flags used for fanotify_init() */
#define FAN_CLOEXEC 0x00000001
#define FAN_NONBLOCK 0x00000002
#define FAN_UNLIMITED_QUEUE 0x00000010
#define FAN_UNLIMITED_MARKS 0x00000020
#define FAN_ENABLE_AUDIT 0x00000040
/* Flags to determine fanotify event format */
#define FAN_REPORT_TID 0x00000100 /* event->pid is thread id */
#define FAN_REPORT_FID 0x00000200 /* Report unique file id */
#define FAN_REPORT_DIR_FID 0x00000400 /* Report unique directory id */
#define FAN_REPORT_NAME 0x00000800 /* Report events with name */
/* Convenience macro - FAN_REPORT_NAME requires FAN_REPORT_DIR_FID */
#define FAN_REPORT_DFID_NAME (FAN_REPORT_DIR_FID | FAN_REPORT_NAME)
Fanotify 允许多个 listener 监听同一个文件系统对象,并且分为不同的级别,通过 flags 指定。
-
FAN_CLASS_NOTIF:只用于监听,不访问文件内容。
-
FAN_CLASS_CONTENT:可以访问文件内容。
-
FAN_CLASS_PRE_CONTENT:在访问文件内容之前可获取访问权限。
event_f_flags 用于设置 fanotify 事件创建并打开的文件描述符状态,可选值有:
#define O_RDONLY 00 /* Allow only read access. */
#define O_WRONLY 01 /* Allow only write access. */
#define O_RDWR 02 /* Allow read and write access. */
// 其它常用的 event_f_flags
# define O_LARGEFILE __O_LARGEFILE /* Enable support for files exceeding 2 GB. */
# define O_CLOEXEC __O_CLOEXEC /* Set close_on_exec. */
以下 event_f_flags 也可以使用:O_APPEND、O_DSYNC、O_NOATIME、O_NONBLOCK 和 O_SYNC,使用除这些以外的其它值将返回 EINVAL 错误码。
更多请信息参考 fanotify_init.2[6]
- fanotify_mark()
添加、删除和修改文件系统中被监听的路径,必须对该路径有访问权限。函数声明为:
#include <sys/fanotify.h>
int fanotify_mark(int fanotify_fd, unsigned int flags,uint64_t mask, int dirfd, const char *pathname);
fanotify_fd 是fanotify_init返回的文件描述符,flags 描述操作类型,可选值有:
/* flags used for fanotify_modify_mark() */
#define FAN_MARK_ADD 0x00000001
#define FAN_MARK_REMOVE 0x00000002
/* 如果 pathname 是符号链接,只监听符号链接而不需要监听文件本身(默认会监听文件本身) */
#define FAN_MARK_DONT_FOLLOW 0x00000004
#define FAN_MARK_ONLYDIR 0x00000008 /* 只监听目录,如果传入的不是目录返回错误 */
/* FAN_MARK_MOUNT is 0x00000010 */
#define FAN_MARK_IGNORED_MASK 0x00000020
#define FAN_MARK_IGNORED_SURV_MODIFY 0x00000040
#define FAN_MARK_FLUSH 0x00000080 /* 移除所有 marks */
/* FAN_MARK_FILESYSTEM is 0x00000100 */
mask 定义了需要监听的事件:
/* the following events that user-space can register for */
#define FAN_ACCESS 0x00000001 /* File was accessed */
#define FAN_MODIFY 0x00000002 /* File was modified */
#define FAN_ATTRIB 0x00000004 /* Metadata changed */
#define FAN_CLOSE_WRITE 0x00000008 /* Writtable file closed */
#define FAN_CLOSE_NOWRITE 0x00000010 /* Unwrittable file closed */
#define FAN_OPEN 0x00000020 /* File was opened */
#define FAN_MOVED_FROM 0x00000040 /* File was moved from X */
#define FAN_MOVED_TO 0x00000080 /* File was moved to Y */
#define FAN_CREATE 0x00000100 /* Subfile was created */
#define FAN_DELETE 0x00000200 /* Subfile was deleted */
#define FAN_DELETE_SELF 0x00000400 /* Self was deleted */
#define FAN_MOVE_SELF 0x00000800 /* Self was moved */
#define FAN_OPEN_EXEC 0x00001000 /* File was opened for exec */
#define FAN_Q_OVERFLOW 0x00004000 /* Event queued overflowed */
#define FAN_FS_ERROR 0x00008000 /* Filesystem error */
#define FAN_OPEN_PERM 0x00010000 /* File open in perm check */
#define FAN_ACCESS_PERM 0x00020000 /* File accessed in perm check */
#define FAN_OPEN_EXEC_PERM 0x00040000 /* File open/exec in perm check */
#define FAN_EVENT_ON_CHILD 0x08000000 /* Interested in child events */
#define FAN_RENAME 0x10000000 /* File was renamed */
#define FAN_ONDIR 0x40000000 /* Event occurred against dir */
/* helper events */
#define FAN_CLOSE (FAN_CLOSE_WRITE | FAN_CLOSE_NOWRITE) /* close */
#define FAN_MOVE (FAN_MOVED_FROM | FAN_MOVED_TO) /* moves */
参数 dirfd 和 pathname 确定需要监听的文件系统对象:
(1)如果 pathname 为 NULL,由 dirfd 确定。
(2)如果 pathname 为 NULL 且 dirfd 的值为 AT_FDCWD,监听当前工作目录。
(3)如果 pathname 为绝对路径,dirfd 被忽略。
(4)如果 pathname 为相对路径且 dirfd 不是 AT_FDCWD,监听 pathname 相对于 dirfd 目录的路径。
(5)如果 pathname 为相对路径且 dirfd 的值为 AT_FDCWD,监听 pathname 相对于当前目录的路径。
Fanotify 有 3 种监听模式:directed,per-mount 和 global,由 fanotify_mark 函数的 flags 参数指定,默认为 FAN_MARK_INODE,也就是 directed 模式。
-
directed:flag为FAN_MARK_MOUNT,和inotify类似,监听指定inode对象,如果是目录,可以添加FAN_EVENT_ON_CHILD指定监听该目录下的所有文件(不会递归监听子目录中的文件)。per-mount和global模式下,FAN_EVENT_ON_CHILD无效。 -
per-mount:flag为FAN_MARK_MOUNT,监听指定挂载点下所有的内容(目录,子目录,文件),如果传入的path不是挂载点,则会监听path所在的挂载点。 -
global:flag为FAN_MARK_FILESYSTEM,监听path所在的文件系统,包括所有挂载点中的目录和文件。
实例
use lazy_static::lazy_static;
use libc::__s32, __u16, __u32, __u64, __u8;
use nix::poll::poll, PollFd, PollFlags;
use signal_hook::consts::SIGTERM, low_level::pipe;
use std::os::unix::net::UnixStream;
use std::env, ffi, fs, io, mem, os::fd::AsRawFd, path::PathBuf, slice;
#[derive(Debug, Clone, Copy)]
#[repr(C)]
struct FanotifyEvent
event_len: __u32,
vers: __u8,
reserved: __u8,
metadata_len: __u16,
mask: __u64,
fd: __s32,
pid: __s32,
lazy_static!
static ref FAN_EVENT_METADATA_LEN: usize = mem::size_of::<FanotifyEvent>();
const FAN_CLOEXEC: u32 = 0x0000_0001;
const FAN_NONBLOCK: u32 = 0x0000_0002;
const FAN_CLASS_CONTENT: u32 = 0x0000_0004;
const O_RDONLY: u32 = 0;
const O_LARGEFILE: u32 = 0;
const FAN_MARK_ADD: u32 = 0x0000_0001;
const FAN_MARK_MOUNT: u32 = 0x0000_0010;
// const FAN_MARK_FILESYSTEM: u32 = 0x00000100;
const FAN_ACCESS: u64 = 0x0000_0001;
const FAN_OPEN: u64 = 0x0000_0020;
const FAN_OPEN_EXEC: u64 = 0x00001000;
const AT_FDCWD: i32 = -100;
const FAN_EVENT_ON_CHILD: u64 = 0x08000000;
const FAN_ONDIR: u64 = 0x4000_0000;
// 初始化 fanotify,调用 libc 的函数
fn init_fanotify() -> Result<i32, io::Error>
unsafe
match libc::fanotify_init(
FAN_CLOEXEC | FAN_CLASS_CONTENT | FAN_NONBLOCK,
O_RDONLY | O_LARGEFILE,
)
-1 => Err(io::Error::last_os_error()),
fd => Ok(fd),
fn mark_fanotify(fd: i32, path: &str) -> Result<(), io::Error>
let path = ffi::CString::new(path)?;
unsafe
match libc::fanotify_mark(
fd,
// FAN_MARK_ADD,
FAN_MARK_ADD | FAN_MARK_MOUNT,
// FAN_MARK_ADD | FAN_MARK_FILESYSTEM,
FAN_OPEN | FAN_ACCESS | FAN_OPEN_EXEC | FAN_EVENT_ON_CHILD,
AT_FDCWD,
path.as_ptr(),
)
0 => Ok(()),
_ => Err(io::Error::last_os_error()),
fn read_fanotify(fanotify_fd: i32) -> Vec<FanotifyEvent>
let mut vec = Vec::new();
unsafe
let buffer = libc::malloc(*FAN_EVENT_METADATA_LEN * 1024);
let sizeof = libc::read(fanotify_fd, buffer, *FAN_EVENT_METADATA_LEN * 1024);
let src = slice::from_raw_parts(
buffer as *mut FanotifyEvent,
sizeof as usize / *FAN_EVENT_METADATA_LEN,
);
vec.extend_from_slice(src);
libc::free(buffer);
vec
// fanotify event 只有 fd,需要手动获取对应的 path
fn get_fd_path(fd: i32) -> io::Result<PathBuf>
let fd_path = format!("/proc/self/fd/fd");
fs::read_link(fd_path)
fn main() -> io::Result<()>
let args: Vec<String> = env::args().collect();
if args.len() < 2
eprintln!("Usage: <path>", args[0]);
std::process::exit(1);
let path_buf = PathBuf::from(&args[1]);
let path = path_buf.to_str().unwrap_or(".");
let fanotify_fd = init_fanotify()?;
mark_fanotify(fanotify_fd, path)?;
let (read, write) = UnixStream::pair()?;
if let Err(e) = pipe::register(SIGTERM, write)
println!("failed to set SIGTERM signal handler e:?");
let mut fds = [
PollFd::new(fanotify_fd.as_raw_fd(), PollFlags::POLLIN),
PollFd::new(read.as_raw_fd(), PollFlags::POLLIN),
];
loop
match poll(&mut fds, -1)
Ok(polled_num) =>
if polled_num <= 0
eprintln!("polled_num <= 0!");
break;
if let Some(flag) = fds[0].revents()
if flag.contains(PollFlags::POLLIN)
let events = read_fanotify(fanotify_fd);
for event in events
handle_event(event)?;
if let Some(flag) = fds[1].revents()
if flag.contains(PollFlags::POLLIN)
println!("received SIGTERM signal");
break;
Err(e) =>
if e == nix::Error::EINTR
continue;
eprintln!("Poll error :?", e);
break;
Ok(())
fn close_fd(fd: i32)
unsafe
libc::close(fd);
fn handle_event(event: FanotifyEvent) -> io::Result<()>
let fd = event.fd;
let event_mask = event.mask;
let kind = if (event_mask & FAN_ONDIR) != 0
"directory"
else
"file"
;
let path = get_fd_path(fd)?;
println!(" mask :b.", kind, path.to_string_lossy(), event_mask);
close_fd(fd);
Ok(())
- 参数:
flags默认值 +FAN_EVENT_ON_CHILD,path为目录:

监控 path 目录下所有文件的文件系统事件。
-
参数:
flags默认值 +FAN_EVENT_ON_CHILD,path为容器rootfs目录,无法监听到事件。(不能跨 mount namespace[7]) -
参数:
flags默认值,传入目录但是没有FAN_ONDIR:不能监听到事件。 -
参数:
flags默认值 +FAN_ONDIR:

监听到 path 目录本身的文件系统事件。
-
参数:
flagsFAN_MARK_MOUNT,path为目录:监听到path所在挂载点的事件。 -
参数:
flagsFAN_MARK_MOUNT,path为挂载点下的文件:
mount --bind test fatest

监听到挂载点下所有文件(包括子目录)的文件系统事件(dir1/file2.txt 是 path 子目录中的文件)。
-
参数:
flagsFAN_MARK_MOUNT,path为容器rootfs目录,无法监听到事件。(不能跨 mount namespace) -
参数:
flagsFAN_MARK_FILESYSTEM,path为目录,监听到目录所在文件系统的事件。包括其它挂载点。 -
参数:
flagsFAN_MARK_FILESYSTEM,path为容器rootfs:
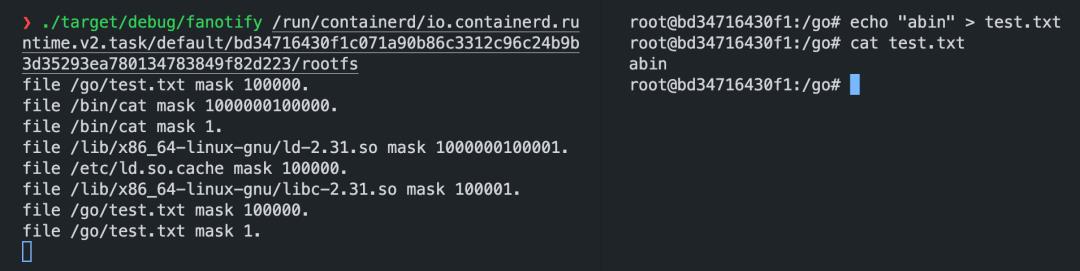
可以监听到 rootfs 下的文件系统事件,但看起来不完整,例如,下面的例子中,正确的结果应包括访问 /etc/hosts 的事件。

因此,使用 fanotify 监听容器 rootfs 中文件系统的最终解决方案:进入容器所在的 mount namespace,使用 FAN_MARK_MOUNT flag 监听容器的根目录,即可递归监听容器中所有文件的事件。
Setns
基本介绍
setns[8] 是 Linux 的系统调用,允许进程切换到另一个进程所在的命名空间。Linux 中的命名空间提供了内核级别的资源隔离,不同命名空间中的程序享有独立的资源。目前,提供了 8 种资源隔离:
-
Mount: 文件系统挂载点,flag:CLONE_NEWNS(mount namespace 是最早提出的命名空间,所以flag定为CLONE_NEWNS,而不是CLONE_NEWMNT) -
UTS: 主机名和域名信息,flag:CLONE_NEWUTS -
IPC: 进程间通信,flag:CLONE_NEWIPC -
PID: 进程 ID,flag:CLONE_NEWPID -
Network: 网络资源,flag:CLONE_NEWNET -
User: 用户和用户组的 ID,flag:CLONE_NEWUSER -
CGROUP:Cgroup 资源,flag:CLONE_NEWCGROUP(从 Linux 4.6 开始支持) -
Time:时间资源,flag:CLONE_NEWTIME(从 Linux 5.8 开始支持)
Linux 中操作命名空间除了 setns,还有 clone 和 unshare 系统调用。
-
setns:给已存在进程设置已存在的命名空间。
-
clone:创建新进程时,使用新的命名空间。(默认使用父进程的命名空间)
-
unshare:让已存在进程使用新的命名空间。
API 介绍
函数声明如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <sched.h>
int setns(int fd, int nstype);
fd 和已存在进程有关:
- 已存在进程 /proc/[pid]/ns/ 目录下的不同命名空间对应文件的 fd:
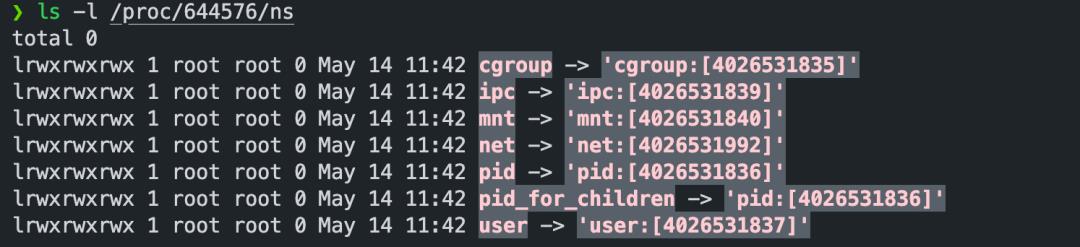
nstype 指定命名空间的类型,包括以下值:
-
0:任意类型(最好在知道 fd 指向命名空间类型时使用) -
CLONE_NEWCGROUP:fd 必须指向 cgroup 命名空间(从 Linux 4.6 开始支持),调用者需拥有CAP_SYS_ADMIN能力,setns 不会修改原 cgroup 中子 cgroup 的命名空间。 -
CLONE_NEWIPC:fd 必须指向 IPC 命名空间(从 Linux 3.0 开始支持),在原 user 命名空间和目标命名空间都需要有CAP_SYS_ADMIN能力。 -
CLONE_NEWNET:fd 必须指向 network 命名空间(从 Linux 3.0 开始支持),在原 user 命名空间和目标命名空间都需要有CAP_SYS_ADMIN能力。 -
CLONE_NEWNS:fd 必须指向 mount 命名空间(从 Linux 3.8 开始支持),在原命名空间需要有CAP_SYS_CHROOT和CAP_SYS_ADMIN能力,在目标命名空间都需要有CAP_SYS_ADMIN能力。如果和其它进程(通过clone的CLONE_FS实现)共享文件系统属性,则不能加入新的 mount 命名空间。 -
CLONE_NEWPID:fd 必须指向 PID 命名空间(从 Linux 3.8 开始支持),在原 user 命名空间和目标命名空间都需要有CAP_SYS_ADMIN能力。PID 和其它命名空间不同,sentns 加入 PID 命名空间之后,并不会修改 caller 的 PID 命名空间,加入之后,由 caller 创建的子进程使用新的 PID 命名空间。 -
CLONE_NEWTIME:fd 必须指向 time 命名空间(从 Linux 5.8 开始支持),在原 user 命名空间和目标命名空间都需要有CAP_SYS_ADMIN能力。 -
CLONE_NEWUSER:fd 必须指向 user 命名空间(从 Linux 3.8 开始支持),必须在目标命名空间有CAP_SYS_ADMIN能力。多线程程序加入 user 命名空间可能失败。不允许使用 setns 再次进入 caller 所在的 user 命名空间。出于安全原因考虑,如果和其它进程(通过clone的CLONE_FS实现)共享文件系统属性,则不能加入新的 user 命名空间。 -
CLONE_NEWUTS:fd 必须指向 UTS 命名空间(从 Linux 3.0 开始支持),在原 user 命名空间和目标命名空间都需要有CAP_SYS_ADMIN能力。
- 进程 PID 的文件描述符(详见 pidfd_open[9],Linux 5.8 开始支持)
nstype 指定要加入的命名空间类型。例如:要加入 PID 为 1234 所在的 USER、NET、UTS 命名空间,保持其它命名空间不变:
int fd = pidfd_open(1234, 0);
setns(fd, CLONE_NEWUSER | CLONE_NEWNET | CLONE_NEWUTS);
实例
use nix::
sched::setns, CloneFlags,
;
use std::env, fs, io, os::fd::AsRawFd, path::Path, process::Command;
#[derive(Debug)]
enum SetnsError
IO(io::Error),
Nix(nix::Error),
fn set_ns(ns_path: String, flags: CloneFlags) -> Result<(), SetnsError>
let file = fs::File::open(Path::new(ns_path.as_str())).map_err(SetnsError::IO)?;
setns(file.as_raw_fd(), flags).map_err(SetnsError::Nix)
fn join_namespace(pid: String) -> Result<(), SetnsError>
set_ns(format!("/proc/pid/ns/pid"), CloneFlags::CLONE_NEWPID)?;
set_ns(format!("/proc/pid/ns/ipc"), CloneFlags::CLONE_NEWIPC)?;
set_ns(
format!("/proc/pid/ns/cgroup"),
CloneFlags::CLONE_NEWCGROUP,
)?;
set_ns(format!("/proc/pid/ns/net"), CloneFlags::CLONE_NEWNET)?;
set_ns(format!("/proc/pid/ns/mnt"), CloneFlags::CLONE_NEWNS)?;
Ok(())
fn print_ns(path: &str)
let output = Command::new("/bin/ls")
.arg("-l")
.arg(path)
.output()
.expect("failed to execute process");
if output.status.success()
println!("", String::from_utf8_lossy(&output.stdout));
else
println!("err: ", String::from_utf8_lossy(&output.stderr));
fn main()
let args: Vec<String> = env::args().collect();
if args.len() < 2
eprintln!("Usage: <pid>", args[0]);
std::process::exit(1);
print_ns("/proc/self/ns");
if let Err(e) = join_namespace(args[1].clone())
eprintln!("join namespace failed e:?");
return;
print_ns("/proc/self/ns");
可以看到,进程的 PID、IPC、Cgroup、NET、MNT 命名空间已经设置为容器的命名空间。
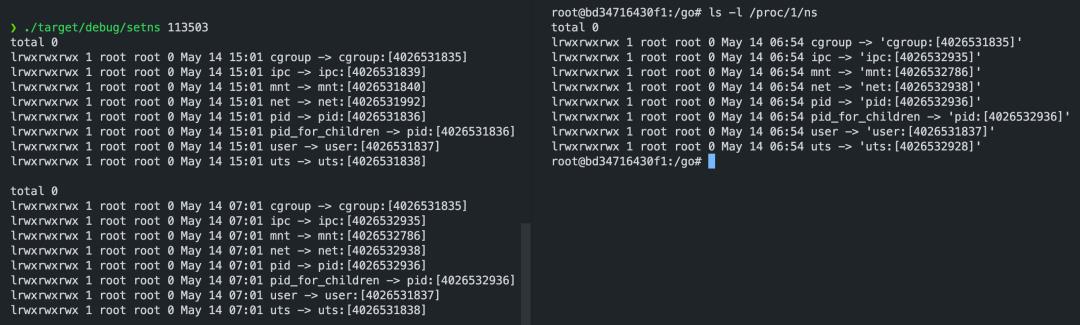
部分细节:
-
如需加入多个命名空间,MNT 命名空间应该最后加入。(先加入 MNT 命名空间会导致接下来的 join 操作无法正确读取原
/proc/pid/ns下的文件) -
在本文使用的测试环境,加入 USER 命名空间会出错,返回 EINVAL 信息。
Nsenter
nsenter 是 linux 中的命令行工具,位于 util-linux[10] 包中,用于进入目标进程的命名空间运行程序。
❯ nsenter --help
Usage:
nsenter [options] [<program> [<argument>...]]
Run a program with namespaces of other processes.
Options:
-a, --all enter all namespaces
-t, --target <pid> target process to get namespaces from
-m, --mount[=<file>] enter mount namespace
-u, --uts[=<file>] enter UTS namespace (hostname etc)
-i, --ipc[=<file>] enter System V IPC namespace
-n, --net[=<file>] enter network namespace
-p, --pid[=<file>] enter pid namespace
-C, --cgroup[=<file>] enter cgroup namespace
-U, --user[=<file>] enter user namespace
-T, --time[=<file>] enter time namespace
-S, --setuid <uid> set uid in entered namespace
-G, --setgid <gid> set gid in entered namespace
--preserve-credentials do not touch uids or gids
-r, --root[=<dir>] set the root directory
-w, --wd[=<dir>] set the working directory
-W. --wdns <dir> set the working directory in namespace
-F, --no-fork do not fork before exec\'ing <program>
进入容器的 PID、Mount 命名空间:
nsenter -m -p -t 113503 bash
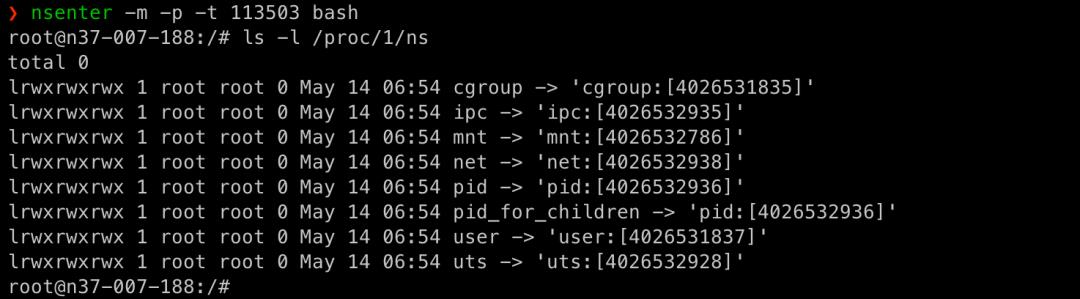
Fanotify 监控容器
-
通过 setns 加入容器所在的 PID、Mount 命名空间;
-
启动 fanotify server;
-
监听到 fanotify 事件,通过 readlink 得到 fd 对应的 path;(由于已经处于容器所在的 PID 命名空间,因此,可以直接通过
/proc/self/fd/fd得到 fanotify 事件 fd 对应的 path) -
Server 通过 stdout 将包含 path 的 fanotify 事件发送给 client;(由于已经处于容器所在 mount 命名空间,不能直接通过 socket 等进程间通信方式传输给 client)
-
client 对 fanotify 事件进行处理。
完整代码参考:optimizer-server[11]。
总结
-
Inotify 支持在节点上监听容器 rootfs 下的目录和文件。
-
Inotify 不支持递归监控子目录和文件。
-
Fanotify 监听 inode 对象和挂载点不支持跨 mount namespace,因此不支持在节点上直接监听容器 rootfs 下的目录和文件。
-
Fanotify(除
directed模式)支持递归监控目录下的子目录和文件。 -
Fanotify 可以借助
setns进入容器所在的 mount 命名空间,通过per-mount模式实现递归监听容器rootfs下的事件。
参考资料
[1]
inode: https://en.wikipedia.org/wiki/Inode
[2]
John McCutchan: http://johnmccutchan.com/
[3]
inotify.7: https://man7.org/linux/man-pages/man7/inotify.7.html
[4]
Fanotify: https://man7.org/linux/man-pages/man7/fanotify.7.html
[5]
linux/fsnotify_backend.h#L185: https://github.com/torvalds/linux/blob/31a371e419c885e0f137ce70395356ba8639dc52/include/linux/fsnotify_backend.h#L185
[6]
fanotify_init.2: https://man7.org/linux/man-pages/man2/fanotify_init.2.html
[7]
mount namespace: https://man7.org/linux/man-pages/man7/mount_namespaces.7.html
[8]
setns: https://man7.org/linux/man-pages/man2/setns.2.html
[9]
pidfd_open: https://man7.org/linux/man-pages/man2/pidfd_open.2.html
[10]
util-linux: https://github.com/util-linux/util-linux/blob/master/sys-utils/nsenter.c
[11]
optimizer-server: https://github.com/containerd/nydus-snapshotter/tree/main/tools/optimizer-server

在主机上更改挂载卷中的文件时,不会在 docker 容器中触发文件系统事件
【中文标题】在主机上更改挂载卷中的文件时,不会在 docker 容器中触发文件系统事件【英文标题】:File system events not triggered in docker container when files in mounted volume are changed on the host 【发布时间】:2019-10-08 09:59:55 【问题描述】:我想在文件更改时使用 nodemon 重新启动我的项目。我认为 nodemon 通过侦听 inotify 事件来触发重新加载 node.js 项目来工作。
项目在 docker 容器中运行,项目文件在挂载的卷中。
例如,从 docker 容器内部编辑项目文件时
docker-compose exec dev vim server.js
nodemon 正常工作并重新启动服务器。
但是,当使用在主机上运行的编辑器时,nodemon 不会获取更改并重新启动程序。
docker 容器中文件的内容确实发生了变化,所以我怀疑以这种方式编辑文件不会触发 FS 事件。
是否可以这样设置,以便在主机上编辑文件会导致 Docker 容器中发生文件系统事件?为什么这还没有发生?
平台信息: Docker for Windows (Hyper-V)node码头集装箱
WebStorm -- 基于主机的编辑器
【问题讨论】:
你是否阅读了关于如何Inotify on shared drives does not work 的 GitHub 问题并参与了警告 INOTIFY ON SHARED DRIVES DOES NOT WORK 的 docker 日志和故障排除指南? @Wyck 我现在有,谢谢! 【参考方案1】:当 Docker 在 Hyper-V 中运行并且更改发生在主机上时,文件系统事件似乎不起作用。但是,可以通过在 nodemon 中启用轮询来解决这个限制:
nodemon -L server.js
在 WebStorm 中,最终被使用的完整命令是
docker-compose run dev node node_packages/nodemon/bin/nodemon.js -L server.js
更多信息: https://github.com/remy/nodemon#application-isnt-restarting
【讨论】:
以上是关于监听容器中的文件系统事件的主要内容,如果未能解决你的问题,请参考以下文章