第一次作业
Posted 20201329魏赫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次作业相关的知识,希望对你有一定的参考价值。
第四章第一次作业
教材上的例程 4.1-4.7
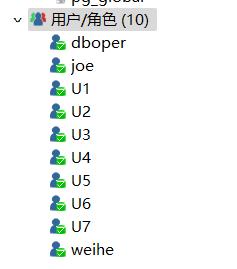
在openGauss上创建用户并进行授权,描述验证的过程
依次创建用户
CREATE USER U1 IDENTIFIED BY \'user@123\';
CREATE USER U2 IDENTIFIED BY \'user@123\';
CREATE USER U3 IDENTIFIED BY \'user@123\';
CREATE USER U4 IDENTIFIED BY \'user@123\';
CREATE USER U5 IDENTIFIED BY \'user@123\';
CREATE USER U6 IDENTIFIED BY \'user@123\';
CREATE USER U7 IDENTIFIED BY \'user@123\';
例题验证
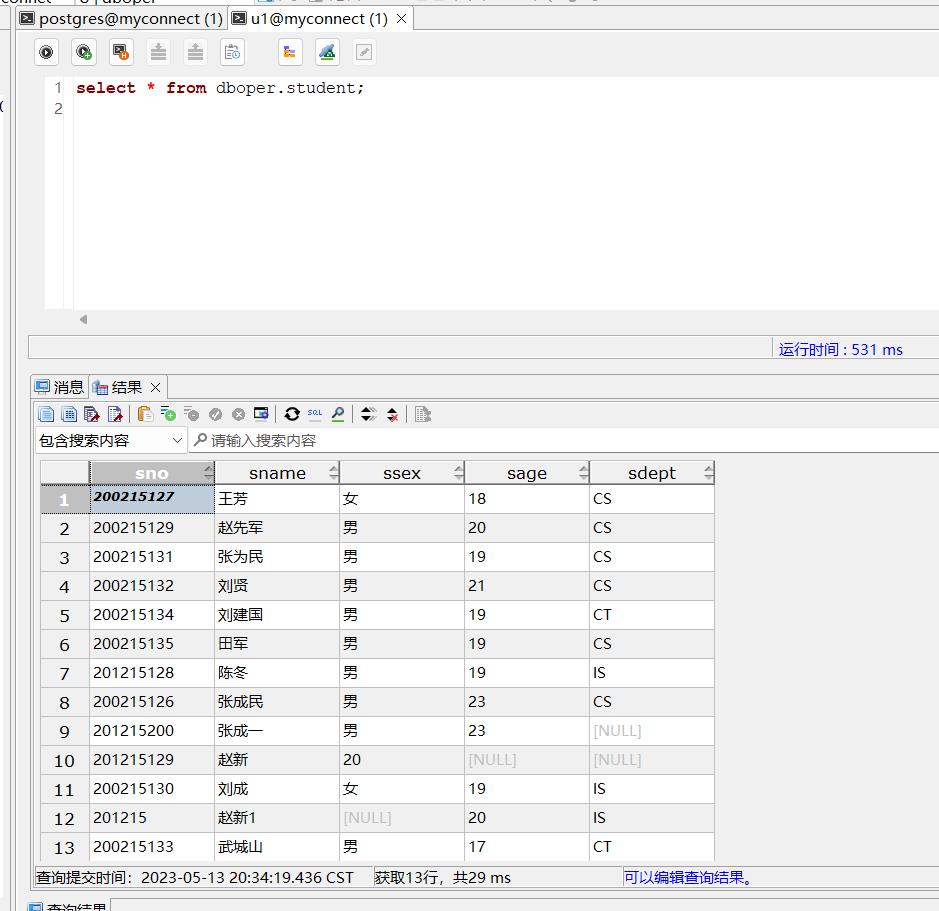
[例 4.1] 把查询Student表权限授给用户U1
grant usage on schema dboper to u1;
grant select on table dboper.student to u1;
如图,可以查询student表
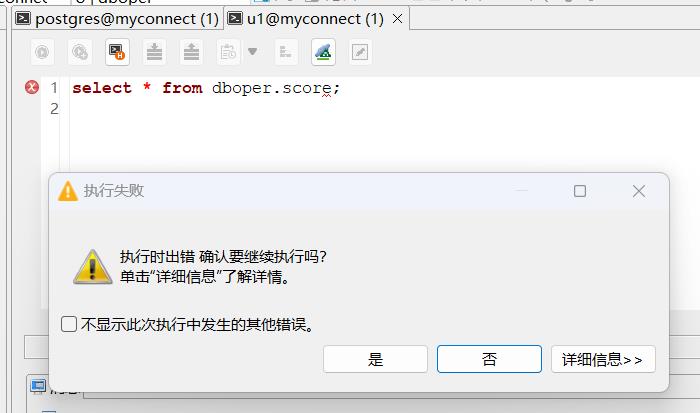
查询score表则失败
[例 4.2] 把对Student表和Course表的全部权限授予用户U2和U3
[例 4.3] 把对表SC的查询权限授予所有用户
[例 4.4] 把查询Student表和修改学生学号的权限授给用户U4
[例 4.5] 把对表SC的INSERT权限授予U5用户,并允许他再将此权限授予其他用户
[例 4.6]-[例 4.7] 传播权限
问题及解决
1.实验上手直接输入例题1代码显示错误,没有事先创建用户。
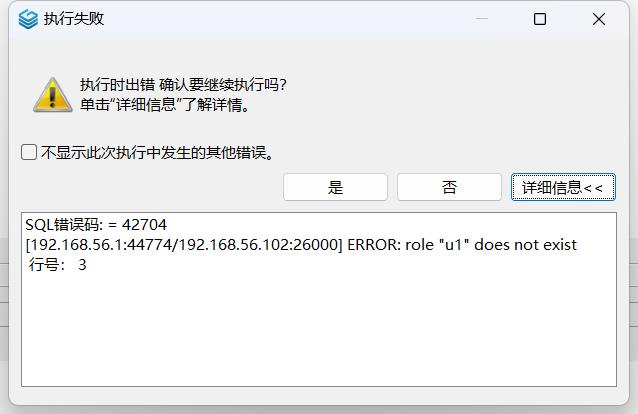
解决:先根据树上的用户数量创建好需要的用户,并且设置密码,再输入代码进行设置权限。
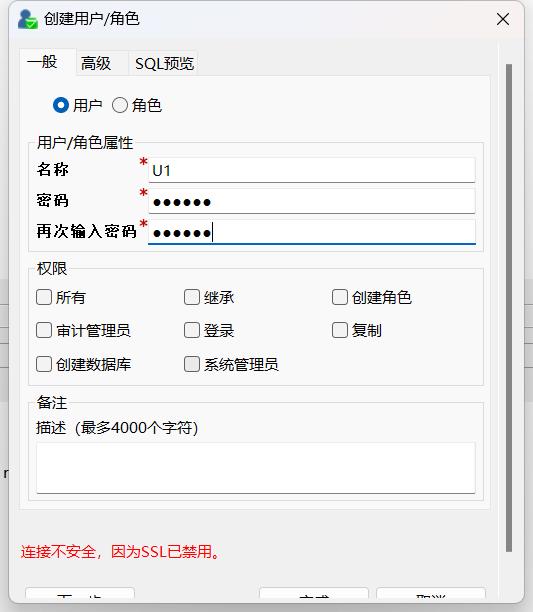
2.创建用户设置密码时,没有使用三种不同类型的字符类型
教材上的例程[例4.8]、[例4.9]、[例4.10]
在openGauss上收回部分用户的权限,描述验证的过程
例题验证
[例 4.8] 把用户U4修改学生学号的权限收回
[例 4.9] 收回所有用户对表SC的查询权限
[例 4.10] 把用户U5对SC表的INSERT权限收回
问题及解决
教材上的例程[例4.11]、[例4.12]、[例4.13]
在openGauss上进行角色部分内容的验证,描述验证的过程
例题验证
[例 4.11] 通过角色来实现将一组权限授予一个用户
[例 4.12]-[例 4.13] 角色的权限修改
问题及解决
第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标 | 实现查重算法+单元测试+性能分析+异常处理+记录PSP表格+熟悉Git |
- 项目代码已上传到作业GitHub,使用python3实现,IDE为pycharm
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1515 | 1980 |
| · Analysis | · 需求分析 (包括学习新技术) | 850 | 1150 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| · Design | · 具体设计 | 120 | 100 |
| · Coding | · 具体编码 | 350 | 550 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 130 |
| Reporting | 报告 | 75 | 65 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 1620 | 2075 |
<由于之前没有接触过python,在开始本项目之前花费了比较多的时间学习新语言>
二、接口的设计与实现过程
- 通过上网了解到论文查重算法实际上就是计算文本的相似度,通过比对各种算法的优缺点,本项目中最终参考了python实现余弦相似度文本比较,具体过程参考该博客。
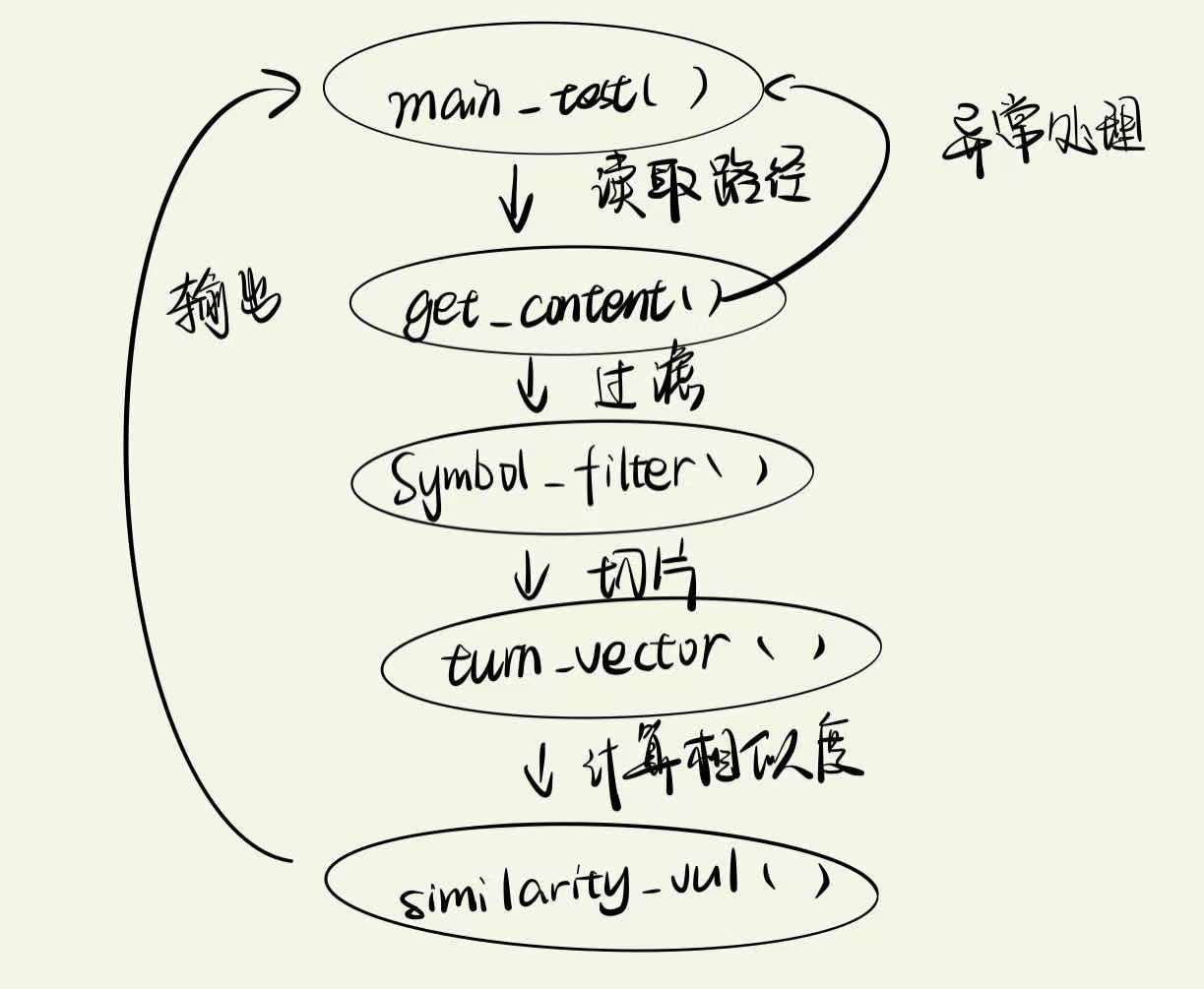
整体思路:读取文件路径,将文件字节流转换成字符串,使用jieba分词后过滤掉标点符等,,根据分词词典通过doc2bow稀疏向量生成语料库,然后直接调用similarity获取文本相似度(省略了计算TF、IDF值、文档向量、权重等步骤),最后将输出结果保存到指定路径。
- 调用库:jieba、re、gensim、os
函数:
- get_content()中读取目标文件字节流,转换成字符串后,调用过滤函数Symbol_filter()。
def get_content(path):
# 文本处理,将我们的文本处理为字符串,并且过滤掉标点符号
string = \'\'
file = open(path, \'r\', encoding=\'UTF-8\')
one_line = file.readline()
while one_line:
string += one_line
one_line = file.readline()
# 调用标点符号过滤函数
string = Symbol_filter(string)
file.close()
return string
# 过滤器
def Symbol_filter(str):
# 使用正则表达式过滤,保留字母与汉字
result = re.compile(u"[^a-zA-Z0-9\\u4e00-\\u9fa5]").sub("", str)
return result
- turn_vector()函数调用jieba.lcut切片后用list保存
# 分词
def turn_vector(str):
# 将字符串使用jieba.lcut切片用list保存
string = jieba.lcut(str)
return string
- 算法关键:similarity_vul()函数调用gensim.corpora获得语料库,利用doc2bow作为词袋模型,调用gensim.similarities.Similarity计算文章相似度
# 计算相似度
def similarity_vul(str_x, str_y):
texts = [str_x, str_y]
# 使用gensim.corpora获得语料库
dictionary = gensim.corpora.Dictionary(texts)
# 利用doc2bow作为词袋模型
corpus = [dictionary.doc2bow(text) for text in texts]
# 通过token2id得到特征数(字典里面键的个数)
num_features = len(dictionary.token2id.keys())
sim = gensim.similarities.Similarity(\'-Similarity-index\', corpus, num_features)
# 获取文章相似度
test_corpus = dictionary.doc2bow(str_x)
cosine_sim = sim[test_corpus][1]
return cosine_sim
流程图:
三、接口部分的性能改进
下图为程序执行过程中方法被调用的次数及执行时间的统计表,由表可见:
调用次数最多的是计算相似度的时候将字符串生成语料库时用的gensim.corpora.Dictionary()方法;总耗时最长的是分词的时候用的cut()方法

- 一开始过滤器用的是for循环过滤掉符号等无用文本,后面考虑到for循环的复杂度在冗长的文本中会非常高,就调用了re.compile()方法,使用正则表达式作为筛选条件,大大提高了性能。
result = re.compile(u"[^a-zA-Z0-9\\u4e00-\\u9fa5]").sub("", str)
- 刚开始的时候执着于按照作业要求里的用命令行输入三个对应要求的路径,虽然用的方法也很简单但是感觉用户的体验感不是很好,就换成了命令行分别提示用户输入三个路径,用户体验提高了,也方便后面写单元测试
# 为了方便命令行输入,这里加了一些提示性文本使用户体验更加友好
txt_1 = input("参考论文的绝对路径:")
txt_2 = input("待检察文件的绝对路径:")
# 输出结果的文件路径
save_path = input("保存结果的绝对路径:")
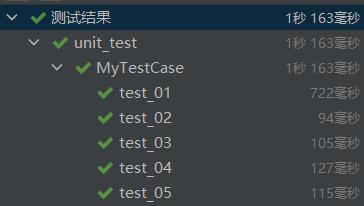
四、部分单元测试展示
- 单元测试覆盖率符合要求:

- 得出结果的时间符合要求:
- 展示比对前两个文件的相似度

五、部分异常处理说明
本人打码的过程比较曲折,一开始是打算在Anoconda上写的,结果不知为何各种报错,挣扎了几天之后转战VSCode,又是因为某种百度也无法解决的问题而中道崩殂,最后转战pycharm,用下来几天的时间,只能说这个软件算是非常好用了的。各种插件也是比较齐全。以下是打码中遇到的一些异常以及处理。
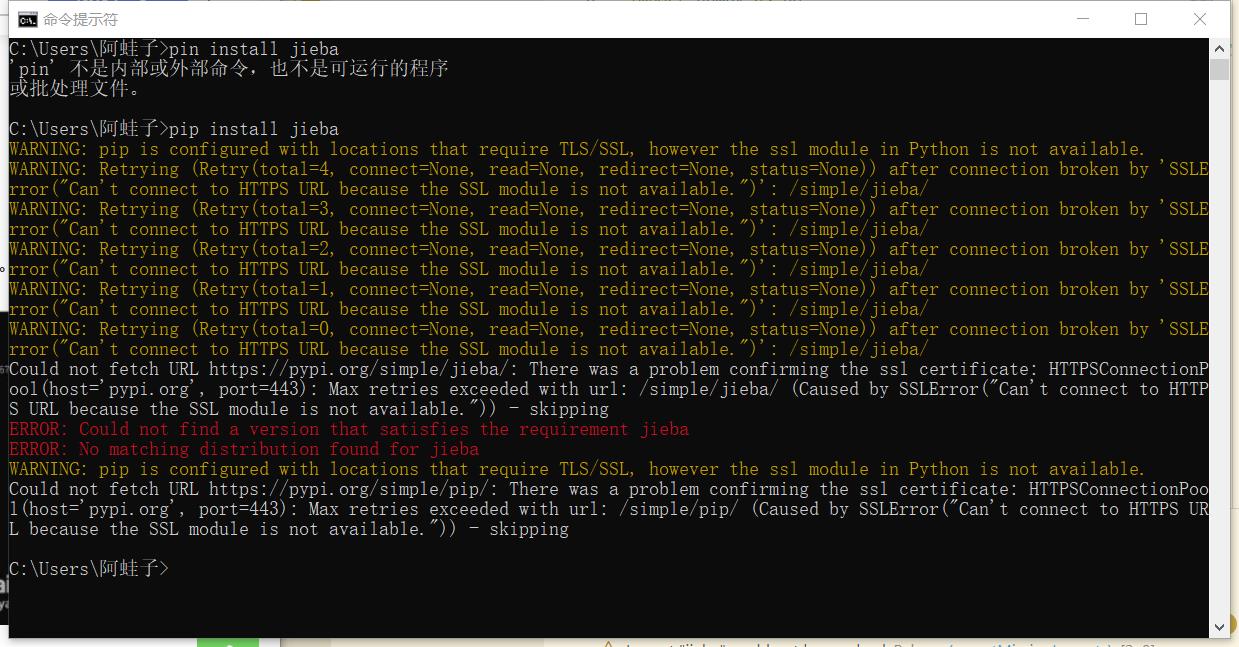
- 无法下载jieba库--最后通过镜像网站的方法解决了
-
测试单元文件中无法调用TestCase--文件名与库名冲突了导致循环调用陷入死锁
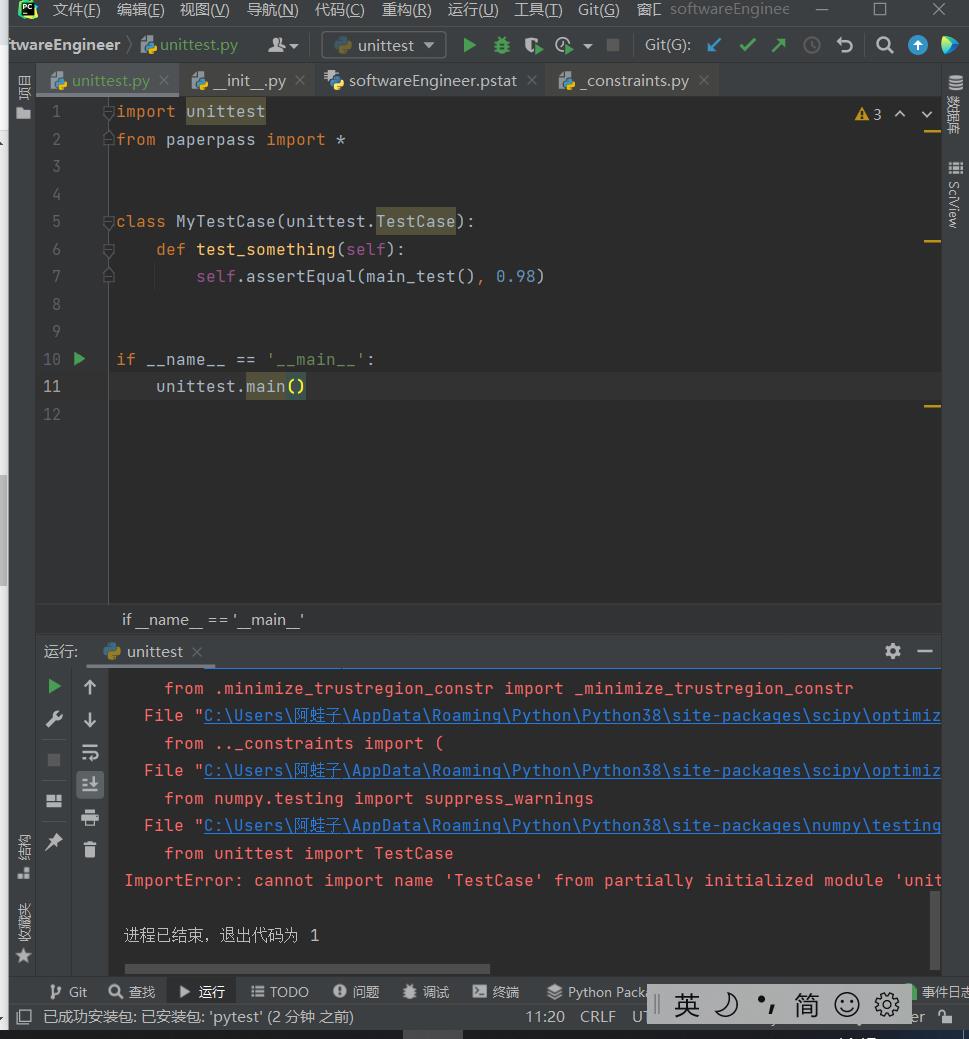
-
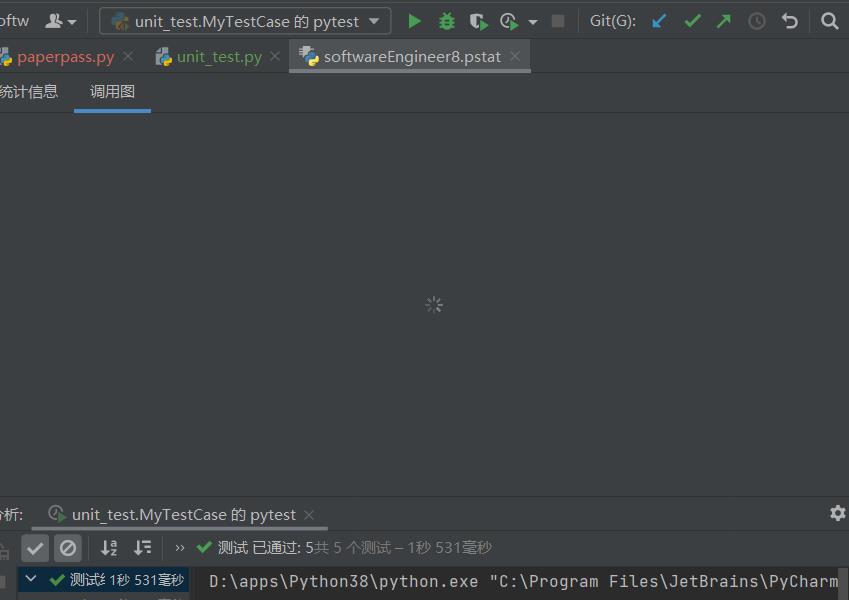
profile配置文件生成不了函数调用图--尚未解决
- 代码的异常处理方面没遇到什么其他的,就把文件路径输入这一块细分了些
if not os.path.exists(txt_1):
print("参考论文文件不存在!")
exit()
if not os.path.exists(txt_2):
print("待检察文件不存在!")
exit()
if not txt_1.endswith(\'.txt\'):
print("参考论文文件格式错误!")
exit()
if not txt_2.endswith(\'.txt\'):
print("待检察文件格式错误!")
exit()
if not save_path.endswith(\'.txt\'):
print("输出结果文件格式错误!")
exit()
if os.path.getsize(txt_1) == 0:
print("参考论文文件为空!")
exit()
if os.path.getsize(txt_2) == 0:
print("待检察文件为空!")
exit()
六、个人总结
由于本学期才开始学习python,并且在此之前个人独立编程时间屈指可数,所以熟悉代码开发流程花了较长的时间,加上其他课程的作业也比较多,导致最后完成项目的时间剩的不是很多,基本上这几天都在赶ddl了,所以提交上去的代码并不是很完善,这也算是一点小遗憾吧。希望通过之后更深入的学习python以及软件工程,能够回过头来发现自己这段青涩的代码的其他改进之处。
通过本次作业,我了解了几种常用的计算文本相似度的方法,并利用其中一种(余弦相似度)做出了本次项目,掌握了小型程序开发的基本流程,提高了编程能力,学会了利用PSP表格进行自我评估,更进一步的学习了github的使用,相信在不久的将来我能通过不断学习,自己找到软工5问的答案。
以上是关于第一次作业的主要内容,如果未能解决你的问题,请参考以下文章