python 爬虫 scrapy框架的使用 一
Posted 廉少
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫 scrapy框架的使用 一相关的知识,希望对你有一定的参考价值。
1 首先 安装 scrapy :
pip install scrapy
2 用命令创建一个spider工程:
scrapy startproject spider5
3 创建一个spider文件,并指定爬虫开始的域名:
scrapy genspider spider1 “www.baidu.com”
4开启爬虫:
scrapy crawl spider5
创建好的工程结构如下图:
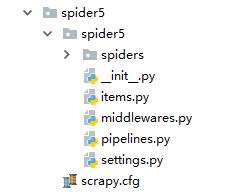
其中spiders里面的为爬虫文件,items.py为爬虫数据模型定义文件,用于定义一些数据存储的类别,pipelines.py为管道文件,用于接收item的返回值,处理后将item保存到本地或者数据库中
scrapy的工作原理图如下:
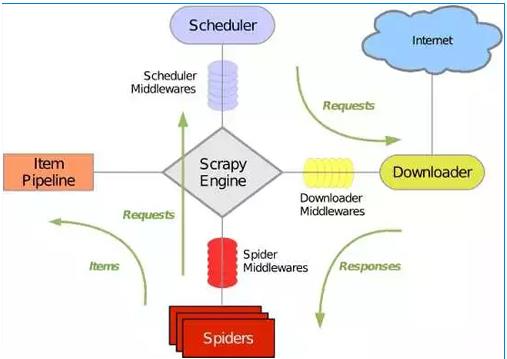
1 首先 spider1文件会将start_urls中的请求连接发给 引擎,然后引擎将这些请求传递给调度器(Scheduler),调度器接收这些请求链接并将它们入队列
2 然后通过引擎讲这些处理好的请求链接交给下载器去下载
3下载器将下载的结果通过引擎差传递给spiders进行数据解析,并返回一个item
4引擎将spiders的返回结果传递给管道文件(ItemPIpeline) ,管道文件接收数据将数据存储
以上是关于python 爬虫 scrapy框架的使用 一的主要内容,如果未能解决你的问题,请参考以下文章