MySQL多列字段去重的案例实践
Posted chuangsi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL多列字段去重的案例实践相关的知识,希望对你有一定的参考价值。
网名 bisal ,具有十年以上信息系统建设经验,目前主要从事数据库应用研发能力提升和技术管理方面的工作,Oracle ACE (Alums),腾讯云TVP,墨天轮MVP,拥有Oracle OCM & OCP、EXIN DevOps Master 、SCJP、OBCA、腾讯云CloudLite、PCSD、GDCA等技术认证,国内首批Oracle YEP成员,OCMU成员,《DevOps 最佳实践》中文译者之一,CSDN & ITPub专家博主,公众号"bisal的个人杂货铺",长期坚持分享技术文章,多次在线上和线下分享技术主题。
本文来源:原创投稿
* 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
同事提了个需求,如下测试表,有code、cdate和ctotal三列,
select * from tt;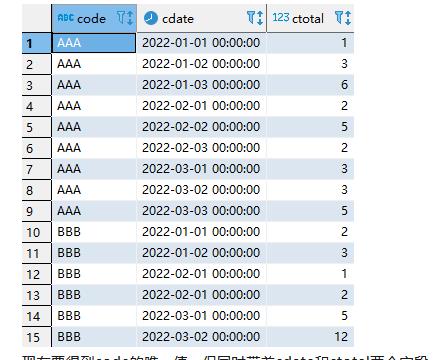
现在要得到code的唯一值,但同时带着cdate和ctotal两个字段。提起"唯一值",想到的就是distinct。distinct关键字可以过滤多余的重复记录只保留一条。distinct支持单列去重和多列去重,如果是单列去重,简明易懂,即相同值只保留1个,如下所示,
select distinct code from tt;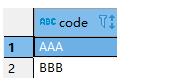
多列去重则是根据指定的去重列信息进行,即只有所有指定的列信息都相同,才会被认为是重复的信息,如下所示,code、cdate和ctotal都相同,才会返回记录,因此不是字面上的理解,即只要code是distinct的,cdate和ctotal无需关注。实际上当distinct应用到多个字段的时候,其应用的范围是其后面的所有字段,而不只是紧贴着它的一个字段,即distinct同时作用了三个字段,code、cdate和ctotal,并不只是code字段,
select distinct code, cdate, ctotal from tt;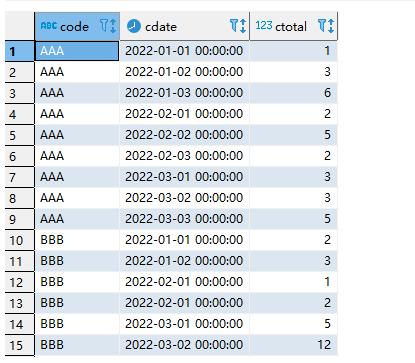
而且distinct只能放到所有字段的前面,如果像这种,distinct之前有其它字段,则会提示错误,
但是如上SQL使用distinct关键字,并没有满足需求,即得到code的唯一值,但同时带着cdate和ctotal两个字段,可以看到有很多相同的code。除了distinct,group by子句也可以去重,从需求的理解上,如果按照code做group by,应该就可以得到唯一的code了,但是实际执行,提示这个错误,select cdate, ctotal, distinct code from tt;SQL 错误 [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near \'distinct code from tt\' at line 1
select code, cdate, ctotal from tt group by code;SQL 错误 [1055] [42000]: Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column \'test.tt.code\' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
很常见的错误,因为sql_mode中含only_full_group_by规则,
only_full_group_by规则是指对group by进行查询的SQL,不允许select部分出现group by中未出现的字段,也就是select查询的字段必须是group by中出现的或者使用聚合函数的,即校验更加严格。P.S. MySQL不同版本sql_mode默认值可能是不同的,因此在数据库升级配合的应用迁移过程中,尤其要注意像only_full_group_by这种校验规则的改变,很可能是个坑。仅针对当前这个问题,可以在会话级,修改sql_mode,调整校验的强度,删除only_full_group_by,show variables like \'%sql_mode%\';ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
set session sql_mode=\'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION\';此时,使用group by,
select code, cdate, ctotal from tt group by code;就可以得到想要的效果了,

除了group by,还可以使用group_concat函数,配合distinct,达到相同效果。
我们分解来做,可以看到group_concat(code),得到的是所有记录的code值拼接成新字段,
select group_concat(code), cdate, ctotal from tt group by code;
group_concat中加上distinct,就可以过滤所有的重复值,满足了需求,
select group_concat(distinct code), cdate, ctotal from tt group by code;
当然,这种在会话级通过改动sql_mode实现的路径,还需要考虑场景,因为缺少only_full_group_by的校验,按照code聚类了,但cdate和ctotal的值很可能是不唯一的,返回的结果,只能准确描述code的数据情况,不能代表cdate和ctotal的真实数据情况。因此,任何方案的选择,都需要结合实际的场景需求,我们找的方案,不一定是最好的,但需要最合适的。
本文关键字:#SQL# #去重#文章推荐:
关于SQLE
爱可生开源社区的 SQLE 是一款面向数据库使用者和管理者,支持多场景审核,支持标准化上线流程,原生支持 MySQL 审核且数据库类型可扩展的 SQL 审核工具。
SQLE 获取| 类型 | 地址 |
|---|---|
| 版本库 | https://github.com/actiontech/sqle |
| 文档 | https://actiontech.github.io/sqle-docs-cn/ |
| 发布信息 | https://github.com/actiontech/sqle/releases |
| 数据审核插件开发文档 | https://actiontech.github.io/sqle-docs-cn/3.modules/3.7_auditplugin/auditplugin_development.html |
MySQL_select distinct无法实现只对单列去重,并显示多列结果的解决方法
参考技术A 可以看到表中的value字段有重复,如果想筛选去重,使用select distinct语句如下:得到结果会是
| value
| a
| b
| c
| e
| f
筛选去重是实现了,可是只有选中的value列显示了出来,如果我想知道对应的id呢?
尝试一下把id字段加入sql语句,如下:
得到结果:
| value | id
| a | 1
| b | 2
| c | 3
| c | 4
| e | 5
| f | 5
更换一下sql语句中id和value的顺序,如下:
得到结果:
| id |value
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | e
| 5 | f
好像看明白它的作用结果了,只有id和value两个字段同时重复时,select distinct语句才会把它列入“去重”清单
所以能看到id为3和4的value虽然都是4,但由于select语句中写了id字段,它也默认会对id字段起效。
而且如果sql语句中把DISTINCT放到只想起效的字段前,那也是不行的....比如sql语句改为:
会提示sql报错。
那到底怎么样能得到我想要的只对value字段内容去重,显示结果又能保留其他字段内容呢....
找到的解决方法是使用group by函数,sql语句如下:
得到结果:
| min(id) |value
| 1 | a
| 2 | b
| 3 | c
| 5 | e
| 5 | f
完成目标了✔!
如果把sql语句中的min()换成max()呢?
得到结果:
| min(id) |value
| 1 | a
| 2 | b
| 4 | c
| 5 | e
| 5 | f
也完成目标了✔!
同时比对两次sql运行结果可以发现,
第一次使用min(id)时,由于重复结果存在两条而id最小的为为3,符合min(id)的筛选条件,所以结果中把id等于4的重复记录删除了。
第二次使用max(id)时结果中,也就把id等于3的重复记录删除了
可以推论到假如还存在一条id=5,value=c的记录,使用max(id)时得到的结果里就会是>5 c这条了。
再来尝试一下,如果min()和max()用在value字段里呢:
得到结果:
| id |min(value)
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | e
得到结果:
| id |min(value)
| 1 | a
| 2 | b
| 3 | c
| 4 | c
| 5 | f
再仔细想想,这种需求也只出现在不是那么care显示结果中,非去重目标字段的内容时才能使用,如果需要指定这些字段的值,可能筛选条件就不是min()和max()那么简单了....
以上。
以上是关于MySQL多列字段去重的案例实践的主要内容,如果未能解决你的问题,请参考以下文章