Python 随笔
Posted 斩毛毛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 随笔相关的知识,希望对你有一定的参考价值。
(1):字典中,get的用法

若该值无value,缺省值可随意设定。。。。如:d[color] = d.get(color, "hi")
(2)sorted 用于排序,可形成副本
lis = ["red", "blue", "pep", "yellow"]
print(sorted(lis, key=len, reverse = True))
key按长度排序,True表示降序,False表示升序
(3) eval exec
eval:字符串求值并返回结果,不支持任何形式赋值操作,如eval(“2*3”)结果返回6
exec;执行字符串中的内容,exec(“print("adc")”)。结果adc
(4)heapq库,以及Counter
heapq可以取自定义的最大或者最小值个数,
eg:a = [1,2,3,4,5,6,7]
heapq.nlargester(2,a). 结果为[6,7] 取出列表a中最大的两个数字
Counter可以计算一个列表中数字出现的次数
eg:
from collections import Counter
a = [11,2,2,3,4,5,6,6,7,8,8]
Counter(a)
结果:Counter({2: 2, 6: 2, 8: 2, 3: 1, 4: 1, 5: 1, 7: 1, 11: 1}) 一个字典形式。
(5)if else
>>a = 2
>>b = 1
>>print(1 if a >b else 2)
>>1
>>print(n if n>4 else n-1 for n in range(10) if n%2==0)
>>[-1, 1, 3, 6, 8]
(6)若遇到unhashbale..则取一个临时变量代替
(7) 若想用python2 除法得到小数,则需要添加一个模块
from __future__ import division
这样做除法就会得到真实值
(8) 若一个字符串“46.33”,想要变成46.33, 不能用int(), 而应该是float,因为“46.33” 是一个字符串中的float
(9)若想读基因组数据时,如:以下格式

不可用如下代码,
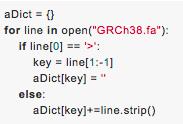
(将字符串一直追加在后面,因为字符串是不可更改的,每一次叠加,需要开辟一块新的内存,如果有40万行,那么需要开辟40万次)
应该用列表,如下代码

(因此列表追加是,不会开辟新的内存,每一次追加用的是相同的内存地址),速度非常快
(10) 循环高级用法
最基础的列表推倒式。 [x**x for x in L]
a. 带有if语句
在for后面添加if语句,用来判断
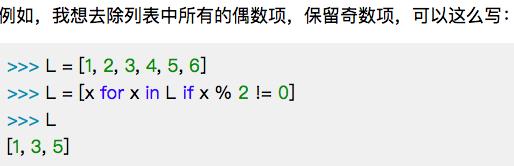
b.带有for嵌套
嵌套时,按照从左到右顺序,分别是外层循环到内层循环

c. 既有if语句又有for嵌套
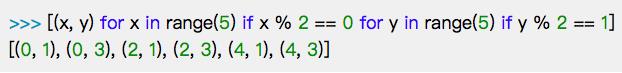
d. 子列表中项目的子列表项目
公式:sentences=[y for x in sentences for y in x]
其作用,将列表展平,,其实和for嵌套类似,可理解为输出一个结果的for嵌套
比如:从左到右,从外层循环到内层循环

e.

(11) zip() 函数
1 ##合并list,得到元组的列表
2 a = [1,2,3]
3 b = [1,2,3]
4 zip(a,b)
5 得到:[(1, 1), (2, 2), (3, 3)]
6
7 ## 添加*,可对list中的元素进行组合
8 all = [[1, 2, 3], [1, 2, 3], [1, 2,3]]
9 zip(*all)
10 得到:[(1, 1, 1), (2, 2, 2), (3, 3, 3)]
以上是关于Python 随笔的主要内容,如果未能解决你的问题,请参考以下文章