CQRS读写分离MySQL数据库如何部署至Linux
Posted C#郭小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CQRS读写分离MySQL数据库如何部署至Linux相关的知识,希望对你有一定的参考价值。
分库分表简单实现(FearlessGuo)
首先有一台可以使用的Linux服务器,可以自行购买,当然也可以白嫖。
有一款可以连接Linux的软件,我用的是putty
在Linux上下载docker镜像,类似应用商店。安装过程参阅下方链接
Linux安装Docker完整教程_docker安装_风随心飞飞的博客-CSDN博客
下载mysql镜像,查看版本
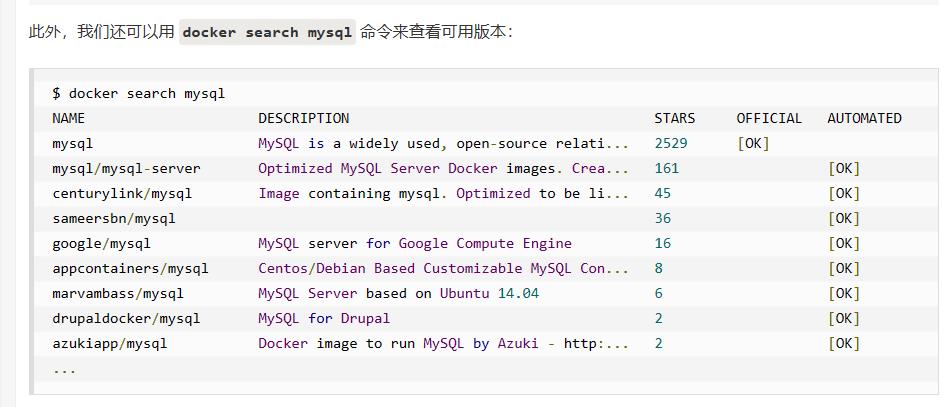
本次使用版本5.7
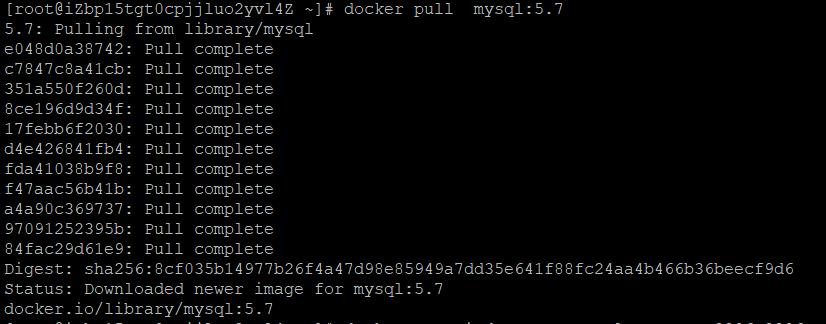
配置mysql的容器,每个容器就像是一台新的电脑,相互独立各不相同
实现dome:
--name后的内容可以修改
密码可以不为123456
结尾mysql为镜像名称,唯一可以只写name,不唯一也可以用id进行使用
这两段demo都可以创建容器,具体区别不清楚,多尝试一下,一个用不了就换一个。
1
docker run -itd --name mysql-test -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
2
docker run -p 3312:3306 --name mymysql -v $PWD/conf:/etc/mysql/conf.d -v $PWD/logs:/logs -v $PWD/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
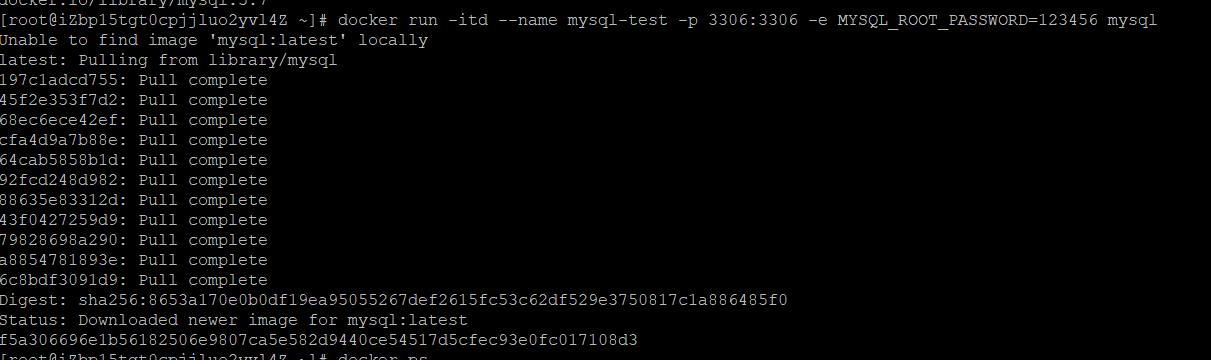
Docker ps 查看运行镜像
Docker ps -a 查看所有镜像

测试mysql容器是否正常
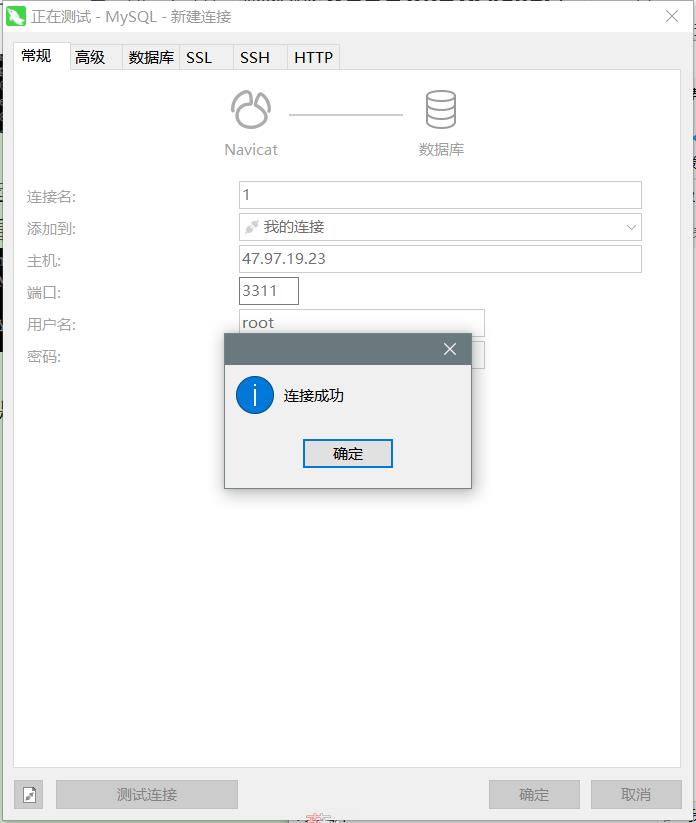
如果连接失败了
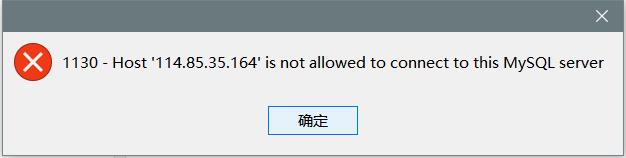
参阅以下文章:
MySQL 异常: "Host \'xxx\' is not allowed to connect to this MySQL server"_mazaiting的博客-CSDN博客
下面我们配置数据库主从模式(可以当成读写分离)
- 我们专用的挂载好的容器(切记不要使用相同端口号,名字也不要相同)
//参数详解// -d守护进程// -p端口映射 -p 宿主机端口:容器端口// --privileged=true 应用容器 获取宿主机root权限// -v 绑定共享映射目录,-v 宿主机目录:容器目录
//主库
docker run -d -p 3322:3306 --privileged=true -v ~/docker_data/mysql-master/log:/var/log/mysql -v ~/docker_data/mysql-master/data:/var/lib/mysql -v ~/docker_data/mysql-master/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql-master mysql
//从库
docker run -d -p 3324:3306 --privileged=true -v ~/docker_data/mysql-slave/log:/var/log/mysql -v ~/docker_data/mysql-slave/data:/var/lib/mysql -v ~/docker_data/mysql-slave/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql-slave mysql
//可以多个从库
docker run -d -p 3325:3306 --privileged=true -v ~/docker_data/mysql-salve/log:/var/log/mysql -v ~/docker_data/mysql-salve/data:/var/lib/mysql -v ~/docker_data/mysql-salve/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql-salve mysql
下面我们需要配置Linux挂载文件夹里的文件
这里主库和从库的都已经备注好了
//**主库配置** 这里在宿主机更新配置文件后,容器也会同步更新//在刚刚共享映射的宿主机conf目录新建my.cnf 写入以下内容//我的目录是:/docker_data/mysql-master/conf/my.cnf teps:不需要复制这段话
[mysqld]
## 设置server_id 同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,stateement,row)
binlog_format=mixed
## 二进制日志过期清理时间 默认值为0 表示不自动清理
expire_logs_days=7
## 跳过主从复制值遇到的所有错误或指定类型的错误,避免slave端复制中断## 如:1062错误是指一些主键重复 1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
//**从库配置** 这里在宿主机更新配置文件后,容器也会同步更新//在刚刚共享映射的宿主机conf目录新建my.cnf 写入以下内容//我的目录是:/docker_data/mysql-slave/conf/my.cnf teps:不需要复制这段话
[mysqld]
## 设置server_id 同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,stateement,row)
binlog_format=mixed
## 二进制日志过期清理时间 默认值为0 表示不自动清理
expire_logs_days=7
## 跳过主从复制值遇到的所有错误或指定类型的错误,避免slave端复制中断## 如:1062错误是指一些主键重复 1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志中
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
如多多个从库变一下server_id就可以了只要不重复就行。想的话可以多设置几个小弟,搞两个给你们演示一下。
这是一个事例,其他的照着写就行。
下面一步一步进入主库(对主库创建slave用户)成功以后可查看是否创建了slave
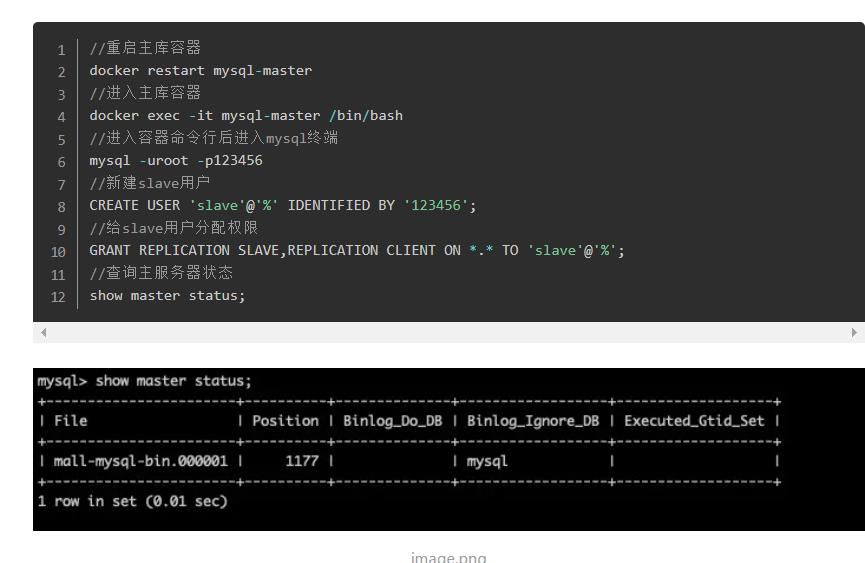
Exit退出容器,去从库容器中进行配置
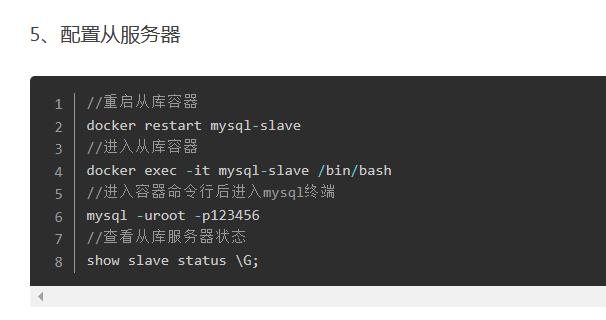
如果没报错的话会出来这样一个会话框
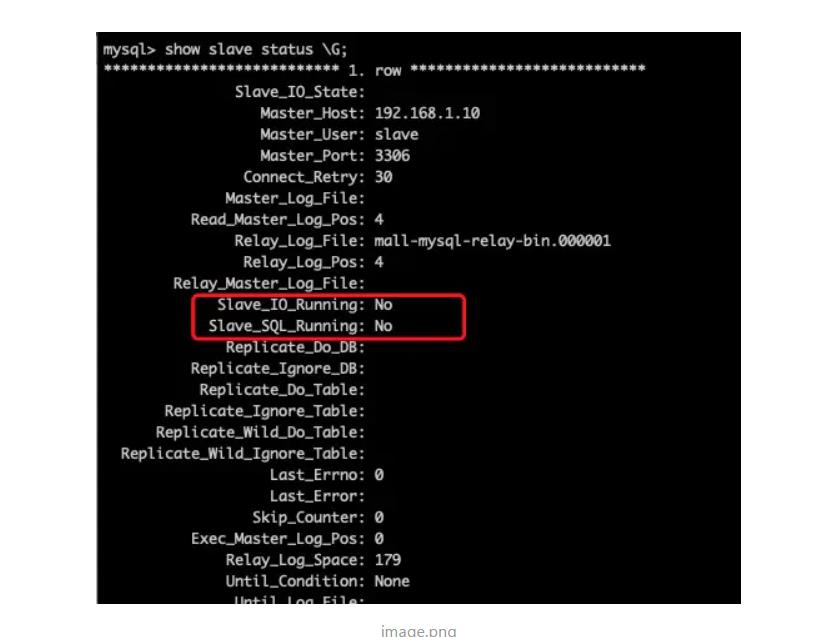
我们可以看见这两个状态是关闭的。
可能运行会有报错,empty,没关系这是我们少写了一段话,加上就行。
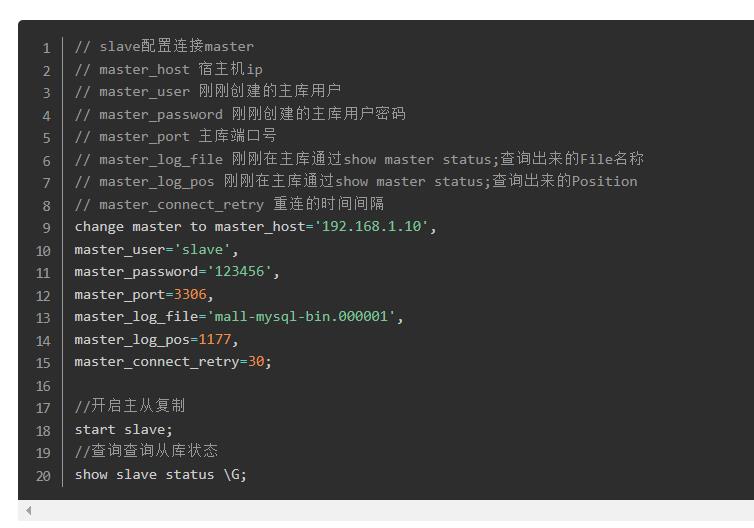
change master to master_host=\'47.97.19.23\', master_user=\'slave\', master_password=\'123456\', master_port=3322, master_log_file=\'mall-mysql-bin.000001\', master_log_pos=371, master_connect_retry=30;
这边需要最长的dome很贴心的放到这里了。切记一行代码,不能换行!!!!
当然如果直接复制粘贴的话,肯定报错。
需要修改一下port,为你主服务器的端口
还有其他的东西,自己看看去。
//开启主从复制
Start slave;
//查询从库状态
Show slave status \\G;
此处的状态已经为yes了说明我们已经配置成功了
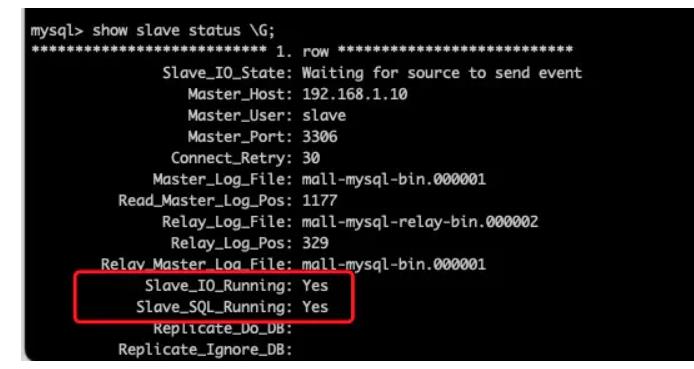
这时候你的数据库就不是一个了,主库后面跟俩小弟,非常哇塞。
在主mysql里创建test数据库两个小弟也就有了
浅析CQRS的应用部署
CQRS,中文翻译命令和查询职责分离,它是一种架构,不仅可以从数据库层面实现读写分离,在代码层面上也是推荐读写分离的。在接口上可以更为简单
命令端定义
ICommandResult Execute(ICommand command)
查询端定义
IQueryResult Fetch(IQuery query)
它的好处是CQ每端对外只有一个接口,职责单一。带来的不便就是要定义好多命令(Command)和查询(Query)对象。但相比定义好多个接口个人觉得还是这样的方式更好。
CQRS不是一个特别炫丽的架构,我觉得他更多的是为了解决数据显示的复杂性。在实际项目中,往往是要查询的数据非常复杂和多样性(也许你并不认同),这样就可以针对查询定义相对需要的ReadModel,也可以设计多个有针对性的读库。
当我们的应用程序开发完之后就需要发布部署了,在部署之前你的应用程序需要有个宿主可以对外提供服务,它可以是WebService,Wcf,WebApi等等。
单机
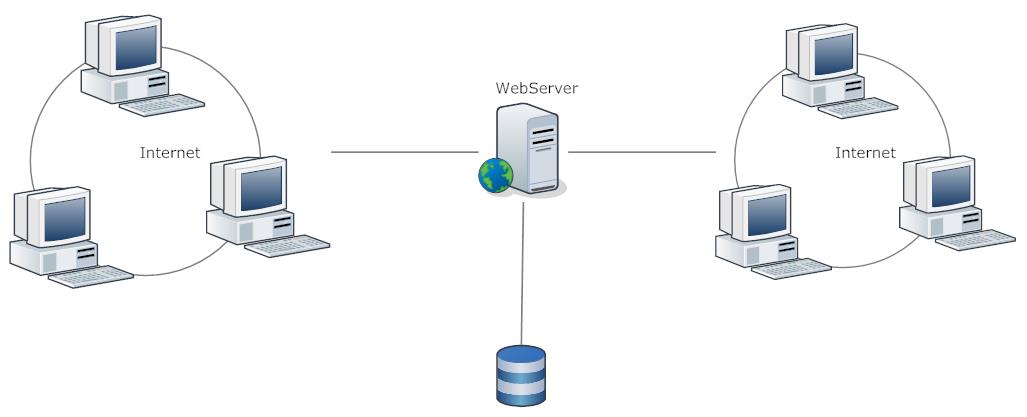
单机是一个最简单的部署方式,优点是维护和部署起来很方便, 缺点是一旦宕机你的整个服务将不可用,处理能力有限,更新应用程序可能要停止服务。
集群
最简单的方式是部署多个单机,利用DNS轮询就可以实现简单的负载均衡,这种方案的缺点就是存在会话丢失,这是因为上一次的会话是在服务器1上,可能下一次的会话DNS就会将域名指向服务器2上,可以采用Cookie或者其他方案解决这一问题。还有就是这一集群方式在处理并发上难度较大,当然也可以采用乐观锁和数据库的悲观锁机制,不过这会带来性能问题。
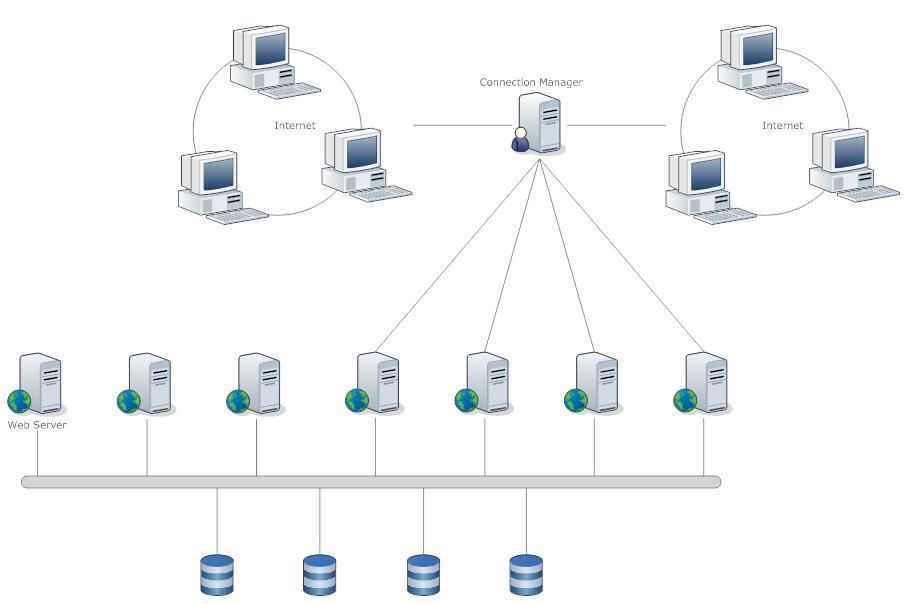
上图只是对单机集群的一种扩展,Connection Manager负责管理与客户端的连接及请求,然后将具体的命令和查询转发到具体的Server,以达到负载均衡的目的,同时它可以将处理相同命令的请求路由到同一个服务器上,可以初步解决并发问题。这种方案也有点类似ngixn,缺点就是带宽压力较大
分布式
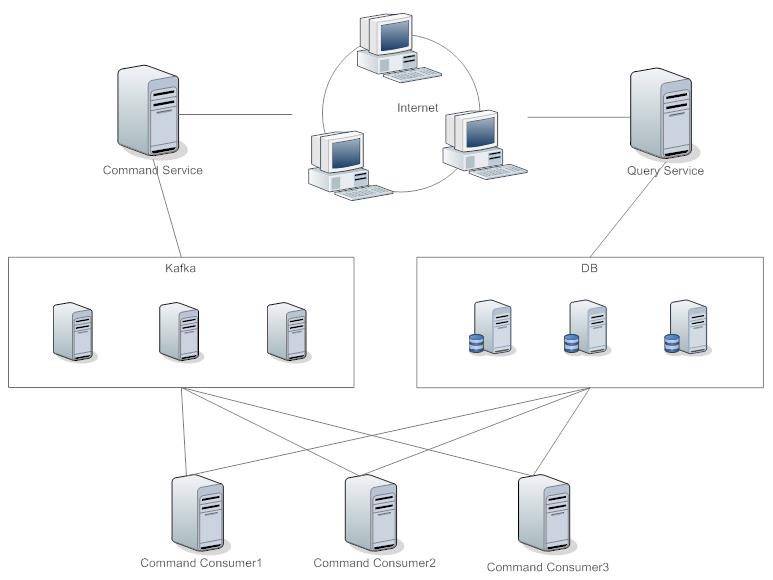
上图的部署方式将命令和查询服务严格区分开来,利用消息队列达到流量削锋、应用解藕和异步处理的目的。命令服务接收到命令后将其发送到Kafka,将相同类型的命令发送到同一topic中,再根据Key分发到不同的partition上,利用Kafka的Rebalance动态添加消费服务,这样的话就可以当请求过多时增加服务,闲时减少服务,非常灵活。
个人觉得这样的部署有类似微服务,在此基础上还可以分离出ValidationService和AuthenticationService等,如CommandService接收到命令后通过验证服务后再发送到Kafka中,同时也是将软件层面的AOP替换成服务层面,每个CommandConsumer像是一个黑盒,外部无法访问。
简单的示例可以参考 https://github.com/imyounghan/umizoo/tree/master/src/Samples
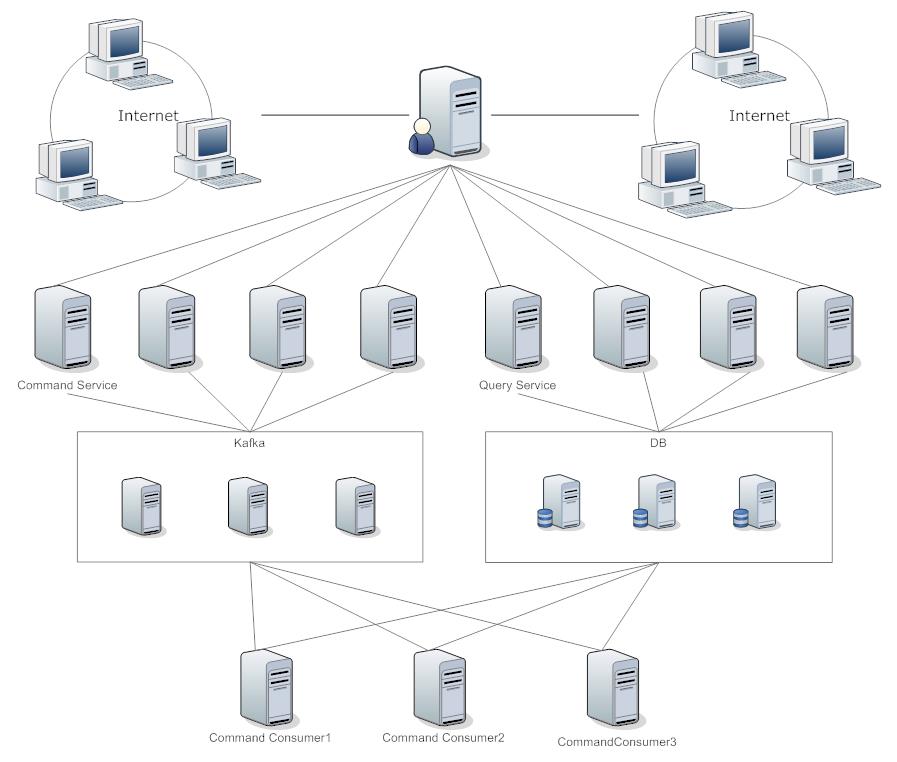
上图是对图2和图3的一个整合,利用了各自的优点。还有一种方案就是Connection Manager提供给客户端一个可用的CommandService或QueryService与客户端进行直连,这样可以避免所有的请求都要经过Connection Manager,减轻Connection Manager的带宽压力,可以参照P2P的思路。
采用了分布式后会导致服务增多,问题也会增多,管理起来也会变得复杂,可以借助Zookeeper来管理监控这些服务。总之分布式情况下要考虑的问题会有很多,本文也无逐一续清,需要掌握的知识点也较多。
以上是关于CQRS读写分离MySQL数据库如何部署至Linux的主要内容,如果未能解决你的问题,请参考以下文章