python web 2
Posted junkdog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python web 2相关的知识,希望对你有一定的参考价值。
思路整理
过程:请求豆瓣电影 top 250 url=‘https://movie.douban.com/‘
结果:得到网页的html 源码 (保存为hml文件 就可以用浏览器打开)
提示:
Location
WEB 服务器告诉浏览器,试图访问的对象已经被移到别的位置了,到该头部指定的位置去取。
例如:Location:http://i0.sinaimg.cn/dy/deco/2008/0528/sinahome_0803_ws_005_text_0.gif
第一步:得到指定URL,解析url,这是准备工作
使用函数:parsed_url()
为什么解析? 我们需要的是 它的协议--http/https
他的host port path (如下图 )

ok 原因我们明白了 那我们怎么实现的
一会儿有空再说 我们需要接着验证其他步骤 去理解这个过程,这个更重要
第二步:获取 URL 这才进入主题 这个主题分几个步骤完成
首先函数get(url)从parsed_url() 中获取到几个解析完成的关键值:protocol, host, port, path
执行步骤A
函数 socket_by_protocol(protocol),根据协议返回一个socket实例,什么事socket实例
(Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求)
由socket的作用 认为此条程序在内容是进行http 和 https的判别(因为HTTPS 协议需要使用 ssl.wrap_socket 包装一下原始的 socket)
实质上是为网络访问奠定基础即创建socket
s.connect((host, port)): connect()用于建立与指定socket的连接。
执行步骤B(强行分出步骤hhhh)
request = ‘GET {} HTTP/1.1 host: {} Connection: close ‘.format(path, host) 构造一个http 请求
(其中Connection 头(header) 决定当前的事务完成后,是否会关闭网络连接。如果该值是“keep-alive”,网络连接就是持久的,不会关闭,
使得对同一个服务器的请求可以继续在该连接上完成。)
执行步骤C
encoding = ‘utf-8‘
s.send(request.encode(encoding))
浏览器和服务器之间发送的信息是以二进制bytes格式存在的,所以发送前要先将str格式的request转化为bytes
执行步骤D
response_by_socket(s)
response.decode(encoding)
s就是之前构造的socket实例,发出访问请求后,接收所有服务器返回的信息,转换为str
(python3默认编码为unicode,由str类型进行表示。二进制数据使用byte类型表示,所以不会将str和byte混在一起。在实际应用中我们经常需要将两者进行互转)
执行步骤E
parsed_response(r)
对服务器传回的信息进行解析(以下为传回的信息,通过 可对内容成功分解,理出条理,比较笨,但第一次这样解析过返回的源码,感觉瞬间明白了网页的一些内容)
b‘HTTP/1.1 301 Moved Permanently
Date: Sat, 27 Oct 2018 14:31:33GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection:close
Location: https://movie.douban.com/top250
Server: dae
X-Content-Type-Options:nosniff
b2r <html>
<head><title>301 Moved Permanently</title></head>
<body bgcolor="white">
<center><h1>301 Moved Permanently</h1></center>
<hr><center>nginx</center>
</body>
</html> 0
去掉 后可清楚得到许多信息
HTTP/1.1 301 Moved Permanently Date: Sun, 05 Jun 2016 12:37:55 GMT Content-Type: text/html Content-Length: 178 Connection: keep-alive Keep-Alive: timeout=30 Location: https://movie.douban.com/top250 Server: dae X-Content-Type-Options: nosniff <html> <head><title>301 Moved Permanently</title></head> <body bgcolor="white"> <center><h1>301 Moved Permanently</h1></center> <hr><center>nginx</center> </body> </html>
如何解析 下面代码实现
header, body = r.split(‘ ‘, 1) h = header.split(‘ ‘) status_code = h[0].split()[1] status_code = int(status_code) headers = {} for line in h[1:]: k, v = line.split(‘:‘) headers[k] = v
这个代码我们也暂时不去关心它的正确与否,接着往下分析
解析出
状态码 int
headers dict
body str
执行步骤F
遇到重定向问题,所谓重定向(Redirect)就是通过各种方法(本文提到的为3种)将各种网络请求重新转到其它位置(URL)。每个网站主页是网站资源的入口,当重定向发生在网站主页时,如果不能正确处理就很有可能会错失这整个网站的内容。
status_code, headers, body = parsed_response(r) if status_code == 301: url = headers[‘Location‘] return get(url) return status_code, headers, body
这个属于服务器端重定向,在服务器端完成,一般来说爬虫可以自适应,是不需要特别处理的,如响应代码301(永久重定向)、302(暂时重定向)等。具体来说,可以通过requests请求得到的response对象中的url、status_code两个属性来判断。利用上图代码进行处理
(当status_code为301、302或其他代表重定向的代码时,表示原请求被重定向;当response对象的url属性与发送请求时的链接不一致时,也说明了原请求被重定向且已经自动处理。)
大概理解了,就是你得通过提示找到资源存放的真正地点,不知道是否完全正确
接下来
又到了我最喜欢的debug环节了 哈哈哈哈哈哈(别理我,已经疯掉)
首先自己运行时出现了很多莫名奇妙的的错误,都指向测试代码,于是首先删掉了所有测试代码
可疑问为什么删掉了测试代码,发现不输出任何结果,明明我在主函数中输出了很多值
一个个设置输出检查,直到来到执行的第一句,函数根本没有执行啊喂!!
立马参考源代码,发现自己删测试函数的时候,把执行主函数的语句删掉了,,
我是用函数的方法写的,mian来执行这些函数,而谁来执行整个文件呢
(因为python不像其它函数一样是必须从 main 进入的,这个mian 其实相当于一个普通滴函数),所以如下
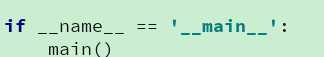 它来执行我写的这个.py文件
它来执行我写的这个.py文件
暂时是这么理解的,但这个奇怪的函数我查了资料
def cs(): print(‘已打开cs!‘) if __name__ == ‘__main__‘: print(‘cs主函数!‘)
如图 将原本单独的print(‘cs主函数!’)之前加入一句if_name_ == ‘_main_‘:
就会使另一文件调用它时不执行print(‘cs主函数!’)只执行 print(‘已打开cs!‘)
这样既可以让“模块”文件运行,也可以被其他模块引入,而且不会执行函数2次。这才是关键。
总结一下:
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == ‘__main__‘“是True,
但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == ‘__main__‘“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
---------------------
(总结转自:https://blog.csdn.net/qq_27231343/article/details/51184389 )
函数可以执行后
最终又改掉了两个错误:
headers = {} for line in h[1:]: k, v = line.split(‘: ‘)#自己写的时候‘: ’ 冒号后少打一个空格 一直报too many values to unpack 的错误 headers[k] = v return status_code, headers, body
if status_code == 301: url = headers[‘Location‘]#自己重新打发现L时大写,自己一直是小写,,,汗 return get(url)
都是很小的错误,但要老命了
最后附上成功的爬到的源码:单独放文章了,有点多,,,
搞定,喜大普奔,终于结束了,junkdog gogogog!
以上是关于python web 2的主要内容,如果未能解决你的问题,请参考以下文章