Intel,Nvidia,AMD三大巨头火拼GPU与CPU
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Intel,Nvidia,AMD三大巨头火拼GPU与CPU相关的知识,希望对你有一定的参考价值。
Intel,Nvidia,AMD三大巨头火拼GPU与CPU
英特尔、英伟达隔空斗法!AMD加大火力争夺GPU市场,到底谁更有胜算?
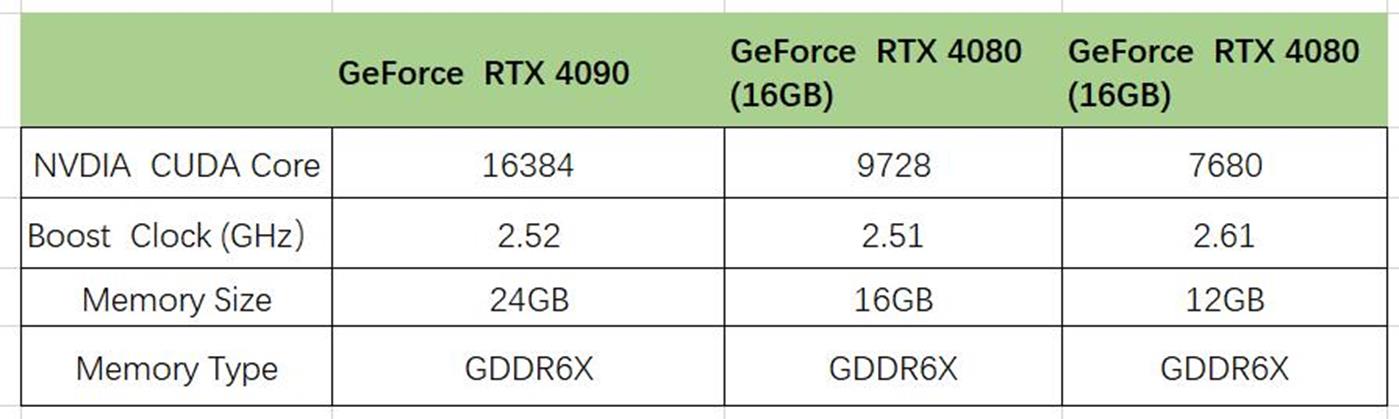
GPU市场风云再起,英伟达和英特尔隔空斗法。9月21日,英伟达正式公布了第三代RTX 架构Ada Lovelace。Ada GPU可以实现2倍的传统光栅化游戏性能提升,对光线追踪游戏的性能提升高达4倍。英伟达基于Ada Lovelace架构的GPU共有三款,包括GeForce RTX 4090提供24GB版本,GeForce RTX 4080提供16GB和12GB版本。
2022年9月27日,英特尔创新峰会召开,英特尔CEO基辛格宣布,GPU是英特尔的一个增长引擎。面向游戏玩家,英特尔推出了锐炫GPU。帕特·基辛格宣布,英特尔锐炫A770于2022年10月12日以329美元的起售价和多种产品设计登陆零售市场,提供出色的内容创作和1440P游戏性能。

GPU由早期的图形渲染,逐步拓展至高性能运算、科学计算等领域,并且已经超越了CPU、FPGA、ASIC等,成为通用并行计算的理想载体。

过去一年,PC GPU 市场份额发生了较大的变化。市场调研机构JPR公布了2022年第一季度GPU显卡(包括独显和集成显卡)市场报告,从 2021 Q1 到 2022 Q1,英伟达和 AMD 都从英特尔那里拿下了部分市场份额,且 Nvidia 仍占据着领先位置。2021 Q1,英特尔 GPU 市场份额高达 68%,到了2022年Q1,英特尔份额下滑到60%,英伟达以21%的份额占据第二,AMD略微提升到19%。2022年三方会拿出哪些杀手锏来争夺市场份额?我们就从具体的GPU市场增长趋势和新品说起。
中国GPU市场未来5年增长迅猛 美国限制令加紧国际大厂对中国出货步伐
目前,从功能来看,GPU可以简单分为侧重图形图像渲染的GPU和侧重通用计算的GPGPU两大市场。行业人士表示,计算是GPU的最大市场,图形渲染为第二大市场。从官方统计数据来看,2021年图形渲染GPU市场为150亿美元,要高于计算市场110亿美元,但其实很多被卖出去的渲染芯片,都被用于计算。所以,约200多亿美元的GPU市场有70%是计算。
“尽管AMD,英特尔和英伟达在下半年推出了新产品,但消费者仍然持谨慎态度。因此,我们对GPU2022年的预测是适度的2%至3%。根据美国大型企业联合会对美国经济的经济预测,美国实际GDP增长将同比增长2.3%,我们预计2023年将增长2.1%,“JPR总裁Jon Peddie说。
2022年9月16日,中信证券研报显示,2021年中国GPU(图形渲染)的市场规模在27亿美元,数据中心GPU的市场规模在20亿美元,2025年中国GPU(图形渲染)的市场规模有望达到47亿美元,数据中心GPU的市场规模2030年有望达到250亿美元,约占全球30%。中国市场GPU芯片增长潜力巨大。
2022年9月初,美国GPU芯片大厂NVDIA被美国政府要求限制向中国出口顶级AI芯片一天后,英伟达披露最新进展——已获得美国政府批准,可以在2023年3月前继续向美国客户出口(到中国)的产品提供A100,可以在2023年9月份继续履行A100和H100的订单。2022年9月26日,台湾供应链消息,美国芯片企业NVIDIA已要求台积电加紧出货,希望台积电用两个月时间完成此前计划五个月完成的NVIDIA芯片订单,以帮助NVIDIA在2023年3月前的最后期限之前尽可能向中国市场销售更多的GPU芯片。
英伟达推出GeForce RTX 4090独立显卡

英伟达是目前全球最大的独立GPU供应商,2022财年全年营收269.1.亿美元,较上一财年增长61%。2021Q2 Nvidia全球独立GPU市场份额达到83%。这家公司在1999年发明了GPU,最初专注PC图形,后来拓展到密集计算领域,Nvidia利用GPU创建了科学计算、人工智能、数据科学、自动驾驶汽车、机器人技术、AR和VR的平台。
图片来自英伟达官方微信2022年9月21日,英伟达CEO黄仁勋正式发布GeForce RTX 4090,这款芯片最多可以包含760亿个晶体管,采用台积电4N制程工艺和美光科技的GDDR6X存储芯片,理论能效较上一代8nm工艺提高一倍,意味着更高的超频潜力。黄仁勋特别强调,新一代RTX 4090旗舰显卡,拥有24GB GDDR6X内存,在不同游戏平台上较上一代架构的3090Ti表现提高2-4倍,价格1599美元(12999元),2022年10月12日正式发售。RTX4080的两个版本,12GB内存起售价899美元,而16GB版本的起售价1199美元。
针对数据中心,英伟达在2022年4月发布的最新旗舰产品H100 Tensor Core CPU已进入大规模量产。
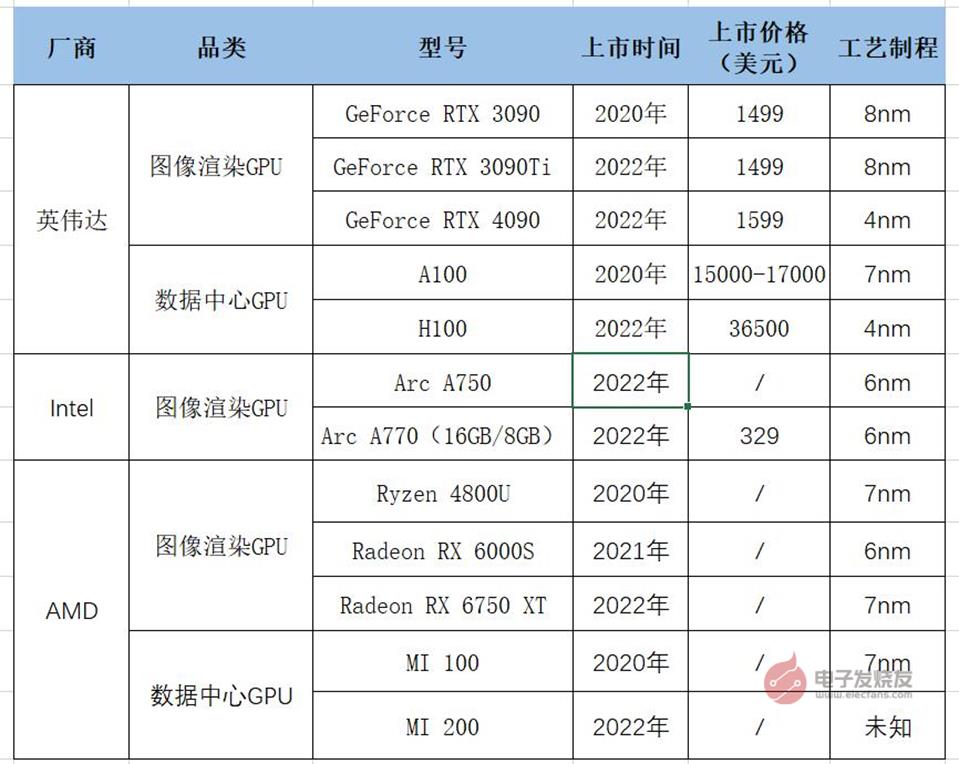
三家大厂主要GPU产品列表图:电子发烧友根据公开资料制图
Intel发布Arc A770 提供更高性价比显卡给消费者2022年6月,英特尔发布了旗下首款桌面级独立显卡,定位入门级的A380。2022年9月28日,英特尔CEO基辛格宣布,英特尔锐炫A770于2022年10月12日以329美元的起售价和多种产品设计登陆零售市场,提供出色的内容创作和1440p游戏性能。

图:ARC A770英特尔提供
A770搭载了16GB的GDDR6内存,拥有2100MHz的频率和32个Xe内核。较2023年六月发布的入门级A380 6GB的内存与8个Xe内核提升较大。目前英特尔尚未发布A770显卡完整的测试成绩。A770显卡同样支持类似英伟达RTX显卡上DLSS技术的XeSS超级采样技术,英特尔称受益于该项技术,A770显卡光线追踪性能显著优于同价位的英伟达RTX 3060。比较NVDIA RTX3060,新上市的Intel A770更加具有性价比,定价仅为329美元。“很长时间以来,GPU的价格都保持在200至300美元之间,但最近一段时间以来GPU变得十分昂贵,人们已经对为了高性能的显卡付出过高的价格感到厌倦,我们认为不必如此,并正在解决这个问题,为玩家提供更多选择。”帕特在演讲中表示。
帕特·基辛格表示,内置代号为Ponte Vecchio的英特尔数据中心GPU的刀片式服务器,现已出货给阿贡国家实验室,将为极光超级计算机提供驱动力。
AMD用这款产品Hold 1044P游戏
AMD中国区企业与商用事业部技术总监刘文卓对媒体表示,首先,AMD是业界首个将7nm制程技术应用于x86
CPU和GPU产品的半导体企业。
Radeon RX 6750 XT显卡采用AMD RDNA 2架构,具备工艺上的优化和固件、软件的增强,配备了96MB高带宽、低延迟的AMD Infinity Cache(高速缓存),拥有40个计算单元和光线加速器以及超快的AMD Infinity Cache,12GB GDDR6最大显存,基础频率2150 MHz,加速频率至高可达2600MHz,为玩家带来出色的性能。
其支持Microsoft Windows 11、Microsoft DirectX 12 Ultimate,同时可为支持FSR超级分辨率锐画技术的游戏提升图像质量及性能;为支持FSR 2的游戏带来超原生的画质,同时解锁全新的性能水平。不久前AMD宣布了广受欢迎的时域采样放大技术的新迭代——FidelityFX Super Resolution(超级分辨率锐画,简称#FSR#)2.1。FSR 2.1包括对算法的更新,可以提高游戏中画质,同时减少重影和闪屏等伪影现象。同时还宣布了11款已经加入或预计加入对FSR 2支持的游戏,目前可支持FSR 2的游戏总数已达到45款。
长期以来,全球独立显卡GPU市场被NVDIA和AMD垄断,英特尔虽然在集成显卡市场占据最高的份额,但是在利润丰富的独立显卡市场存在感不强。这次,英特尔推出Arc 770系列,就是试图打破这种垄断的努力。
目前,虽然尚未披露完整测试成绩,但英特尔透露,Arc A770在1080P分辨率的光线追踪游戏中表现优于RTX 3060。英特尔推出独显产品除了面向消费级市场外,可能也是对英伟达高性能计算产品的防御,并瞄准未来市场的需求。
对于国内企业来说,英伟达面向数据中心的A100和H100可能要在2023年3月断供,也激发了国内GPU企业快速推出替代产品的热潮。据悉,天数智芯算推出的首款7nm通用GPU“天垓100”已实现量产,截至2022年9月初,累计订单金额超2.3亿元。壁仞科技推出的GPU芯片“BR100”在与英伟达在售旗舰“A100”对比时,部分指标领先。我们期盼更多国内GPU芯片量产消息传来。
AMD、英伟达,显卡战火依旧
生成式 AI 当道,英伟达尝尽甜头、风生水起,据外媒报道, 英伟达的股价在过去 6 个月内翻了一倍之多,目前该公司市值已超越 Meta 、特斯拉(Tesla),甚至逼近股神巴菲特的投资公司波克夏.海瑟威。就连微软、Google 都不曾在近期的 AI 热潮中享受过这等甜头。其对手之一 AMD 近日坦然承认“不可能复制英伟达的成功之路”。
AMD这酸酸的承认,不是真的“甘拜下风”。两个死对头的火药味也是浸透了历史……
开战历史
自90年代末以来,AMD与英伟达的战争就一直没有停止过,当时AMD的GPU部门由ATI品牌组成。AMD是一家历史更悠久的公司,其历史可以追溯到50年代后期(实际的成立日期是1959年5月1日)。相比之下,英伟达的历史大约只有后者的一半,但是这位年轻的新玩家已经成为图形显卡行业的王者。就纯财务而言,英伟达的价值大约是AMD的两倍,并且AMD的一部分资源也来源于CPU。
英伟达以其广受欢迎的 GeForce 图形处理单元 (GPU) 在消费市场广为人知,但他们也为各种其他应用生产技术产品。英伟达的 Tegra 芯片是一种移动设备计算解决方案,而特斯拉是他们用于科学和工程应用的处理器。英伟达 Drive 是一系列用于自动驾驶车辆的技术,nForce 是一种芯片组技术,可与流行的消费主板上的系统处理器接口。英伟达GPU 还用于科学研究和超级计算。CUDA(统一计算设备架构)API 是一种支持大量 GPU 内核进行并行处理的技术。实验室和研究小组在广泛的神经网络系统中使用 CUDA 来支持尖端的深度学习和人工智能项目。
AMD 被消费者视为中低预算性能的不错选择,但他们的高端显卡和 CPU 有时可与英伟达的高端产品相媲美。AMD 拥有广泛的 CPU 和 APU 产品线,其中包括用于廉价 PC 的 Athlon 品牌、用于笔记本电脑的 A 系列、用于性能台式机的 Ryzen 以及用于专业创作软件和高端发烧友构建者的 Ryzen Threadripper。AMD GPU 芯片的产品线包括广受欢迎的 Radeon、Mobility Radeon、用于工作站的 Radeon Pro,以及用于服务器和机器学习应用程序的 Radeon Instinct。AMD 还生产 RAM 内存和固态硬盘。
擂台比拼
价格
传统上,AMD 一直被认为是更实惠的显卡品牌,直到今天……在某种程度上也是如此。现在,特别是在中端,AMD 拥有像 Radeon RX 5500 XT 这样的显卡,它们以 199 美元的价格提供出色的性能。但是,一旦参考的价格区间上升一些,情况就会发生变化。
因为一旦进入低端高端,事情就不再那么黑白分明了,AMD 和英伟达都生产了一些目前市场上最好的1440p显卡。AMD Radeon RX 6700 XT 和 AMD Radeon RX 6800 在美元规模上都比它们的直接英伟达竞争对手高一点,但没有提供那么多的性能优势。

英伟达 RTX 3090
性能
数十年来,更快的GPU使游戏开发人员能够创建越来越详细和复杂的世界。虽然AMD和英伟达都能提供不同价位和性能的GPU产品,但在性能方面,英伟达拥有明显的整体领先优势。
AMD 的 Big Navi 可能不是最初传闻中的英伟达杀手,但这系列中的一些显卡肯定会给英伟达带来一些激烈的竞争。如果想以 4K 玩最好的 PC 游戏并获得稳定的 60+ fps 帧速率,选择不再受制于英伟达。尽管英伟达RTX 3080 Ti 现已正式面世,但 AMD 需要尽快推出一款有力的竞争者。
2022 年有的显卡可以在 1080p 设置下为最佳 PC 游戏提供动力,例如 AMD Radeon RX 5600 XT 或英伟达GeForce RTX 3060。如果想在 1440p 下畅玩 AAA 级游戏而毫不妥协,这两个团队Red 和 Team Green 在 Radeon RX 6700 XT 和英伟达GeForce RTX 3060 Ti 上有很好的选择。
对于 4K,两家制造商都提供了出色的产品,英伟达 推出了英伟达GeForce RTX 3080、RTX 3080 Ti,甚至英伟达GeForce RTX 3090,而 AMD 发布了 Radeon RX 6900 XT,它的开发是为了迎头赶上英伟达的 RTX 3090。
排他性和功能

AMD Radeon RX 6900 XT来源:AMD
当谈到渲染游戏以外的功能时,英伟达 和 AMD 采取了截然不同的方法。
通常,AMD 的方法对消费者更友好,因为它发布的功能和技术甚至可以在英伟达显卡上使用——尽管它们通常在 AMD 自己的芯片上运行得最好。在驱动程序支持方面,AMD 并不总是拥有最好的记录,但真正的问题通常很少见。
另一方面,英伟达推出了 DLSS 等只能在自己的平台上运行的功能。然而,最近英伟达 推出了大量在游戏之外有帮助的功能,既作为其正在进行的英伟达Studio 驱动程序的一部分,用于创意和专业工作负载。
借助 Ampere可以获得英伟达Broadcast,这对几乎每个人来说都是非常有用的技术。使用此程序可以AI 替换任何视频会议应用程序中的背景。还可以在通话时使用它来滤除麦克风的所有背景噪音。
相反,AMD 仍然非常关注其主流显卡的游戏,其随 RDNA 引入的 FidelityFX 软件套件中的所有功能都以提供更好的游戏体验为中心。这包括对比度自适应锐化 (CAS) 之类的东西,它使在更高分辨率的显示器上播放更容易,以及更好的环境遮挡。
未来怎么打?
据财报显示,2022年AMD在游戏业务方面收入达68亿美元,比同期增长超过二成,成为最赚钱部门。反观对手英伟达在游戏业务方面收入比同期减少超过27%,业绩下跌至90亿美元。
AMD 显卡部门的高级副总裁 David Wang 日前接受日媒采访时指出,“公司将专注于游戏显卡用户需要且关心的重点,避免用户为他们永远用不到的运算功能买单。”
原来, 英伟达虽称霸游戏显卡市场多时,但其定价策略一直被玩家所诟病。资深PC使用者、设备玩家Monica White在digitaltrends上发表看法时,以“贵得离谱”形容英伟达旗舰GPU产品,并指出过去几年英伟达的GPU价格以指数级速度暴涨,每代间涨幅通常高达200美元,某些甚至近500美元。
这样的定价,给了AMD 施展拳脚的空间。如同几年前 AMD 以更高定价的 CPU 产品,撼动 Intel 在 CPU 市场的王者地位,AMD 在 GPU 上依样画葫芦。
Monica White 分析,若消费者选择以AMD的RX 6900 XT或RX 6950 XT来取代英伟达的RTX 3090,两者虽性能相仿,但前者价格便宜后者约500美元。如此诱人的价格,Monica White指出英伟达应担心在 GPU 显卡领导地位的时代即将受到威胁。Monica White 甚至指出,“英伟达离谱的定价策略正是我们(玩家)需要 AMD 和 Intel 的原因。”
AMD第二个反攻策略就是专注 CPU 优势,以特有产品 APU 挑战英伟达的 GPU 宝座。但价格导向只是AMD反攻策略的其中一环。AMD 深知在产品性能上的进步,才是抵御威胁的长久之计,因此除了游戏业务外,另一锁定的战场还有数据中心领域。
据产业记者 Harsh Chauhan 分析,英伟达控制着超过 90% 数据中心所需的 GPU 市场,其余才由 AMD 吃下。要扭转这一劣势, AMD 于2023年 1 月 CES 消费电子展上亮相的新产品可能是希望之一。AMD CEO 苏姿丰在会场上手持一颗有史以来制造过最大的芯片亮相。该新产品为Instinct MI300,是首款数据中心级的APU产品。APU(Accelerated Processing Unit)是AMD过去于2011年首创的独家产品,简单来说是将CPU与GPU封装在一起。
AMD指出,Instinct MI300 集合了 13 个芯片组(Chiplets,又称“小芯片”),共具备 1460 亿个晶体管,这数目远超过英伟达在数据中心级 GPU 产品 H100 所具备的 800 亿个晶体管。
据《Tom\'s Hardwre》报道,AMD 声称,MI300 能将 ChatGPT、DALL· E 等大型 AI 模型的训练时间,从几个月缩短至几周,从而替客户节省数百万美元的电费。
MI300 预计于2023年下半年正式上市,虽然实际表现还是未知数,但透过此产品布局可知,AMD 正基于对 CPU 产品的优势,选择在 APU 上发力,走出与英伟达的不同道路。试图在 AI 领域挑战英伟达。
在不久前结束的GTC上,英伟达展示了Grace这一产品的实物,也象征着其正式入局ARM CPU市场。英伟达的Grace对于ARM在数据中心和HPC生态的发展无疑提供了巨大的助力,但这并不意味着ARM就能蚕食掉x86现有的份额,即便是英伟达CEO黄仁勋也很清楚地认识到了这一点。他表示,需要x86的客户依然占据主导,未来也会一直维持下去。
对于商用计算来说,他们没理由从x86转向ARM,甚至都不一定会转向Grace。不过英伟达已经看到了已经有云服务供应商开始选择ARM,所以他们也想打造这样的CPU来满足这一部分的需求,但他们明确表示,Grace面向的依然是一个小众市场。当然了,这也可能是扮猪吃老虎,要说英伟达没有一点野心肯定是不可能的。毕竟随着Grace、Grace Hopper以及后续迭代产品的出现,无论是数据中心还是HPC/超算市场,都将无法忽略这样一个性能怪兽。
英特尔、AMD、英伟达,三大厂商同台竞技混合GPU+CPU
如果说英伟达的Grace CPU超级芯片的架构是CPU+GPU是巧合,那么英特尔和AMD推出的Falcon Shores XPU芯片、Instinct MI300芯片同样是CPU+GPU结构时,CPU+GPU一体的架构就很难称之为巧合了。
更为“碰巧”的是,以上三种芯片其都是用于数据中心的场景,这就意味着在未来两年内,AMD、英伟达和英特尔都将拥有混合CPU+GPU芯片进入数据中心市场。
可以说CPU+GPU的形式已经成为未来芯片设计的趋势。
CPU与GPU的进一步结合
英特尔推出XPU
英特尔宣布了一款特殊的融合型处理器“Falcon Shores”,官方称之为XPU。其核心是一个新的处理器架构,将英特尔的x86 CPU和Xe GPU硬件置入同一颗Xeon芯片中。
Falcon Shores芯片基于区块(Tile)设计,具备非常高的伸缩性、灵活性,可以更好地满足HPC、AI应用需求。
按照英特尔给出的数字,对比当今水平,Falcon Shores的能耗比提升超过5倍,x86计算密度提升超过5倍,内存容量与密度提升超过5倍。
Falcon Shores芯片将在2024年推出。
AMD推出APU
在数据中心领域,AMD同样展示其野心。
APU是AMD传统上用于集成显卡的客户端CPU的“加速处理单元”命名法。自2006年Opteron CPU的鼎盛时期以来,AMD一直梦想着使用APU,并于2010年开始推出第一款用于PC的APU。随后在索尼Play Station4和5以及微软Xbox XS中推出了定制APU系列游戏机,也推出了一些Opteron APU——2013年的X2100和2017年的X3000。
最近,AMD公布的路线图中显示,其将在2023年推出Instinct MI300芯片,这是AMD推出的第一款百亿亿次APU,AMD将其称为“世界上第一个数据中心APU”。
而这个APU是一种将CPU和GPU内核组合到一个封装中的芯片,仔细来说是将基于Zen4的Epyc CPU与使用其全新CDNA3架构的GPU相结合。
AMD表示Instinct MI300预计将比其Instinct MI250X提供超过8倍的AI训练性能提升,与支持Instinct MI200系列的CDNA2 GPU架构相比,用于Instinct MI300的CDNA3架构将为AI工作负载提供超过5倍的性能功耗比提升。
Instinct MI300将于2023年问世。
英伟达Grace超级芯片
一直专注于GPU设计的英伟达,在去年宣布进军基于Arm架构的CPU时引发了一阵轰动。在2023年3月,英伟达推出解决HPC和大规模人工智能应用程序的Grace Hopper超级芯片。这款芯片将NVIDIA Hopper GPU与Grace CPU通过NVLink-C2C结合在一个集成模块中。
CPU+GPU的Grace Hopper核心数减半,LPDDR5X内存也只有512GB,但多了显卡的80GBHBM3内存,总带宽可达3.5TB/s,代价是功耗1000W,每个机架容纳42个节点。
英伟达同样承诺在2023年上半年推出其超级芯片。
为什么巨头都纷纷使用这种形式?
从推出的时间节点来看,英特尔Falcon Shores芯片、AMD Instinct MI300、英伟达Grace Hopper超级芯片分别在2024年、2023年、2023年上半年推出。
CPU+GPU的形式,为什么引起了三大巨头的兴趣,纷纷将其布局于数据中心?
首先,在数字经济时代,算力正在成为一种新的生产力,广泛融合到社会生产生活的各个方面。数据中心是算力的物理承载,是数字化发展的关键基础设施。全球数据中心新增稳定,2021年全球数据中戏市场规模超过679亿美元,较2020年增长9.8%。因此,具有巨大市场的数据中心早已被科技巨头紧盯。
其次,数据中心会收集大量的数据,因此需要搭建于数据中心的芯片具有极大算力,将CPU与GPU组合可以提高算力。英特尔高级副总裁兼加速计算系统和图形(AXG)集团总经理Raja Koduri的演讲中提及,如果想要成功获得HPC市场,就需要芯片能够处理海量的数据集。尽管,GPU具有强大的计算能力,能够同时并行工作数百个的内核,但如今独立的GPU仍然有一大缺陷,就是大的数据集无法轻松放入独立GPU内存里,需要耗费时间等待显存数据缓慢刷新。
特别是内存问题,将CPU与GPU放入同一架构,能够消除冗余内存副本来改善问题,处理器不再需要将数据复制到自己的专用内存池来访问/更改该数据。统一内存池还意味着不需要第二个内存芯片池,即连接到CPU的DRAM。例如,Instinct MI300将把CDNA3 GPU小芯片和Zen4 CPU小芯片组合到一个处理器封装中,这两个处理器池将共享封装HBM内存。
英伟达官方表示,使用NVLink-C2C互连,Grace CPU将数据传输到Hopper GPU的速度比传统CPU快15倍;但对于数据集规模超大的场景来说,即使有像NVLink和AMD的Infinity Fabric这样的高速接口,由于HPC级处理器操作数据的速度非常快,在CPU和GPU之间交换数据的延迟和带宽代价仍然相当高昂。因此如果能尽可能缩短这一链路的物理距离,就可以节约很多能源并提升性能。
AMD表示,与使用分立CPU和GPU的实现相比,该架构的设计将允许APU使用更低的功耗;英特尔同样表示,其Falcon Shores芯片将显着提高带宽、每瓦性能、计算密度和内存容量。
定制款的吸引力
整合多个独立组件往往会带来很多长期收益,但并不只是将CPU与GPU简单整合到一颗芯片中。英特尔、英伟达及AMD的GPU+CPU均是选择了Chiplet方式。
传统上,为了开发复杂的 IC 产品,供应商设计了一种将所有功能集成在同一芯片上的芯片。在随后的每一代中,每个芯片的功能数量都急剧增加。在最新的 7nm 和 5nm 节点上,成本和复杂性飙升。
而使用Chiplet设计,将具有不同功能和工艺节点的模块化芯片或小芯片封装在同一芯片,芯片客户可以选择这些小芯片中的任何一个,并将它们组装在一个先进的封装中,从而产生一种新的、复杂的芯片设计,作为片上系统 (SoC) 的替代品。
正是由于小芯片的特性,三家巨头在自己发展多芯片互连的同时,还展开了定制服务。
英特尔在发布Falcon Shores时介绍,其架构将使用Chiplet方法,采用不同制造工艺制造的多个芯片和不同的处理器模块可以紧密地塞在一个芯片封装中。这使得英特尔可以在其可以放入其芯片的CPU、GPU、I/O、内存类型、电源管理和其他电路类型上进行更高级别的定制。
最特别的是,Falcon Shores可以按需配置不同区块模块,尤其是x86CPU核心、XeGPU核心,数量和比例都非常灵活,就看做什么用了。
目前,英特尔已开放其 x86 架构进行许可,并制定了Chiplet策略,允许客户将 Arm 和 RISC-V 内核放在一个封装中。
最近,AMD同样打开了定制的大门。AMD首席技术官Mark Papermaster在分析师日会议上表示:“我们专注于让芯片更容易且更灵活实现。”
AMD允许客户在紧凑的芯片封装中实现多个芯粒(也称为chiplet或compute tiles )。AMD已经在使用tiles,但现在AMD允许第三方制造加速器或其他芯片,以将其与x86 CPU和GPU一起包含在其2D或3D封装中。
AMD的定制芯片战略将围绕新的Infinity Architecture 4.0展开,它是芯片封装中芯粒的互连。专有的Infinity结构将与CXL 2.0互连兼容。
Infinity互连还将支持UCIe(Universal Chiplet Interconnect Express)以连接封装中的chiplet。UCIe已经得到英特尔、AMD、Arm、谷歌、Meta等公司的支持。
下一代顶级芯片会是多芯片设计吗?
总体而言,AMD的服务器GPU轨迹与英特尔、英伟达非常相似。这三家公司都在向CPU+GPU组合产品方向发展,英伟达的GraceHopper(Grace+H100)、英特尔的Falcon Shores XPU(混合和匹配CPU+GPU),现在MI300在单个封装上同时使用CPU和GPU小芯片。在所有这三种情况下,这些技术旨在将最好的CPU和最好的GPU结合起来,用于不完全受两者约束的工作负载。
市场研究公司Counterpoint Research的研究分析师Akshara Bassi表示:“随着芯片面积变得越来越大以及晶圆成品率问题越来越重要,多芯片模块封装设计能够实现比单芯片设计更佳的功耗和性能表现。”
Chiplet将继续存在,但就目前而言,该领域是一个孤岛。AMD、苹果、英特尔和英伟达正在将自研的互连设计方案应用于特定的封装技术中。
2018 年,英特尔将 EMIB(嵌入式多硅片)技术升级为逻辑晶圆 3D 堆叠技术。2019 年,英特尔推出 Co-EMIB 技术,能够将两个或多个 Foveros 芯片互连。
AMD率先提出Chiplet模式,在2019年全面采用小芯片技术获得了技术优势。Lisa Su 在演讲时表达了未来的规划,“我们与台积电就他们的 3D 结构密切合作,将小芯片封装与芯片堆叠相结合,为未来的高性能计算产品创建 3D 小芯片架构。”
2022年 3 月 2 日,英特尔、AMD、Arm、高通、台积电、三星、日月光、谷歌云、Meta、微软等十大巨头宣布成立 Chiplet 标准联盟,推出了通用小芯片互连标准 (UCIe),希望将行业聚合起来。
迄今为止,只有少数芯片巨头开发和制造了基于Chiplet的设计。由于先进节点开发芯片的成本不断上升,业界比以往任何时候都更需要Chiplet。在多芯片潮流下,下一代顶级芯片必然也将是多芯片设计。
参考文献链接
https://mp.weixin.qq.com/s/mSbSX30gJm9kPJ76Qma5PQ
https://mp.weixin.qq.com/s/MAdqVbc0Wl2g1lFWdyzGMw
https://mp.weixin.qq.com/s/mv3MepA65XrB1i_vCrl2iQ
如何让 SYCL“default_selector”选择 Intel GPU 而不是 NVIDIA GPU?
【中文标题】如何让 SYCL“default_selector”选择 Intel GPU 而不是 NVIDIA GPU?【英文标题】:How do you make SYCL "default_selector" select an Intel GPU rather than an NVIDIA GPU? 【发布时间】:2019-11-27 00:41:06 【问题描述】:我目前正在使用 SYCL 对图像应用非锐化蒙版的项目。我的机器里面有一个 NVIDIA 和一个 Intel GPU。我从以下代码开始:
default_selector deviceSelector;
queue myQueue(deviceSelector);
问题在于代码行“default_selector deviceSelector;”自动抓取我机器内的 NVIDIA GPU,这会破坏后面的所有代码,因为 SYCL 不适用于 NVIDIA。
因此我的问题是 - 我如何强制“default_selector deviceSelector;”获取我的 Intel GPU 而不是 NVIDIA GPU?也许我可以这样说:
if (device.has_extension(cl::sycl::string_class("Intel")))
if (device.get_info<info::device::device_type>() == info::device_type::gpu)
then select this GPU;//pseudo code
从而使代码跳过NVIDIA GPU并保证选择我的Intel GPU。
【问题讨论】:
【参考方案1】:您正在检查扩展程序是否包含一个名为“Intel”的条目,但它不会。扩展是设备支持的东西,比如 SPIR-V 你可以通过在命令行调用 clinfo 来查看支持的扩展。要选择 Intel GPU,您需要检查设备制造商以选择正确的。
所以在自定义设备选择的示例代码https://github.com/codeplaysoftware/computecpp-sdk/blob/master/samples/custom-device-selector.cpp#L46
你只需要像
这样的东西if (device.get_info<info::device::name>() == "Name of device")
return 100;
你可以打印出
的值device.get_info<info::device::name>
获取要检查的值。
【讨论】:
以上是关于Intel,Nvidia,AMD三大巨头火拼GPU与CPU的主要内容,如果未能解决你的问题,请参考以下文章
CPU之外,国产芯片再突破,再也不用看AMD和NVIDIA的脸色了