Python神经网络编程 第一章
Posted paulonetwo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python神经网络编程 第一章相关的知识,希望对你有一定的参考价值。
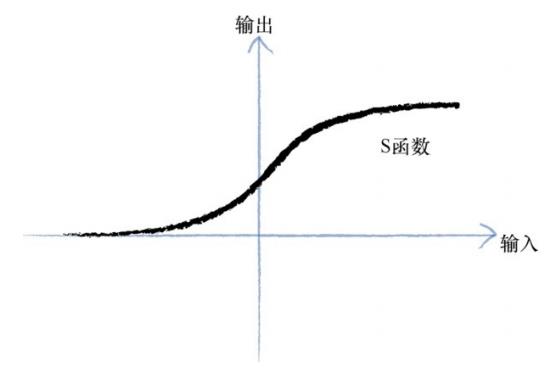
01.最常用的激活函数——S函数:
![]()
使用这种S函数的一个重要原因是它比其他S形函数计算简单。
02.神经网络为什么把前后层的每一个神经元与所有其他层的神经元互相连接?
a.容易实现;
b.学习过程会弱化不需要的连接。
03.为什么需要矩阵?
a.通过神经网络向前馈送信号所需的运算可以表示为矩阵乘法;
b.计算机能高效地进行矩阵运算。
04.神经网络在两件事情上使用了权重。第一,将信号从输入向前传播到输出层。第二,将误差从输出向后传播到网络中,此即反向传播。
05.反向传播误差可以表示为矩阵乘法。
06.当函数非常复杂,使用梯度下降法是求解函数最小值的一种很好的办法。这种方法也具有弹性,可以容忍不完善的数据,如果不能完美地描述函数,或意外地走错了一步,也不会错得离谱。
07.为了避免终止于错误的山谷或错误的函数最小值,我们从山上的不同点开始,多次训练神经网络。在神经网络中,这意味着选择不同的起始链接权重。
08.误差函数选择目标值与实际值差的平方,而不是差的绝对值,原因有以下几点:
a.可以很容易使用代数计算出梯度下降的斜率;
b.误差函数平滑连续。使得梯度下降法很好地发挥作用——没有间断,没有突然的跳跃;
c.越接近最小值,梯度越小,意味着超调的风险会变小。
09.
![]()
S函数微分后,可以得到一个非常简单、易于使用的结果。这是S函数成为大受欢迎的激活函数的一个重要原因。
10.
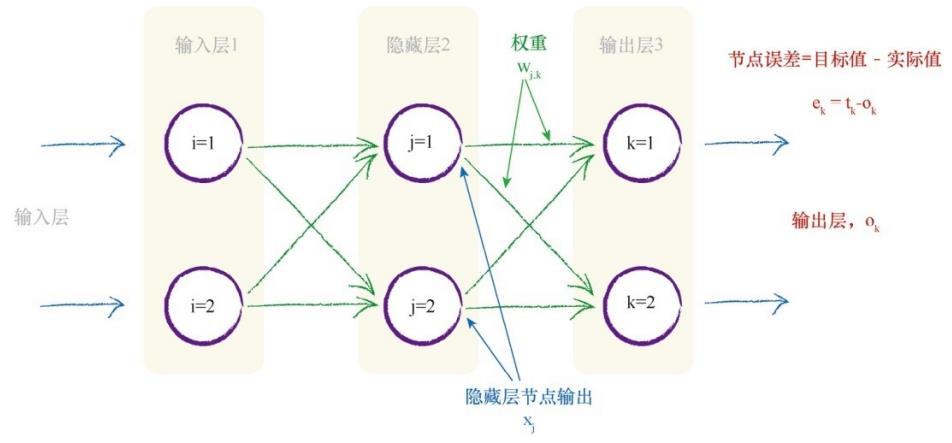
隐藏层和输出层间权重的误差函数的斜率表达式为:
展开,并做适当简化,得到: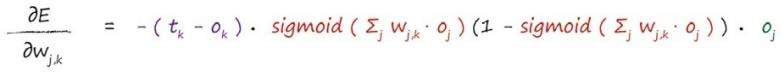
紫色部分是目标值减去实际值;红色部分sigmod中的求和是应用激活函数之前,进入节点的信号。绿色部分是前一隐藏层节点j的输出。
更新权重:
新的权重由误差斜率取反来调整旧的权重而得到。α为学习率,调节变化的强度,确保不会超调。
11.并不是所有使用神经网络的尝试都能够成功,这有许多原因。一些问题可以通过改进训练数据、初始权重、设计良好的输出方案来解决。
12.输入: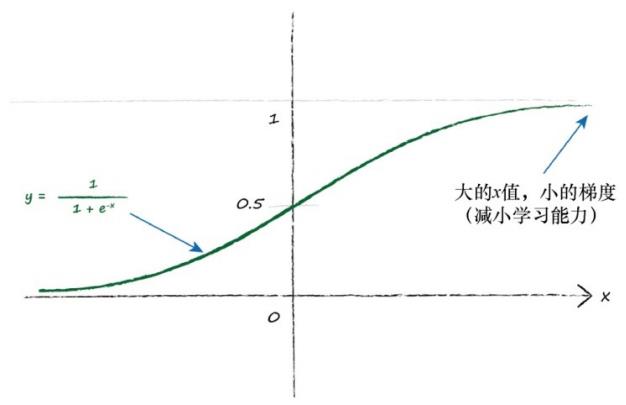
如果输入太小或太大,激活函数就会变得非常平坦。小梯度意味着限制神经网络学习的能力。这就是所谓的饱和神经网络。
一个好的建议是重新调整输入值,将其范围控制在0.0到1.0。输入0会造成学习能力的丧失,因此需要加上一个小小的偏移,如0.01。
13.输出: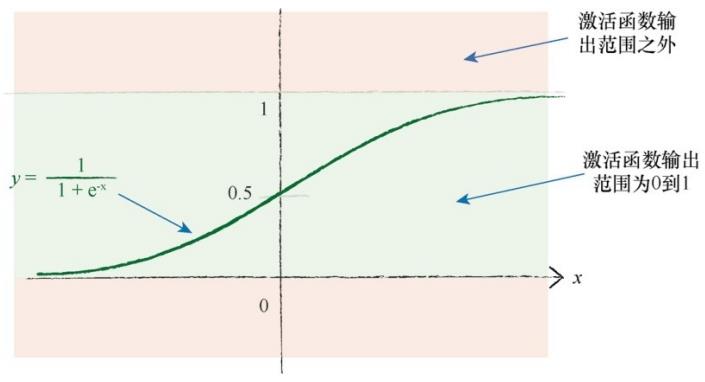
逻辑激活函数的输出值根本不可能大于1.0、小于0。因此,我们应该重新调整目标值,匹配激活函数的可能输出,注意避开激活函数不可能达到的值。
14.随机初始权重:
数学家所得到的经验规则是,我们可以在一个节点传入链接数量平方根倒数的大致范围内随机采样,初始化权重。因此,如果每个节点具有3条传入链接,那么初始权重的范围应该在负的根号3分之一到正的根号3分之一,即-0.577到+0.577之间。
一些过大的初始权重将会在偏置方向上偏置激活函数,非常大的权重将会使激活函数饱和。一个节点的传入链接越多,就有越多的信号被叠加在一起。因此,如果链接更多,那么减小权重的范围,这个经验法则是有道理的。
15.禁止将初始权重设定为相同的恒定值。如果这样做,那么在网络中的每个节点都将接收到相同的信号值,每个输出节点的输出值也是相同的,在这种情况下,如果我们在网络中通过反向传播误差更新权重,误差必定得到平分。那么,这将导致同等量的权重更新,再次出现另一组值相等的权重。
禁止将初始权重设定为0。由于0权重,输入信号归零,取决于输入信号的权重更新函数也因此归零,这种情况更糟糕。网络完全丧失了更新权重的能力。
以上是关于Python神经网络编程 第一章的主要内容,如果未能解决你的问题,请参考以下文章