目录
1 准备工作
什么是Redis?
Redis:一个高性能的key-value数据库。支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用;提供string、list、set、zset、hash等数据结构的存储,并支持数据的备份。
本文适合使用的场景:当一个项目中Redis缓存的数据量逐渐增大,Redis缓存的数据占用内存也会越来越大,而且其中有很多很可能是价值不大的数据。由于Redis是一个key-value数据库,所以对其中的数据进行分析没有mysql数据库那么直观。那么此时,我们需要寻找工具来分析Redis缓存中的哪些数据占用内存比较大,并结合项目实际的情况来分析这些数据存储的价值如何?从而作出具体删减数据的方案,来解放服务器端宝贵的内存资源。
本文需要采用的工具:Rdbtools和MySQL。
Rdbtools:使用Python语言编写的,可以解析Redis的dump.rdb文件。此外,提供以下工具:
(1)跨所有数据库和密钥生成数据的内存报告
(2)将dump文件转换为JSON
(3)使用标准diff工具比较两个dump文件
具体源码GitHub链接:https://github.com/sripathikrishnan/redis-rdb-tools/
MySQL:一种开源且比较轻量级的关系型数据库。本文使用Rdbtools解析出Redis的dump.rdb文件并生成内存报告*.csv文件(PS:下文操作文件为result_facelive_hot.csv),然后把该文件导入到MySQL数据库中,最后通过编写具体的SQL语句脚本生成想要的数据分析结果的*.csv文件(PS:下文SQL脚本中生成的文件名为redis_key_storage.csv)。
2 具体实施
Rdbtools工具在以下操作,需要Python2.7或者Python3.6等版本环境的支持。
(1)找到本机项目使用Redis生成的dump.rdb文件具体所在地址。(PS:本文操作的项目是一个基于Django框架,部署在Ubuntu系统上,所以相关命令都是该系统下的实际操作,其它环境基本类似,就不作介绍)
sudo find / -name \'*.rdb\'
运行上述命令后,即可看到本机上所有以.rdb为后缀文件的所有具体地址,然后根据项目实际情况,找到具体地址。例如,本文找到的地址:
/home/facelive/redis/data/hot/dump.rdb
PS:有的项目,使用Redis时,会把默认的dump.rdb文件进行了重新命名,例如命名为db-dump.rdb文件。那么此时如何判定具体命名呢?
可以查看项目使用Redis数据库的redis.conf文件内容,并结合以下命令:
cat -n redis.conf |grep "dbfilename"
即可查看具体的文件名。
(2)使用Rdbtools生成项目中使用Redis的内存使用的*.csv文件
此处需要项目先安装Rdbtools工具,项目且是基于Python环境。激活项目的虚拟环境,输入命令:
pip install rdbtools python-lzf
(3)安装完成后,即可在项目的虚拟环境中使用rdb命令。此处本文生成内存报告的命令如下:
rdb -c memory /home/facelive/redis/data/hot/dump.rdb > ~/result_facelive_hot.csv
生成的result_facelive_hot.csv文件会存放在服务器环境根目录。此时,可以从服务器把生成的文件复制到本地,具体操作命令参考:
sudo scp facelive@188.100.10.10:/home/facelive/result_facelive_hot.csv . # 从服务器复制远程文件到本地当前所在根目录,这里的ip是我自己随便写的噢
然后在本地打开result_facelive_hot.csv文件,结果如下(以下截图结果是在Windows环境下打开的噢):
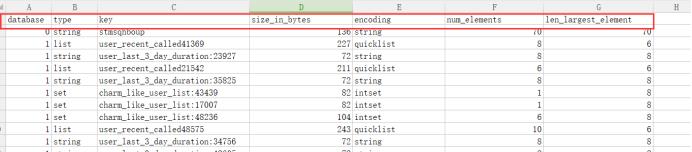
可以看到该表中有database(对应的数据库)、type(缓存的类型)、key(缓存的key名称)、size_in_bytes(该key具体占用内存大小,这是本文数据分析的核心数据)、encoding(缓存key的编码)、num_elements和len_larget_element六列数据。
(4)把result_facelive_hot.csv导入到MySQL数据库,进行数据分析
首先,选定本地MySQL数据库中某一已经创建好的数据库,并在该数据库中创建一个名称为redis_hot的表(PS:具体表名可随意定)
创建表的SQL语句:

DROP TABLE IF EXISTS `redis_hot`; CREATE TABLE `redis_hot` ( `database` int(11) DEFAULT NULL, `type` varchar(100) DEFAULT NULL, `key` varchar(200) DEFAULT NULL, `size_in_bytes` int(11) DEFAULT NULL, `encoding` varchar(255) DEFAULT NULL, `num_elements` int(11) DEFAULT NULL, `len_largest_element` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建好redis_hot表后,我们开始使用Navicat工具来进行数据导入工作。
PS:此处也可以使用脚本来完成具体数据写入,使用脚本命令的好处是,当导入的CSV文件过大,即数据量很大的时候,使用Navicat客户端会假死,导致数据压根就无法导入,但是脚本可以正常一键导入,不会出现问题。不过以下的使用Navaicat的方法还是可以参考一下。具体脚本代码如下:
create database if not exists facelive_redis default character set \'utf8\'; use facelive_redis; DROP TABLE IF EXISTS `redis_hot`; CREATE TABLE `redis_hot` ( `database` int(11) DEFAULT NULL, `type` varchar(100) DEFAULT NULL, `key` varchar(200) DEFAULT NULL, `size_in_bytes` int(11) DEFAULT NULL, `encoding` varchar(255) DEFAULT NULL, `num_elements` int(11) DEFAULT NULL, `len_largest_element` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; load data local infile \'~/facelive_redis/result_facelive_hot.csv\' # 此处修改为自己文件保存的具体实际地址即可 into table redis_hot character set gb2312 fields terminated by \',\' optionally enclosed by \'"\' escaped by \'"\' lines terminated by \'\\n\';
以下操作是在Windows环境下进行,其它环境使用Navicat可视化工具,操作步骤基本类似。
首先,使用Navicat打开本地数据库,找到刚刚创建的redis_hot表,鼠标点击右键,选择导入向导,具体流程如下:
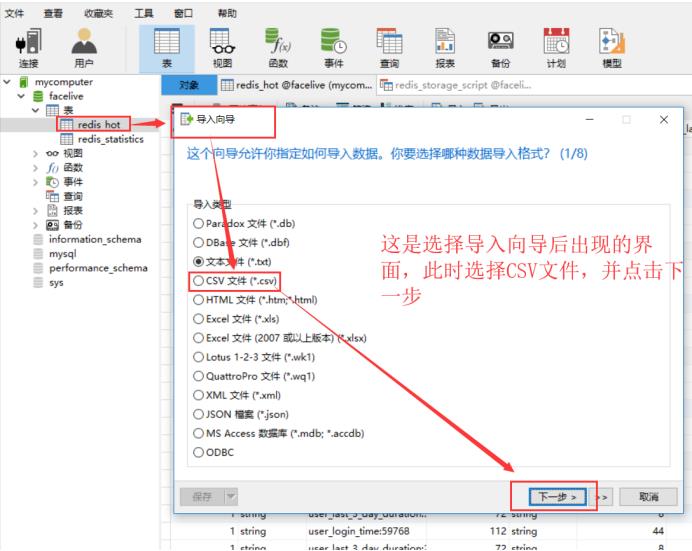
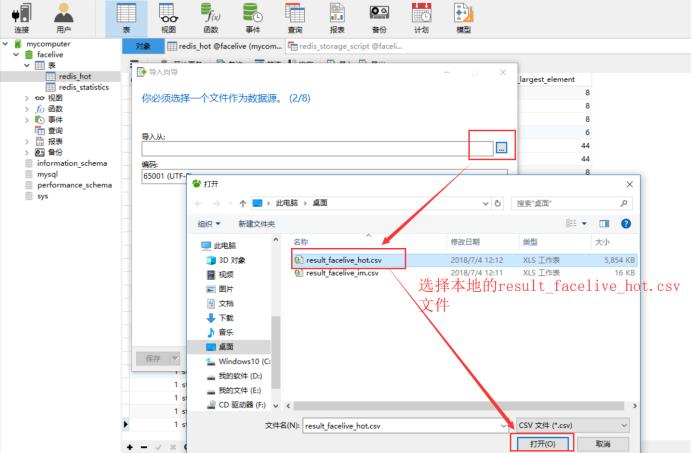
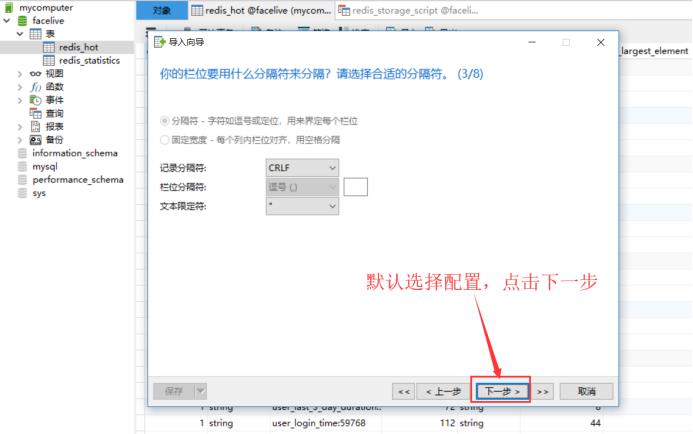
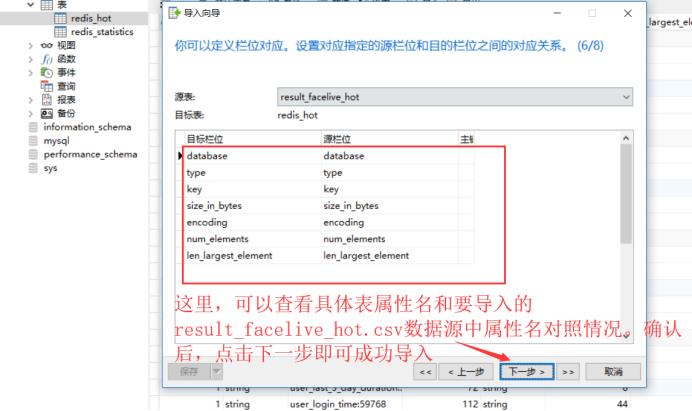
数据导入完成后,下面正式开始编写SQL查询脚本,生成具体所需分析结果数据。
此处需要分析的数据:
(1)每一种key所在用的总内存大小(size_in_bytes_sum)
(2)每一种key的总数(PS:因为有的key设计是前缀+用户id,这样的情况都属于一种key)(record_count)
(3)每一种key所在数据库(database)
(4)每一种key的数据类型(type)
(5)每一种key的编码类型(encoding)
(6)每一种key的名称(key)
(7)每一种key占用的平均内存大小(size_in_bytes_avg)
使用的SQL脚本代码如下:
# core_user
SELECT ANY_VALUE(`database`) as `database`, ANY_VALUE(type) as type, ANY_VALUE(`key`) as `key`, ANY_VALUE(encoding) as encoding,
count(`database`) as record_count, SUM(size_in_bytes) as size_in_bytes_sum,
AVG(size_in_bytes) as size_in_bytes_avg FROM redis_hot WHERE `key` LIKE \'user_verify_code_%\'
UNION
SELECT ANY_VALUE(`database`) as `database`, ANY_VALUE(type) as type, ANY_VALUE(`key`) as `key`, ANY_VALUE(encoding) as encoding,
count(`database`) as record_count, SUM(size_in_bytes) as size_in_bytes_sum,
AVG(size_in_bytes) as size_in_bytes_avg FROM redis_hot WHERE `key` LIKE \'robot_id_list%\'
UNION
... # 此处是使用连接(UNION)查询,每一个`SELECT`查询代表一个`key`信息,所以后续项目中`key`跟新时,也需要在本文件中写入一个新的连接查询
... # 指定的数据中查询`key`不存在,则最后统一返回一条全是0的数据,相当于过滤作用
/* 此处可以继续使用UNION来并查其他名称的key具体分析数据,下面一行代码是生成redis_key_storage.csv文件,如果注释掉,就可以直接在Navicat查询界面查看具体查询结果 */
into outfile \'E:/redis_key_storage.csv\' fields terminated by \',\'
optionally enclosed by \'"\' lines terminated by \'\\r\\n\';
# 其中可以修改具体文件保存地址(此处文件保存地址:\'E:/redis_key_storage.csv\')
最终得到的结果数据如下:

好啦,介绍这里就结束了,希望能对观看本文的同学有所帮助~
参考资料:
1.使用代码完成csv文件导入Mysql(https://blog.csdn.net/quiet_girl/article/details/71436108)
2.使用rdbtools工具来解析redis dump.rdb文件及内存使用量(http://www.ywnds.com/?p=8441)
3.MySQL必知必会:组合查询(Union)(https://segmentfault.com/a/1190000007926959)