Python深度学习案例1--电影评论分类(二分类问题)
Posted 墨麟非攻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python深度学习案例1--电影评论分类(二分类问题)相关的知识,希望对你有一定的参考价值。
我觉得把课本上的案例先自己抄一遍,然后将书看一遍。最后再写一篇博客记录自己所学过程的感悟。虽然与课本有很多相似之处。但自己写一遍感悟会更深
电影评论分类(二分类问题)
本节使用的是IMDB数据集,使用Jupyter作为编译器。这是我刚开始使用Jupyter,不得不说它的自动补全真的不咋地(以前一直用pyCharm)但是看在能够分块运行代码的份上,忍了。用pyCharm敲代码确实很爽,但是调试不好调试(可能我没怎么用心学),而且如果你完全不懂代码含义的话,就算你运行成功也不知道其中的含义,代码有点白敲的感觉,如果中途出现错误,有的时候很不好找。但是Jupyter就好一点,你可以使用多个cell,建议如果不打印一些东西,cell还是少一点,不然联想功能特别弱,敲代码特别难受。
1. 加载IMDB数据集
仅保留前10000个最常出现的单词,低频单词被舍弃
from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
train_data[0]
train_labels[0]
max([max(sequence) for sequence in train_data])
下面这段代码:将某条评论迅速解码为英文单词
word_index = imdb.get_word_index() reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) decoded_review = \' \'.join([reverse_word_index.get(i - 3, \'?\') for i in train_data[0]])
2. 将整数序列编码为二进制矩阵
# 对列表进行one-hot编码,将其转换为0和1组成的向量
def vectorize_sequences(sequences, dimension=10000):
# 创建一个形状为(len(sequences), dimension)的零矩阵
# 序列[3, 5]将会被转换成10000维向量,只有索引3和5的元素为1,其余为0
results = np.zeros((len(sequences), dimension))
# 将results[i]指定索引设为1
for i, sequence in enumerate(sequences):
results[i, sequence] = 1
return results
# 将训练数据向量化
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
x_train[0]
标签向量化
y_train = np.asarray(train_labels).astype(\'float32\') y_test = np.asarray(test_labels).astype(\'float32\')
3. 模型定义
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16, activation=\'relu\', input_shape=(10000, ))) model.add(layers.Dense(16, activation=\'relu\')) model.add(layers.Dense(1, activation=\'sigmoid\'))
4. 编译模型
model.compile(optimizer=\'rmsprop\', loss=\'binary_crossentropy\', metrics=[\'accuracy\'])
5. 配置优化器
from keras import optimizers model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=\'binary_crossentropy\', metrics=[\'accuracy\'])
6. 使用自定义的损失和指标
from keras import losses from keras import metrics model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=losses.binary_crossentropy, metrics=[metrics.binary_crossentropy])
7. 留出验证集
x_val = x_train[:10000] partial_x_train = x_train[10000:] y_val = y_train[:10000] partial_y_train = y_train[10000:]
8. 训练模型
model.compile(optimizer=\'rmsprop\', loss=\'binary_crossentropy\', metrics=[\'acc\']) history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val)) history_dict = history.history history_dict.keys()
9. 绘制训练损失和验证损失
import matplotlib.pyplot as plt history_dict = history.history loss_values = history_dict[\'loss\'] val_loss_values = history_dict[\'val_loss\'] epochs = range(1, len(loss_values) + 1) plt.plot(epochs, loss_values, \'bo\', label=\'Training loss\') plt.plot(epochs, val_loss_values, \'b\', label=\'Validation loss\') plt.title(\'Training and validation loss\') plt.xlabel(\'Epochs\') plt.ylabel(\'Loss\') plt.legend() plt.show()
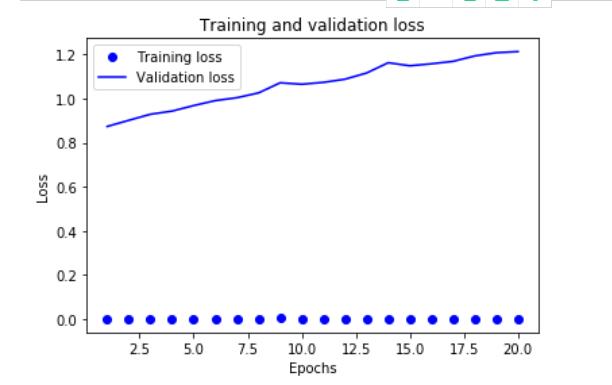
损失降得太狠了,训练的损失和精度不太重要,反应训练集的训练程度。重点是验证精度
10. 绘制训练精度和验证精度
plt.clf() # 清除图像 acc = history_dict[\'acc\'] val_acc = history_dict[\'val_acc\'] plt.plot(epochs, acc, \'bo\', label=\'Training acc\') plt.plot(epochs, val_acc, \'b\', label=\'Validation acc\') plt.title(\'Training and validation accuracy\') plt.xlabel(\'Epochs\') plt.ylabel(\'Accuracy\') plt.legend() plt.show()
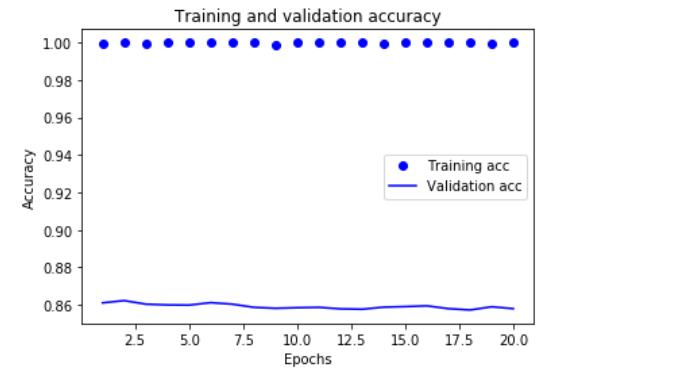
可以看到验证的精度并不高,只有86%左右。而训练的精度达到几乎100%,两者精度相差太大,出现了过拟合。为了防止过拟合,可以在3轮之后停止训练。还有很多方法降低过拟合。我们一般看验证精度曲线就是找最高点对应的轮次,然后从头开始训练一个新的模型
11. 从头开始训练一个模型
model = models.Sequential() model.add(layers.Dense(16, activation=\'relu\', input_shape=(10000,))) model.add(layers.Dense(16, activation=\'relu\')) model.add(layers.Dense(1, activation=\'sigmoid\')) model.compile(optimizer=\'rmsprop\', loss=\'binary_crossentropy\', metrics=[\'accuracy\']) model.fit(x_train, y_train, epochs=4, batch_size=512) results = model.evaluate(x_test, y_test)
最终结果如下:
results
[0.28940243008613586, 0.88488]
得到了88%的精度,还有待优化的空间
12. 使用训练好的模型在新数据上生成预测结果
model.predict(x_test)
array([[0.20151292],
[0.9997969 ],
[0.9158534 ],
...,
[0.1382984 ],
[0.0817486 ],
[0.69964325]], dtype=float32)
可见。网络对某些样本的结果是非常确信(大于等于0.99),但对其他结果却不怎么确信
13. 总结
1. 加载数据集->对数据集进行预处理->模型定义->编译模型->配置优化器->使用自定义的损失和指标->留出验证集->训练模型->绘制图像
2. 对于二分类问题,网络的最后一层应该是只有一个单元并使用sigmoid激活Dense层,网络输出应该是0~1范围内的标量,表示概率值
3. 对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy(二元交叉熵)损失函数。
以上是关于Python深度学习案例1--电影评论分类(二分类问题)的主要内容,如果未能解决你的问题,请参考以下文章