对AWS S3数据读写一致性的理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对AWS S3数据读写一致性的理解相关的知识,希望对你有一定的参考价值。
参考技术A 对于一个新上传的对象,S3提供写后读写一致性(read-after-write consistency)对于已存在对象的复写,S3提供最终读写一致性(eventual consistency)
什么意思呢? https://codeburst.io/quick-explanation-of-the-s3-consistency-model-6c9f325e3f82 这篇文章写得挺清楚的,有兴趣可以看一下,这里我们来总结一下
1.假设我们有一个崭新的文件img.jpg,put之后马上get ,OK,没有问题。这里就是 read-after-write consistency 的体现。
2.假设我们上传了一个img.jpg,之后再put一个和这个img.jpg的key一样,但是内容不同的新文件,之后再get。这个时候get请求的结果很可能还是旧的文件 。
3.假设我们get一个不存在的对象,会返回一个404结果,之后我们再put这个对象,随后再次的get可能还是会返回404
上述例子2和3就是S3 最终一致性(eventual consistency) 的体现。
因为s3是一个分布式系统,变更传播到每个节点需要一定的时间,所以如果在变更还没有传播到所有节点之前就执行get请求,很有可能就会得到一个旧的结果。
S3的这种特性其实是 CAP定理 的一种体现。简单解释一下CAP定理
CAP定理 (CAP theorem),又被称作 布鲁尔定理 (Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性( C onsistency) (等同于所有节点访问同一份最新的数据副本)
可用性( A vailability)(每次请求都能获取到服务器非错的响应)
分区容错性( P artition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择)
一般来说P属性都是不可避免的,而S3的做法就是在P的前提下,保证高可用性,根据CAP定理,就会牺牲掉一致性。
当然,CAP定理并不是绝对的,有兴趣的话可以参考一下这篇文章。 https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/
参考资料:
https://docs.aws.amazon.com/AmazonS3/latest/dev/Introduction.html#ConsistencyModel
https://codeburst.io/quick-explanation-of-the-s3-consistency-model-6c9f325e3f82
https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/
Java内存模型
硬件设备
处理器的运算速度很快,但是处理器又要和内存打交道,读取运算数据、存储运算结果的过程很缓慢,此时需要一个高速缓存,运算时将数据复制到缓存中,运算完成后将结果同步会内存,处理器无需等待内存读写加快速度。但是会产生缓存一致性问题,需要依赖一定的协议。“内存模型”可以理解为在特定的协议下,对特定的内存或高速缓存进行读写访问的过程抽象。
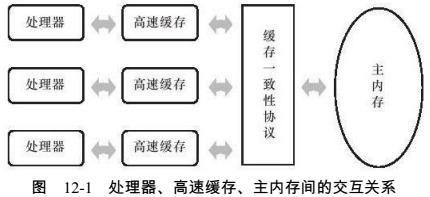
Java内存模型
主内存和工作内存
所有的变量(实例字段、静态字段、构成数组对象的元素)都存储在主内存中(与硬件主内存类比,线程共享,主要对应Java堆中的实例数据)。每条线程都有自己的工作内存(与硬件高速缓存类比,线程不共享,主要对应虚拟机栈中的部分数据),线程的工作内存保存了该线程使用到的变量的主内存副本拷贝,线程对变量的操作(读写、赋值)都在工作内存中进行,不能直接操作主内存的变量,不同线程之间不能互相访问对方工作内存中的变量,只能通过主内存来访问。
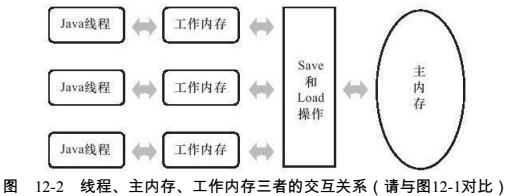
主内存与工作内存之间的交互操作
lock(锁定):作用于主内存的变量,将主内存中的一个变量标志为一条线程独占状态。
unlock(解锁):作用于主内存的变量,将标识为线程独占状态的变量释放出啦,之后才能被其他线程 lock。
read(读取):作用于主内存的变量,将一个变量的值传输到工作内存中,以便 load 操作。
load(载入):作用于工作内存的变量,把 read 操作得到的变量值放入到变量副本中。
use(使用):作用于工作内存的变量,将变量的值传递给执行引擎,虚拟机遇到使用变量的值的字节码指令时执行该操作。
assign(赋值):作用于工作内存的变量,把从执行引擎获得的值赋值给工作内存的变量,虚拟机遇到给变量赋值的字节码指令时执行该操作。
store(存储):作用于工作内存的变量,将变量传送到主内存中,以便 write 操作。
write(写入):作用于主内存的变量,把 store 操作得到的变量值放入到主内存的变量中。
volatile型变量
当一个变量用volatile修饰时,该变量具备两个特性:一是该变量对所有线程可见,二是禁止指令重排序优化(有序性)。
线程可见
对所有线程可见是指一条线程修改了该变量的值,新值对于其他线程可以立即得知。普通变量需要通过主内存和工作内存交互才可见。
volatile修饰的变量的运算在并发下可能是不安全的。
package com.wjz.demo; public class VolatileDemo { public static volatile int val = 0; public static final int THREAD_COUNT = 20; public static void add() { val++; } public static void main(String[] args) { Thread[] ts = new Thread[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; i++) { ts[i] = new Thread(new Runnable() { public void run() { for (int j = 0; j < 10000; j++) { add(); } } }); ts[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); System.out.println(val); } } }
运行结果理论上是200000,但是结果总是小于该数值。
javap查看字节码命令(add方法中的自增运算部分)
0: getstatic #2 // Field val:I 3: iconst_1 4: iadd 5: putstatic #2 // Field val:I
首先getstatic指令将val数值载入操作数栈顶,volatile保证了此时变量值的一致性,执行iconst_1和iadd指令时,其他线程可能已经将val数值增大,此时的val数值是过期的,putstatic指令可能将较小的val数值同步回主内存中了。
volatile型变量的使用场景,可以作为其他线程运行停止的开关。
public static volatile boolean running = true; public void shutdown() { running = false; } public void dowork () { while (running) { // do something } }
禁止指令重排序优化
volatile型变量赋值后多执行一个空操作(store和write),该操作相当于内存屏障,将修改同步到主内存。
long、double型变量
虚拟机会将该类型数据的读写操作作为原子操作对待,一般该类型变量不需volatile修饰。
原子性、可见性和有序性
原子性:
以上是关于对AWS S3数据读写一致性的理解的主要内容,如果未能解决你的问题,请参考以下文章